





























































רגרסיה לינארית היא כלי מאוד פופולרי והיא אחד מהאלגוריתמים שמאפיינים למידה בהשגחה (Supervised Learning). משעה שהנחנו שהמודל שלנו הוא לינארי הרי שאיננו זקוקים עוד לכמות אדירה של נתונים
פורסם: 25.11.19 צילום: shutterstock
מאמר מס' 4 בסדרה
הקדמה
סדרת מאמרים זו מבוססת על נסיוני כמדען נתונים (Data Scientist) המתמחה בתחום למידת המכונה (ML- Machine Learning) בעולמות המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה.
חלק מהאלגוריתמים של ML למדתי בתואר הראשון שלי בכלכלה (כגון: הטיה מול שונות, בעיות רגרסיה מול בעיות סיווג, חלוקת נתונים ל- Training set ו- Testing set, נרמול נתונים, רגרסיה לינארית, Ridge, Lasso ו- Elastic Net, יישומי אלגברה לינארית בתוכנת Excel וכו'), חלק בקורסים לתואר שני בכלכלה (כגון: Dimensionality Reduction, Principle Components Analysis, K-Mean Cluster Analysis, Hierarchical Cluster Analysis ו- Time Series וכו'), חלק בתואר השני שלי במימון (כגון: Decision Trees, Random Forest, Monte Carlo Simulation, Bootstrapping, Cubic-Spline, Nelson-Siegel-Svensson וכו'), חלק למדתי בלימודי התעודה באקטואריה (המסווג הנאיבי של בייס, Overfitting, ,Underfitting Convolution and Pooling, תכנות מדעי וסטטיסטי בשפת R וכו'), חלק למדתי בלימודי התעודה בניהול סיכונים פיננסיים ועל חלק אף נבחנתי במבחנים הבינלאומיים להסמכה בתחום ניהול הסיכונים הפיננסיים FRM (כגון: רגרסיה לוגיסטית, Logit, Probit,LDA , K-Nearest Neighbor ו- Support Vector Machines וכו') ואת היתר למדתי עצמאית באינטרנט (כגון: Neural Networks, Ensemble, Bagging, Boosting, תכנות בשפת VBA וכו').
כמובן שההבנה העמוקה שלי באלגוריתמים של ML נשענת הן על הידע שלי בסטטיסטיקה (הכולל בין היתר: סוגי נתונים והצגתם באופן טבלאי וגרפי, מדדי מרכוז ומדדי פיזור, אחוזונים, מדדי קשר, התפלגות הנתונים, הסתברות פשוטה במרחב הסתברותי אחיד ובמרחב הסתברותי לא אחיד, הסתברות מותנית, נוסחת בייס, משתנים מקריים בדידים: ניסויי ברנולי, התפלגות בינומית, התפלגות פואסונית, התפלגות גיאומטרית, התפלגות היפרגיאומטרית, משתנים מקריים רציפים: התפלגות נורמלית, הסקה סטטיסטית, אמידה נקודתית, רווחי סמך, מבחני השערות וסטטיסטיקה א-פרמטרית) והן על הידע שלי בתורת הקבוצות (הכולל בין היתר: מערכות משוואות לינאריות, וקטורים ב- R^n, מטריצות ריבועיות, מטריצות אלמנטריות, מרחבים וקטורים, מרחבי מכפלה פנימית, אורתוגנליות, דטרמיננטות, ערכים עצמיים, וקטורים עצמיים, לכסון, תבניות ריבועיות, משוואות הפרשים, תכונות טופולוגיות של קבוצות במרחב אוקלידי, קבוצות קמורות, משפטי הפרדה, פונקציות קמורות וקעורות, תכונות ואפיונים, שנאת סיכון, אופטימיזציה של פונקציות עם ובלי אילוצים, משפט הפונקציות הסתומות, משפט המעטפת, משוואות דיפרנציאליות מסדרים שונים, מערכות של משוואות דיפרנציאליות ושיטות של אופטימיזציה דינאמית).
