































































המאמר מבוסס על השתלמות מקצועית בנושא "למידה עמוקה" בת 50 שעות של האיגוד הישראלי למדעני נתונים מקצועיים (PDSIA- Professional Data Scientists' Israel Association) שבמהלכה נלמדים לעומק הסוגים השונים של רשתות נוירונים וכיצד רשתות נוירונים משמשות לפתרון בעיות מיוחדות באמצעות Deep Learning
פורסם: 11.10.20 צילום: shutterstock
למידה עמוקה (Deep Learning) היא תחום הולך וגדל עם יישומים המשתרעים על פני מספר מקרים שימושיים (Use Cases). חשוב ביותר שמדען הנתונים יכיר ויבין את סוגי המודלים השונים המשמשים בלמידה עמוקה, המובססת על רשתות נוירונים.
רשת נוירונים מחקה (רעיונית) את המוח האנושי. באמצעות רשתות נוירונים ניתן לפתור בעיות סבוכות בצורה פשוטה. מדובר במודל הבנוי משכבות של בעיות למידת מכונה (Machine Learning) ומכאן הוא קיבל את השם למידה עמוקה. מודלים אלו יעילים במיוחד כאשר המידע שלנו מבוסס על תמונות או מבני נתונים מורכבים.
במאמר זה אסביר על כל אחד מהמודלים הבאים:
- מודלים של למידה בהשגחה (Supervised Learning Models)
- רשתות נוירונים מלאכותיות/קלאסיות (קולטנים רב-שכבתיים, Multi-layer Perceptrons)
- רשתות נוירונים מפותלות (Convolutional Neural Networks)
- רשתות נוירונים חוזרות (Recurrent Neural Networks)
- מודלים של למידה ללא השגחה (Unsupervised Learning Models)
- מפות ארגון עצמי (רשתות קוהונן, SOM)
- מכונות בולצמן (Boltzmann Machines)
- מקודדים אוטומטיים (AutoEncoders)
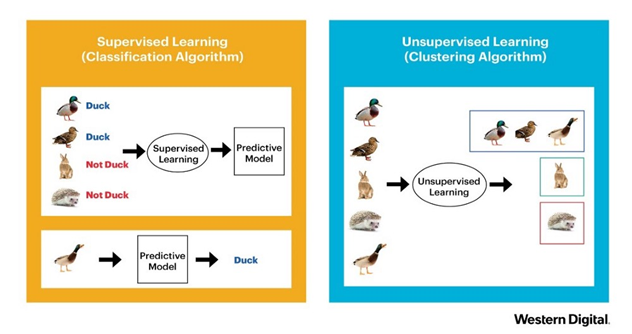
- מודלים של למידה בהשגחה לעומת מודלים של למידה ללא השגחה
קיימות מספר תכונות המבדילות בין מודלים של למידה בהשגחה לעומת מודלים של למידה ללא השגחה, כאשר ההבדל העיקרי הינו באופן אימון (Train, פיתוח) המודלים הללו. בעוד שעל פי רוב מקובל לאמן מודלים של למידה בהשגחה באמצעות דוגמאות של מערך נתונים (Dataset) מסוים הכולל נתוני כניסה (Input Data) ונתוני יציאה (Ouput Data) ברורים, הרי שמודלים של למידה ללא השגחה מקבלים רק נתוני כניסה – מה שאומר שאין להם תוצאה מוגדרת שממנה הם יכולים ללמוד. כך למשל, אותה עמודת Y שתמיד אנו מנסים לחזות/לנבא איננה קיימת במודלים של למידה ללא השגחה. בעוד שלמודלים של למידה בהשגחה ישנן משימות כמו חיזוי (Regression, ניבוי) וסיווג (Classification, קלסיפיקציה) והם יפיקו או ייצרו לנו נוסחה מתמטית, הרי שלמודלים של למידה ללא השגחה ישנן משימות כמו ניתוח אשכולות (Cluster Analysis, מיפוי/פירוק לקבוצות הגיוניות) ולמידת חוקיות אסוציאטיבית (Association Rule Learning, גילוי יחסים מעניינים בין משתנים במאגרי מידע גדולים).