מטרתה של סדרת מאמרים זו היא להקנות לקורא הבנה מה עושים מדעני נתונים (Data Scientists) נתונים וכיצד הם יכולים לקדם את מטרות הארגון. מרבית אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה מכירים בכך שהם זקוקים לידע מסוים בתחום ה- ML על מנת לשרוד בעולם שבו מספר מקומות העבודה מושפע יותר ויותר מתחום זה. כיום, כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה צריכים לדעת לעשות שימוש בתוכנת Excel ולדעת לתכנת ברמה מסוימת ב- VBA. מחר כבר כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה יצטרכו לדעת לעבוד עם מאגרי נתונים גדולים (Big Data) תוך פיתוח ושימוש באלגוריתמים של ML על מנת לזהות כיוונים ומגמות בעולמי התוכן שלהם או במגוון תחומים לרוחב הארגון.
בסדרת מאמרים זו חסכתי מהקורא את השימוש בתורת הקבוצות (קרי, מטריצות ווקטורים), למרות שלעניות דעתי אלגברה לינארית חיונית ביותר על מנת להגיע להבנה עמוקה ולשליטה ברמה גבוהה ב- ML.
לסיכום, סדרת מאמרים זו מציגה את הכלים, המודלים והאלגוריתמים הפופולריים ביותר שבהם משתמשים כיום מדעני נתונים.
- סיכום המאמר הקודם: למידה ללא השגחה (Unsupervised Learning)
למידת ללא השגחה עוסקת בהבנת דפוסים בתוך נתונים. באופן טבעי למידה ללא השגחה כרוכה בהתבוננות על אשכולות (Clusters), הווה אומר, על קבוצות של תצפיות דומות. לעיתים קרובות חברות עושות שימוש בלמידה ללא השגחה על מנת לנסות ולהבין טוב יותר את סוגי הלקוחות שלהן כך שהן תוכלנה לתקשר עמם בצורה יעילה יותר.
ביצוע קליברציה לערכי המאפיינים (Feature Scaling) הינו שלב מקדים (Precursor) לשלב ניתוח האשכולות (Clustering). ללא ביצוע קליברציה לערכי המאפיינים, השפעתו של מאפיין מסוים על ניתוח אשכולות תהיה בקנה המידה (Scale) אשר משמש למדידתו.
קיימות שתי גישות עיקריות לביצוע קליברציה לערכי המאפיינים. הגישה הראשונה נקראת קליברציה מסוג Z-score ובמסגרתה ערכי המאפיינים מותאמים כך שבסופו של דבר תהיה להם תוחלת של 0 וסטיית תקן של 1. הגישה השניה נקראת קליברציה מסוג Min-Max ובמסגרתה ערכי המאפיינים מותאמים כך שבסופו של דבר הם ינועו בין 0 ל- 1.
אלגוריתם ניתוח אשכולות דורש לדעת למדוד מרחקים (משהו שלמדנו מתישהו בתיכון). המדד הפופולארי ביותר עבור מרחק נקרא המרחק האוקלידי (Euclidian Distance) והוא מחושב כשורש הריבועי של סכום ריבועי ההפרשים שבין ערכי המאפיינים. מרכז הכובד של האשכול הינו נקודה המתקבלת על ידי מיצוע ערכי המאפיינים עבור כל התצפיות באשכול. אלגוריתם ניתוח האשכולות הפופולארי ביותר נקרא k-מרכזים (k-means). עבור ערך מסוים של k (מספר האשכולות), אלגוריתם ה- k-מרכזים ממזער את האינרציה (Inertia), המוגדרת כסכום ריבועי המרחקים בתוך האשכול בין התצפיות לבין מרכזי הכובד של האשכולות שלהן.
בחירת הערך הטוב ביותר עבור מספר האשכולות, k, איננה משימה קלה. גישה אחת לבחירת ה- k נקראת "שיטת המפרק" (Elbow Method) הגורסתת שיש להמשיך ולהעלות את ה- k עד להגעה לשיפור זניח יחסית באינרציה. גישה אחרת נקראת "שיטת הצללית" (Silhouette Method) והיא עורכת השוואה בין המרחק הממוצע של תצפית מסוימת מהנקודות האחרות באשכול שלה לבין המרחק הממוצע שלה מהנקודות באשכול האחר הקרוב ביותר. הגישה השלישית כרוכה בחישוב סטטיסטי הפער, אשר משווה את התצפיות שבתוך האשכולות (Clustered Observations) לתצפיות הנוצרות באופן אקראי.
ישנן מספר חלופות לאלגוריתם k-מרכזים. החלופה הראשונה נקראת ניתוח אשכולות היררכי (Hierarchical Clustering). בניתוח אשכולות היררכי אנו מתחילים ממצב שבו כל אחת מהתצפיות נמצאת באשכול שלה. לאחר מכן אנו מורידים באיטיות את מספר האשכולות על ידי צירוף אשכולות שקרובים אחת לשני לכדי אשכולות חדשים. החלופה השניה נקראת ניתוח אשכולות מבוסס-התפלגות (Distribution-based Clustering) והיא כרוכה בהתבוננות על אזורים שבהם הנתונים צפופים/דחוסים ללא קשר למרכזי הכובד של האשכולות.
ניתוח מרכיבים עיקריים (PCA- Principal Components Analysis) הוא כלי חשוב בלמידת מכונה. ניתוח מרכיבים עיקריים כרוך בהחלפת מספר גדול של מאפיינים במספר קטן יותר של מאפיינים המכונים "המאפיינים המסבירים ביותר" (Manufactured Features) אשר תופסים את מרבית ההשתנות של היעד (Target Variability, השתנות המשתנה המוסבר). נעיר רק שהמאפיינים המסבירים ביותר אינם מתואמים האחד עם השני.
- רגרסיה לינארית
אחד הנושאים המורכבים שמעסיקים מומחים רבים מתחום הסטטיסטיקה והאקונומטריקה הוא מודל רגרסיה לינארית. השימוש ברגרסיה לינארית נפוץ ביותר, וזאת ללא הבנה מספקת של האפקטים השונים הפועלים "מאחורי הקלעים" של המודל. טעויות רבות בשימוש במודל רגרסיה נובעות מאי-הכרת ההנחות העומדות בבסיסו.
במודל רגרסיה ההנחה היא שהמשתנה המוסבר הינו פונקציה ליניארית של המשתנה המסביר. כלומר, הצורה הבסיסית של מודל רגרסיה בעל משתנה מסביר אחד x ומשתנה מוסבר y הינה:

במשפחת המודלים מסוג רגרסיה ליניארית נכללים גם מודלים מורכבים יותר, שלפיהם המשתנה המסביר y הוא פונקציה לינארית של יותר ממשתנה מסביר אחד. לדוגמא, תשואת תיק מניות המכיל גם מניות הנסחרות בשוק זר, יכולה להיות מוסברת בעזרת שלושה משתנים מסבירים: האחד, תשואת תיק השוק המקומי; השני, תשואת תיק השוק הזר; והשלישי, שער חליפין בין המטבע המקומי לבין המטבע הזר.


- למידה בהשגחה באמצעות רגרסיה לינארית
רגרסיה לינארית היא כלי מאוד פופולרי והיא אחד מהאלגוריתמים שמאפיינים למידה בהשגחה (Supervised Learning). משעה שהנחנו שהמודל שלנו הוא לינארי הרי שאיננו זקוקים עוד לכמות אדירה של נתונים.
בלמידת מכונה אנו משתמשים בטרמינולוגיה אחרת מזו המשמשת בסטטיסטיקה/אקונומטריקה. כך למשל, בלמידת מכונה האיבר החותך (constant term, הגודל הקבוע) מכונה ה- Bias, השיפועים (Coefficients, מקדמי הרגרסיה) מכונים ה- Weights, המשתנים המסבירים מכונים ה- Features והמשתנה המוסבר מכונה ה- Target.
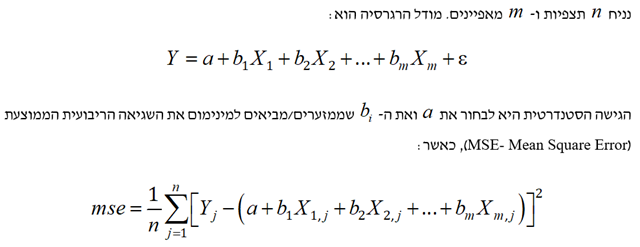
לבעיית מזעור ה- mse יש פתרון אנליטי הכרוך בהיפוך מטריצה (inverting a matrix). כאשר מספר המאפיינים גדול מאוד ייתכן ויהיה יעיל יותר, מבחינה חישובית כמובן, לעשות שימוש בשיטות נומריות כמו למשל שיטת מורד הגרדיאנט (Gradient Descent).