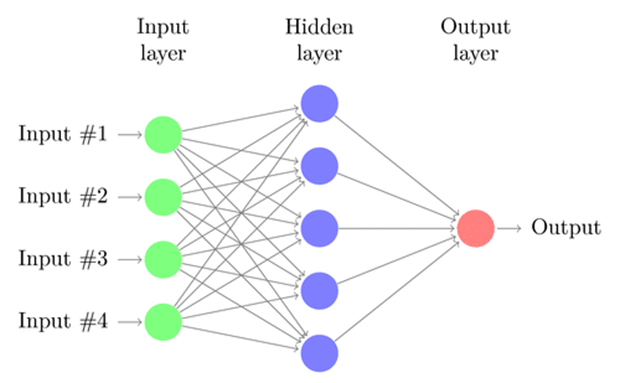
- רשתות נוירונים מלאכותיות/קלאסיות (Classic Neural Networks)
רשתות נוירונים מלאכותיות/קלאסיות (Artificial Neural Networks או ANN) מכונות גם קולטנים רב-שכבתיים (Multi-layer Perceptrons או MLP). מודל הקולטן הרב-שכבתי נוצר בשנת 1958 על ידי הפסיכולוג האמריקאי פרנק רוזנבלט. אופיו הייחודי של המודל מאפשר לו להסתגל לתבניות בינאריות בסיסיות באמצעות סדרת נתוני כניסה, באופן המדמה את דפוסי הלמידה של מוח אנושי. הקולטן הרב-שכבתי הינו למעשה מודל רשת הנוירונים הקלאסי המורכב מיותר משתי שכבות (שכבת כניסה ושכבת יציאה).
הערה אינפורמטיבית: למי שמכיר את מודל הרגרסיה הלינארית (הפשוטה או המרובה) ו/או את מודל הרגרסיה הלוגיסטית, הרי מודל הרגרסיה הלינארית שקול אפקטיבית, מכל הבחינות האקונומטריות/הסטטיסטיות המהותיות, לרשת נוירונים עם שכבה אחת (שהיא גם שכבת כניסה וגם שכבת יציאה) בעלת נוירון אחד עם פונקציית אקטיבציה מסוג Linear (פונקציה ליניארית, (Identity Function. הוא הדין לגבי מודל הרגרסיה הלוגיסטית רק עם פונקציית אקטיבציה מסוג Sigmoid (פונקציית סיגמואיד, Softmax Function).
מקובל לעשות שימוש ברשתות נוירונים מלאכותיות/קלאסיות כאשר מדובר במערך נתונים טבלאי המעוצב בשורות ועמודות (קבצי CSV או XLS), לחילופין כאשר מדובר בבעיות חיזוי וסיווג שבהן מערך נתונים של ערכים אמיתיים משמש כנתוני כניסה או לחילופי חילופין כאשר נדרשת גמישות גבוהה יותר של המודל ואז ניתן להפעיל ANN על סוגים שונים של נתונים.
- רשתות נוירונים מפותלות (Convolutional Neural Networks)
רשתות נוירונים מפותלות (Convolutional Neural Networks או CNN) הינן למעשה וריאציה מתקדמת יותר של רשתות נוירונים מלאכותיות/קלאסיות. רשת נוירונים מפותלת נועדה לטפל בכמות גדולה יותר של מורכבות (שלא לומר סיבוכיות) סביב העיבוד-המקדים של הנתונים (Data Preprocessing) וחישוב הנתונים.
רשתות נוירונים מפותלות נועדו עבור נתוני תמונות (Image Data) והן עשויות להיות המודל היעיל והגמיש ביותר לטיפול בבעיות של סיווג תמונות (Image Classification). למרות שרשתות נוירונים מפותלות לא נבנו במיוחד לעבודה עם נתונים שאינם תמונות, הן עדיין יכולות להשיג תוצאות מדהימות גם עם נתונים שאינם תמונות.