שיטת מורד הגרדיאנט מאפשרת לנו למצוא את הכיוון שבו נמצא השינוי הדרסטי ביותר בין הנתונים סביב נקודה מסוימת. הגרדיאנט מהווה את הכיוון שבו שיפוע המדרון הינו מקסימלי, והאלגוריתם מוצא את הדרך האופטימלית להביא למינימום את פונקציית המטרה.
לאמור- בשיטת מורד הגרדיאנט המטרה היא למזער/להביא למינימום את הפונקציה על ידי שינוי פרמטרים, באמצעות השלבים הבאים: 1) בחירת ערך התחלתי עבור הפרמטרים; 2) מציאת השיפוע התלול ביותר: כלומר, את הכיוון שבו על הפרמטרים להשתנות על מנת להקטין את פונקציית המטרה. השיטה עובדת כך שבכל שלב של ההפעלה היא מתקדמת לכיוון ההפוך לגרדיאנט (כיוון שהגרדיאנט מראה את השיפוע המקסימלי) כך שבכל שלב יש התקדמות נגד השיפוע המקסימלי עד שמגיעים לנקודה מספיק נמוכה המוגדרת בתנאי העצירה. דבר זה דומה לאדם העומד בנקודה כלשהי על המפה הטופוגרפית אך ישנו ערפל סמיך אשר עוצר בעדו. לכן באפשרותו לבדוק רק בסביבה הקרובה לו היכן הזווית הכי תלולה של המדרון מצויה ודרכה הוא יורד.
- מאפיינים קטגוריים (Categorical Features)
מאפיינים קטגוריים הינם מאפיינים שעבורם קיימות מספר אלטרנטיבות שאינן נומריות. ניתן להגדיר משתנה לכל אחת מהאלטרנטיבות. המשתנה שווה ל- 1 אם האלטרנטיבה היא נכונה ו- 0 אם אחרת. ברם, לעיתים אין אנו חייבים לעשות זאת מאחר וקיים סדר טבעי (Natural Ordering) משהו של משתנים, למשל: קטן = 1, בינוני = 2, גדול = 3 או לחילופין מרצה בכיר = 1, פרופסור חבר = 2, פרופסור מן המניין = 3.
- רגולריזציה (Regularization)
רגרסיה לינארית יכולה להתאים יתר על המידה (Overfits, כלומר האלגוריתם לומד טוב מדי את הדוגמאות של סט האימון אך לא נותן תחזיות נכונות עבור הדוגמאות של סט הבדיקה בנפרד), במיוחד כאשר קיים מספר רב של מאפיינים המתואמים אחד עם השני, ייתכן שהתוצאות עבור סט התיקוף לא יהיו טובות כמו אלו עבור סט האימון. רגולריזציה היא דרך להימנע מהתאמת יתר (Overfitting) ולצמצם את מספר המאפיינים. קיימות 3 אלטרנטיבות לרגולריזציה: Ridge, Lasso ו- Elastic net. נעיר רק שלפני כן עלינו לבצע קליברציה לערכי המאפיינים, כפי שהסברנו במאמר הקודם (קליברציה בשיטת ה- Z-score או קליברציה בשיטת ה- Min-Max).
- רגרסיות מסוג Ridge, Lasso ו- Elastic Net
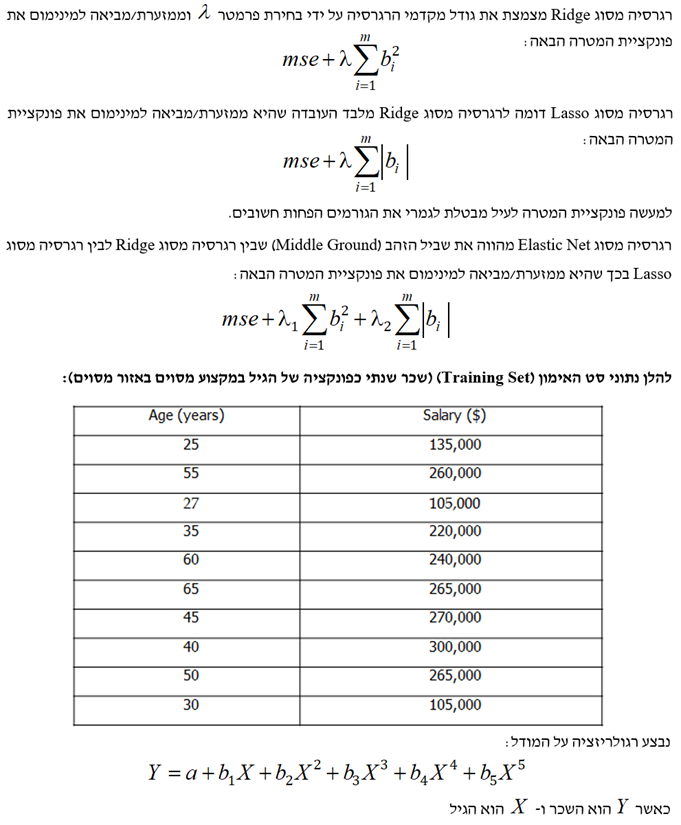
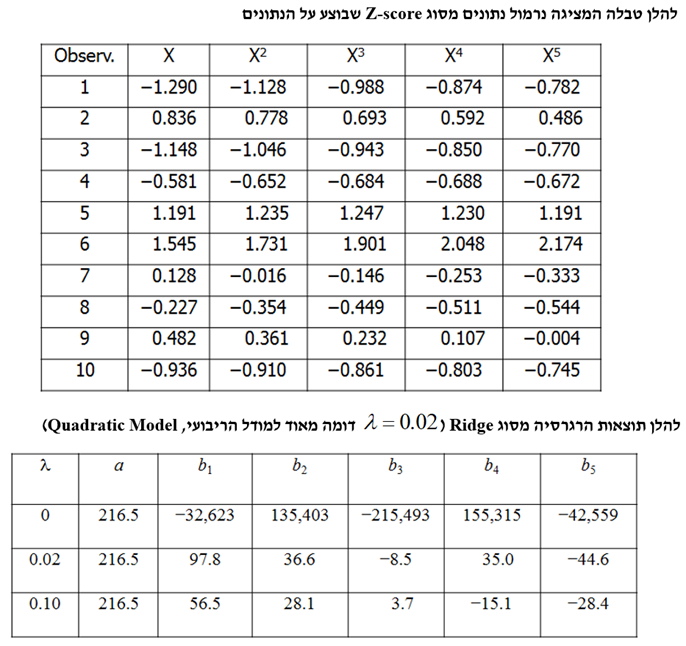
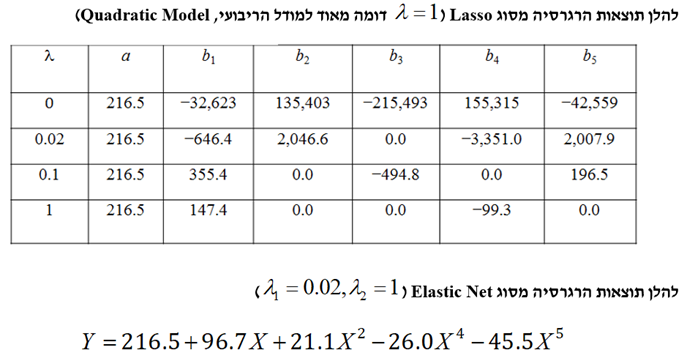
- מקרה מבחן של מחירי הבתים בניו הייבן קונטיקט
המטרה היא לחזות את מחירי בתים בעיר ניו הייבן במדינת קונטיקט בארה"ב מתוך מאפיינים כלשהם, כאשר סט האימון (Training Set) מונה 800 תצפיות, סט התיקוף (Validation Set) מונה 600 תצפיות וסט הבדיקה (Test Set) מונה 508 תצפיות.