*הערה אינפורמטיבית: מבחינה מתמטית/סטטיסטית, קונבולוציה הינה מכפלה של 2 פונקציות. כך למשל, בשוק ההון מנהלי תיקים מחשבים את תוחלת התשואה של תיק השקעות המורכב ממספר נכסים על ידי הכפלת המשקל היחסי של כל אחד מהנכסים המרכיבים את תיק ההשקעות, בתשואה בפועל שהורווחה עליו. לפיכך, תוחלת התשואה של תיק השקעות הינה קונבולוציה (הווה אומר- מכפלה) של פונקציית המשקלים של הנכסים ופונקציית התשואות של הנכסים. בעולם הביטוח הכללי כאשר רוצים לחזות את ההפסד הצפוי לחברת ביטוח נניח מגניבות של מכוניות סובארו, מבצעים קונבולוציה בין התפלגות השכיחות של גניבות סובארו לבין התפלגות החומרה של גניבות סובארו. הסבר מלא על קונבולוציה חורג ממסגרת מאמר זה. המחשה ברורה של השימוש בקונבולוציה ניתן למצוא במאמרם של נאור ופולניצר (2018), "אקטואריית סיכונים תפעוליים או אקטואריית סיכונים אלמנטריים?", סטטוס – כתב עת לחשיבה ניהולית ואסטרטגית, יולי.
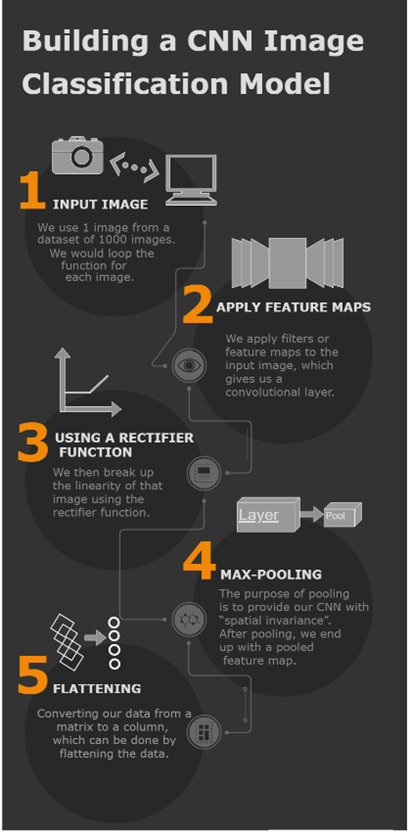
משעה שביצענו ייבוא של נתוני הכניסה שלנו לתוך המודל, לצורך בניית רשת נוירונים מפותלת נדרשים 4 שלבים:
- קונבולוציה (Convolution): התהליך בו נוצרות מפות של מאפיינים (Features, משתנים מסבירים) מתוך נתוני הכניסה שלנו. לאחר מכן מופעלת פונקציה לסינון המפות.
- Max-Pooling: פעולה המאפשרת לרשת הנוירונים המופתלת שלנו לזהות תמונה כשהיא מוצגת עם שינוי.
- השטחה (Flattening): השטחת הנתונים לכדי מערך נתונים על מנת שרשת הנוירונים המופתלת שלנו תוכל לקרוא אותו.
- חיבור מלא: השכבה הנסתרת, המחשבת גם את פונקציית ההפסד (Loss Function) עבור המודל שלנו.
מקובל לעשות שימוש ברשתות נוירונים מפותלות כאשר מדובר במערכי נתונים של תמונות (כולל ניתוח מסמכים באמצעות זיהוי תווים אופטי – OCR), לחילופין כאשר נתוני הכניסה הינם שדה דו-מימדי אך ניתן להמיר אותם לשדה חד-מימדי לטובת עיבוד מהיר יותר או לחילופי חילופין כאשר המודל דורש מורכבות רבה יותר בעת חישוב משתנה היציאה.
- רשתות נוירונים חוזרות (Recurrent Neural Networks)
רשתות נוירונים חוזרות (Recurrent Neural Networks או RNN) פותחו על מנת לשמש לניבוי רצפים (Sequences). אלגוריתם ה- LSTM (זיכרון ארוך לטווח קצר, Long Short-Term Memory) הוא אחד האלגוריתמים הפופולריים של רשתות נוירונים חוזרות עם מקרים שימושיים רבים:
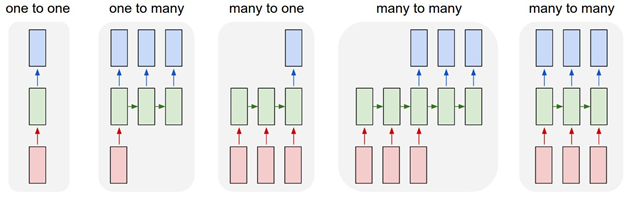
מקובל לעשות שימוש ברשתות נוירונים חוזרות כאשר מדובר במשתנה כניסה בודד הממופה למשתנה יציאה בודד (מה שנקרא One-to-One למשל לצורך סיווג תמונות), לחילופין כאשר מדובר במשתנה כניסה בודד הממופה לרצף משתני יציאה (מה שנקרא One-to-Many, למשל התמרת תמונה אחת לכדי מספר מילים), לחילופי חילופין כאשר מדובר ברצף משתני כניסה המייצרים משתנה יציאה בודד (מה מה שנקרא Many-to-One, למשל לצורך ניתוח רגש ממספר מילים למשתנה יציאה בינארי יחיד) או לחילופי חילופי חילופין כאשר מדובר ברצף משתני כניסה המייצרים רצף של משתני יציאה (מה שנקרא Many-to-Many, למשל סיווג וידאו על ידי פיצול הוידאו לפריימים ותיוג כל אחד מפריימים בנפרד).
- מפות ארגון עצמי (Self-Organizing Maps)
מפות ארגון עצמי או SOMs עובדות עם נתונים ללא השגחה ועל פי רוב הן מסייעות בצמצום מימדים (מפחיתות את כמות המשתנים המקריים במודל). עבור מפת ארגון עצמי המימד של משתני היציאה הינו תמיד דו-מימדי, כך שבמידה ויש לנו יותר משני מאפיינים, מימד משתני היציאה שלנו תמיד יצטמצם ל- 2 מימדים. לכל סינפסה (Synapse) המחברת בין צמתי כניסה ויציאה ישנו משקל המוקצה לה. לאחר מכן, כל נקודת נתונים מתחרה על ייצוג במודל. הצומת הקרוב ביותר נקרא BMU (יחידת ההתאמה הטובה ביותר, Best Matching Unit), כך שה- SOM מעדכנת את משקליה על מנת להתקרב ל- BMU. שכני ה- BMU ממשיכים לקטון ככל שהמודל מתקדם. ככל שצומת ה- BMU קרובה יותר, כך המשקלים שלה ישתנו יותר.
הערה אינפורמטיבית: המשקלים הינם מאפיין של הצומת עצמה והם מייצגים את מיקום הצומת במרחב נתוני הכניסה. למעשה בשונה מה- ANN ב- SOMs אין פונקציית אקטיבציה.
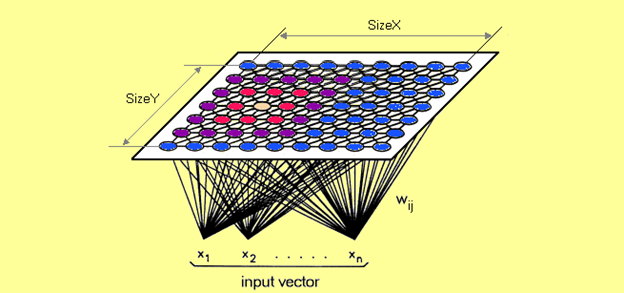
מקובל לעשות שימוש במפות ארגון עצמי כאשר הנתונים המסופקים אינם מכילים נתוני יציאה או עמודה Y בסיווג/חיזוי, לחילופין בפרויקטים של חקר על מנת להבין את מסגרת העבודה שעמודת מאחורי מערך הנתונים, לחילופי חילופין כאשר מדובר בפרויקטים יצירתיים (מוזיקה/טקסט/וידאו המופקים באמצעות בינה מלאכותית) או לחילופי חילופי חילופין כאשר מדובר בצמצום מימדים (Dimensionality Reduction) לצורך זיהוי מאפיינים.
- מכונות בולצמן (Boltzmann Machines)
לארבעת המודלים שהוצגו עד כה ישנו דבר אחד במשותף – כולם עובדים בכיוון מסוים. למרות ש- SOMs אינם מודלים של למידה בהשגחה, הם עדיין עובדים בכיוון מסוים ממש כמו מודלים של למידה בהשגחה. באומרי "בכיוון מסוים" אני מתכוון לכך שהארכיטקרטורה של רשת הנוירונים הינה בגדול כדלקמן:
שכבת כניסה ← שכבה נסתרת ← שכבת יציאה.