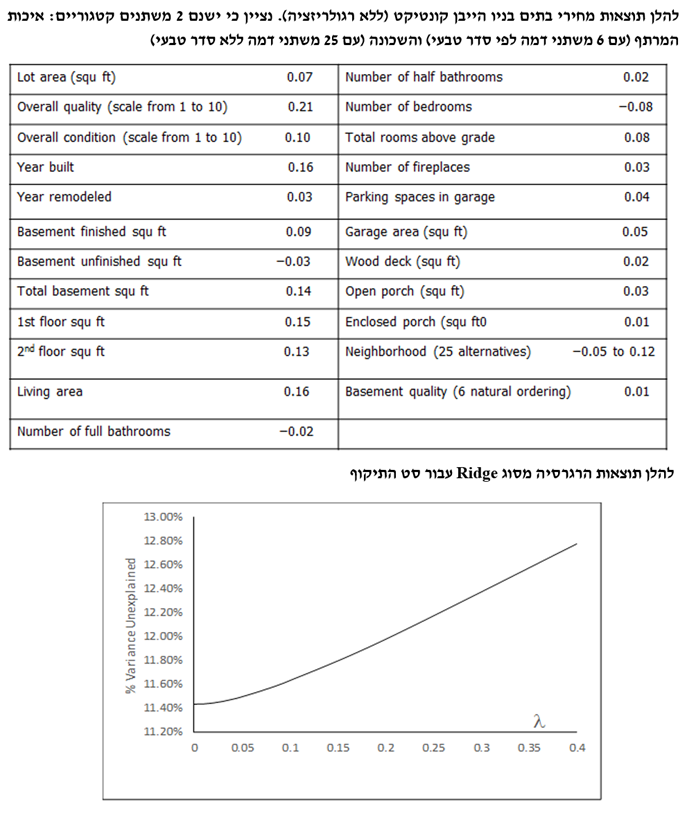
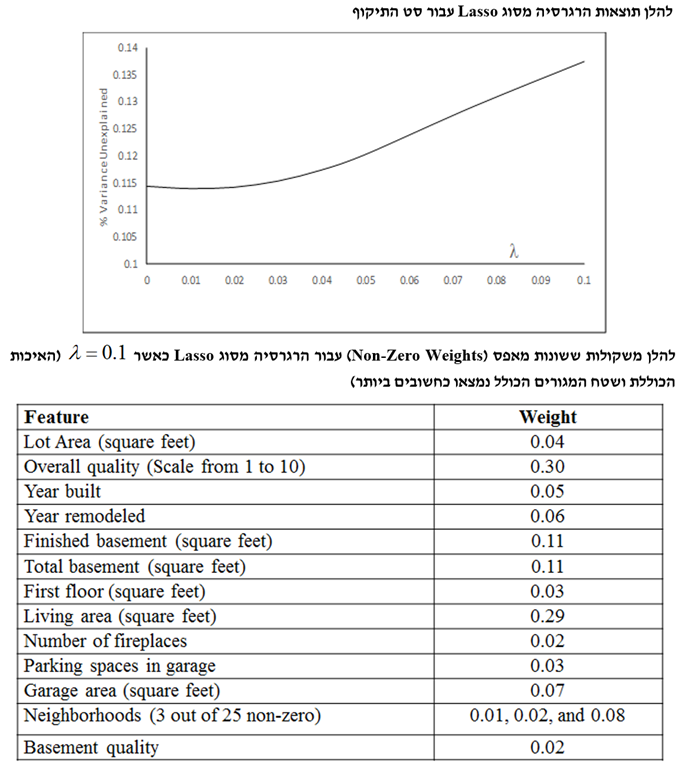
לסיכום מקרה המבחן של מחירי בתים בניו הייבן קונטיקט, ניתן לומר שללא רגולריזציה המתאם (Correlation) בין המאפיינים מוביל לכמה משקולות שליליות אשר היינו מצפים שתהיינה חיוביות. השיפורים העולים מהרגרסיה מסוג Ridge הינם מועטים למדי, מאידך הרגרסיה מסוג Lasso מביאה לשיפור די גדול. הוא הדין לגבי הרגרסיה מסוג Elastic Net. לבסוף, השגיאה הריבועית הממוצעת (MSE) עבור סט האימון ורגרסיה מסוג Lasso עם 0.1 = λ היא 14.4%, כך שרק 85.6% מהשונות מוסברים.
- לסיכום
רגרסיה לינארית היא בוודאי לא טכניקה חדשה של למידת מכונה. למעשה היא משחקת תפקיד מרכזי במחקר האמפירי מזה שנים רבות. מדעני נתונים (Data Scientists) אימצו את הרגרסיה הלינארית ככלי לניבוי/חיזוי.
ליישומים של למידת מכונה לעיתים קרובות ישנם מאפיינים רבים, אשר חלקם מתואמים מאוד (Highly Correlated) האחד עם השני. במקרה שכזה רגרסיה לינארית מהימנה תייצר תוצאה שתספק מקדם חיובי גבוה לערכים עבור מאפיין מתואם אחד ומקדם שלילי גבוה לערכים עבור מאפיין מתואם אחר.