מכונות בולצמן אינןן עובדות בכיוון מסוים, היות וכל הצמתים מחוברים זה לזה בצורה מעגלית של היפר-מרחב ממש כמו בתמונה. מכונת בולצמן יכולה גם לייצר את כל הפרמטרים של המודל, במקום לעבוד עם משתני כניסה קבועים. מודל כזה מכונה מודל סטוכסטי (כלומר, מודל בעל אופי משתנה/לא וודאי) והוא שונה מכל המודלים הדטרמיניסטיים (כלומר, מודלים בעלי אופי קבוע/וודאי) שהוצגו עד כה.
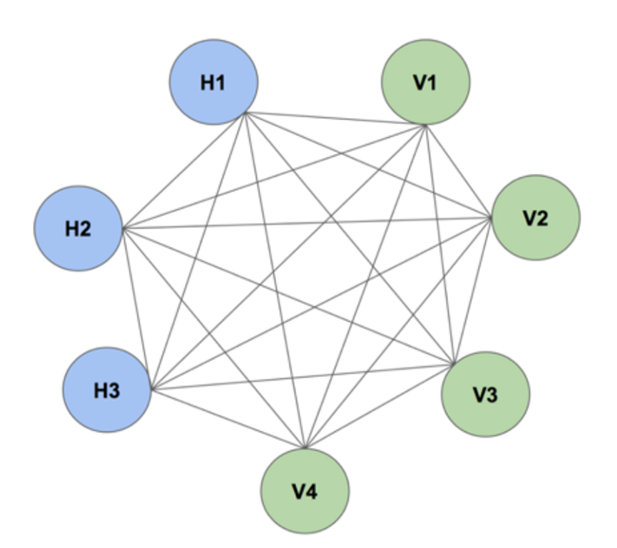
מקובל לעשות שימוש במכונות בולצמן לצורך ניטור מערכת (שכן מכונת הבולצמן יכולה ללמוד לווסת), לחילופין לצורך בניית מערכות המלצה (Recommender systems) או לחילופי חילופין לצורך עבודה עם מערך נתונים מאוד ספציפי.
- מקודדים אוטומטיים (AutoEncoders)
מקודדים אוטומטיים כשמם כך הם, מקודדים אוטומטית את הנתונים על בסיס משתני הכניסה, לאחר מכן הם מיישמים על משתני הכניסה פונקציית אקטיבציה מסויימת ולבסוף הם מפצחים (Decode, מפענחים) את הנתונים לכדי משתני יציאה. הרעיון שעומד מאחורי המקודדים האוטומטיים הוא שקיים צוואר בקבוק מסוים אשר מופעל על מאפייני הכניסה ודוחס אותם לפחות קטגוריות. לפיכך, אם קיים מבנה אינהרנטי בתוך הנתונים, מודל המקודד האוטומטי יזהה אותו וימנף אותו על מנת לקבל את משתני היציאה.
קיימים מספר סוגים של מקודדים אוטומטיים. הסוג הראשון של מכונה מקודדים אוטומטיים דלילים (Sparse AutoEncoders) ומה שמאפיין אותם הוא שבארכיטקטורות אלו השכבה הנסתרת גדולה יותר משכבת הכניסה אך מיושמת טכניקת רגולריזציה (רגולריזציה הינה דרך להימנע מהתאמת יתר ולצמצם את מספר המאפיינים) לצורך הקטנת התאמת יתר (Over-fitting, בעיה שבה האלגוריתם לומד טוב מדי את הדוגמאות של מערך נתוני האימון, אך לא נותן תחזיות נכונות למערך נתוני הבדיקה בנפרד). נציין כי הוספת אילוץ לפונקציית ההפסד, מונעת מהמקודד האוטומטי לעשות שימוש בכל הצמתים בו זמנית.
הסוג השני של מכונה מקודדים אוטומטיים מסנני רעשים (Denoising AutoEncoders) ומה שמאפיין אותם הוא שמדובר למעשה בטכניקת רגולריזציה נוספת שבה אנו לוקחים גרסה שונה של משתני הכניסה שלנו כאשר חלק ממשתני הכניסה שלנו הוסבו לאפס באופן אקראי.
הסוג השלישי מכונה מקודדים אוטומטיים מכווצים (Contractive AutoEncoders) ומה שמאפיין אותם הוא שלמעשה מדובר בהוספת "קנס" לפונקציית ההפסד על מנת למנוע התאמת יתר והעתקה של ערכים כאשר השכבה הנסתרת גדולה משכבת הכניסה.
הסוג הרביעי מכונה מקודדים אוטומטיים מוערמים (Stacked AutoEncoders). ומה שמאפיין אותם הוא שכאשר מוסיפים שכבה נסתרת נוספת, מקבלים מקודד אוטומטי מוערם שלו שני שלבי קידוד ושלב אחד של פיצוח.
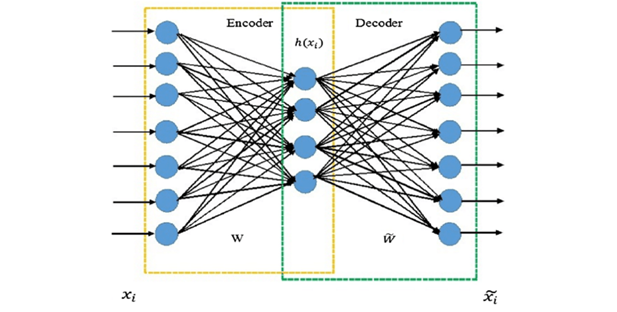
מקובל לעשות שימוש במקודדים אוטומטיים לצורך צמצום מימדים/זיהוי מאפיינים, לחילופין לצורך בניית מערכות המלצה (Recommender systems) חזקות הרבה יותר מאלו של מכונת בולצמן או לחילופי חילופין לצורך קידוד מאפיינים במערכי נתוני עתק (Big Data).


מר פולניצר הינו מדען הנתונים הראשי של משרד הייעוץ הסטטיסטי "רועי פולניצר – פרדיקציות יועצים". רועי אחראי במשרד על תרגום הדרישות העסקיות של הלקוחות לכדי פתרון טכני ואנליטי, כלומר, על פיתוח ובדיקת האיכות של מודלים המפותחים על גבי תשתיות הBig Data – החל משלב בחירת הגישה האנליטית / פתרון אלגוריתמי ועד לבחינת איכות תוצרי המודלים אל מול ה KPI שהוגדרו ע"י הלקוח.
לרועי 10 שנות ניסיון והתמחות מעשית בפיתוח Machine learning models בשפות R, Python ו- Pyspark
כפתרונות אנליטיים מתקדמים לבעיות עסקיות מורכבות בתחומי השיווק, המכירות, ה- Cyber, התפעול, הרגולציה ועוד, תוך התאמת הפתרונות הטכנולוגיים הן בתהליכי Batch והן בתהליכי Real Time.
לרועי מיומנות גבוהה הן במודלי Unsupervised ML כולל Cluster Analysis ,K-means ,KNN ,Principal Component Analysis (בייחוד באלגוריתמים לאיתור אנומליות, כדוגמת LOF ,Isolation Forest), הן במודלי Supervised ML כולל Decision Trees ,Random Forest ,Naïve Bayes ,SVM ,XGBoost וכו' והן בפיתוח מודלים באמצעות Deep Learning. לרועי בקיאות בחבילות הפיתוח Scikit-learn ,TensorFlow ,Pyspark ,MLlib ו- Pandas, ניסיון הן בבניית מודלי Data (פאנלי נתונים) ויכולות גבוהות של ניתוח מידע בשפות שונות (לרבות בשפת SQL), הן בעבודה מול מאגרי מידע גדולים בסביבת Big Data Hortonworks Cloudera (Spark ,MapRedue ו- Hadoop) והן עבודה מול כלים ותשתיות Data בענן ( Azure ,AWSו- IBM Cloud) ובסביבת H2Oוכמובן התנסות מעמיקה בניתוח נתונים ובניית מודלים סטטיסטיים.

"רועי פולניצר – פרדיקציות יועצים" הינו משרד ייעוץ סטטיסטי המספק פתרונות מדעיים לאתגרים הכרוכים בעבודה עם כמויות גדולות ומגוונות של נתונים, ביצוע מחקרים להפקת תובנות עסקיות מנתונים עבור ארגונים (Business Intelligence), טיוב וסידור מידע המשמש למחקרים והפעלת אלגוריתמים ומודלים שונים של כריית נתונים ושל Machine Learning על מידע.
מגזין "סטטוס" מופק ע"י:
Tags: טכנולוגיה מדעני נתונים ניהול ידע סטטיסטיקה