אחת הגישות להקטנת המשקולות של המאפיינים במודל הרגרסיה נקראת רגרסיה מסוג Ridge. גישה אחרת נקראת רגרסיה מסוג Lasso. לרגרסיה מסוג Lasso ישנה השפעה של צמצום לאפס של המשקולות של המאפיינים הלא חשובים. גישה נוספת נקראת רגרסיה מסוג Elastic Net והיא עושה שימוש ברעיונות שעומדים בבסיסן של הרגרסיות מסוג Ridge ו- Lasso. למעשה, רגרסיה מסוג Elastic Net יכולה לשמש להשגת היתרונות של שתי הרגרסיות הללו (קרי, משקולות שקטנות יותר בגודלן כמו גם השמטה של מאפיינים לא חשובים).
ניתן להכניס משתנים קטגוריים (Categorical Variables) לרגרסיה לינארית באמצעות יצירת משתנה דמה (Dummy Variable), אחד לכל קטגוריה. משתנה הדמה עבור תצפית מסוימת נקבע כשווה ל- 1 אם התצפית 'נופלת' באותה קטגוריה ו- 0 אם לאו.
"מדען נתונים הוא אחד שגם טוב יותר בסטטיסטיקה ואקונומטריקה מכל בוגר מדעי המחשב או מהנדס תוכנה וגם טוב יותר בהנדסת תוכנה מכל סטטיסטיקאי או כלכלן", רועי פולניצר, אקטואר ומעריך שווי, 2019.

רועי הינו מדען נתונים (Data Scientist) העושה שימוש ב- Machine Learning לצורך פיתוח מודלים מתקדמים לניהול סיכונים (בדגש על אשראי קמעונאי) כגון מודלים מנבאי התנהגות לקוחות ו/או מודלי תחזיות בתחום ניהול הסיכונים, שיפור מודלים בתחום ניהול הסיכונים, ניתוח צרכים עסקיים בעולמות ניהול הסיכונים, אפיון פתרונות מתאימים באמצעות עבודה מול בסיס נתונים גדולים ויישום כלים אנליטיים מתקדמים בעולם הבינה המלאכותית, הערכת סיכוני מודל וניטור פעולות מתקנות, ניתוח ועיבוד גורמי סיכון עיקריים, וניתוח הבדלים בין חלופות ואיפיון גורמי סיכון.
ניסיונו של רועי בתחום ה- Data Analysis, כולל: עבודה עם מאגרי מידע גדולים Big Data תוך שימוש ב- Statistical Learning (כגון: סטטיסטיקה תיאורית, הסתברות, הסקה סטטיסטית, סטטיסטיקה א-פרמטרית, חלוקת נתונים, נרמול נתונים, Fitting ו- Bayes Theorem) ובאלגוריתמים מסוג Unsupervised Learning (כגון: k-means Clustering, Hierarchical Clustering, Density-based Clustering, Distribution-based Clustering ו- Principle Components Analysis) למציאת דפוסים וזיהוי מגמות ואנומליות בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, פיתוח תשתית לצורך ניתוח נתונים, שילוב והטמעת כלים לצורך גישה ושליפה עצמאית של נתונים ממאגרי מידע, פיתוח דוחות, ממשקים ומסכים באמצעות כלי ויזואליזציה.
ניסיונו של רועי בתחום ה- Data Science, כולל: עבודה עם מסדי נתונים גדולים Big Data תוך שימוש באלגוריתמים מסוג Supervised Learning (כגון: Linear Regression, Ridge Regression, Lasso Regression, Elastic Net Regression, Logistic Regression, Maximum Likelihood Estimation, k-Nearest Neighbors, Decision Tree, Random Forest, Ensemble, Bagging, Boosting, Naïve Bayes Classifier, Linear Separation, Support Vector Machine, Non-Linear Separation, SVM Regression, Artificial Neural Network, Convolutional Neural Network ו- Recurrent Neural Network) לניבוי וסיווג בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה ובמודלים מסוג Reinforcement Learning (כגון: Q-learning, Monte Carlo Simulation, Temporal Difference Learning ו- n-Step Bootstrapping) לקבלת החלטות מרובות שלבים בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, זיהוי אתגרים עסקיים שבהםDATA יכול להוות גורם מכריע בשיפור קבלת החלטות, איתור ואיסוף מקורות מידע, הגדרה ואיפיון של שימושי המידע, בניית מסד המידע, אפיון והגדרת הצגת המידע ותוצריו, פיתוח כלים, מודלים, תהליכים ומערכות בתחום האנליזה, תוך שימוש בכלי אנליזה מתקדמים (EXCEL, VBA ושפת R).
מגזין "סטטוס" מופק ע"י:
Tags: אקטואריה


