





























































סדרת מאמרים זו מבוססת על נסיוני כמדען נתונים (Data Scientist) המתמחה בתחום למידת המכונה (ML- Machine Learning) בעולמות המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה
פורסם: 10.12.20 צילום: shutterstock
חלק מהאלגוריתמים של ML למדתי בתואר הראשון שלי בכלכלה (כגון: הטיה מול שונות, בעיות רגרסיה מול בעיות סיווג, חלוקת נתונים ל- Training set ו- Testing set, נרמול נתונים, רגרסיה לינארית, Ridge, Lasso ו- Elastic Net, יישומי אלגברה לינארית בתוכנת Excel וכו'), חלק בקורסים לתואר שני בכלכלה (כגון: Dimensionality Reduction, Principle Components Analysis, K-Mean Cluster Analysis, Hierarchical Cluster Analysis ו- Time Series וכו'), חלק בתואר השני שלי במימון (כגון: Decision Trees, Random Forest, Monte Carlo Simulation, Bootstrapping, Cubic-Spline, Nelson-Siegel-Svensson וכו'), חלק למדתי בלימודי התעודה באקטואריה (המסווג הנאיבי של בייס, Overfitting, ,Underfitting Convolution and Pooling, תכנות מדעי וסטטיסטי בשפת R וכו'), חלק למדתי בלימודי התעודה בניהול סיכונים פיננסיים ועל חלק אף נבחנתי במבחנים הבינלאומיים להסמכה בתחום ניהול הסיכונים הפיננסיים FRM (כגון: רגרסיה לוגיסטית, Logit, Probit,LDA , K-Nearest Neighbor ו- Support Vector Machines וכו') ואת היתר למדתי עצמאית באינטרנט (כגון: Neural Networks, Ensemble, Bagging, Boosting, תכנות בשפת VBA וכו').
כמובן שההבנה העמוקה שלי באלגוריתמים של ML נשענת הן על הידע שלי בסטטיסטיקה (הכולל בין היתר: סוגי נתונים והצגתם באופן טבלאי וגרפי, מדדי מרכוז ומדדי פיזור, אחוזונים, מדדי קשר, התפלגות הנתונים, הסתברות פשוטה במרחב הסתברותי אחיד ובמרחב הסתברותי לא אחיד, הסתברות מותנית, נוסחת בייס, משתנים מקריים בדידים: ניסויי ברנולי, התפלגות בינומית, התפלגות פואסונית, התפלגות גיאומטרית, התפלגות היפרגיאומטרית, משתנים מקריים רציפים: התפלגות נורמלית, הסקה סטטיסטית, אמידה נקודתית, רווחי סמך, מבחני השערות וסטטיסטיקה א-פרמטרית) והן על הידע שלי בתורת הקבוצות (הכולל בין היתר: מערכות משוואות לינאריות, וקטורים ב- R^n, מטריצות ריבועיות, מטריצות אלמנטריות, מרחבים וקטורים, מרחבי מכפלה פנימית, אורתוגנליות, דטרמיננטות, ערכים עצמיים, וקטורים עצמיים, לכסון, תבניות ריבועיות, משוואות הפרשים, תכונות טופולוגיות של קבוצות במרחב אוקלידי, קבוצות קמורות, משפטי הפרדה, פונקציות קמורות וקעורות, תכונות ואפיונים, שנאת סיכון, אופטימיזציה של פונקציות עם ובלי אילוצים, משפט הפונקציות הסתומות, משפט המעטפת, משוואות דיפרנציאליות מסדרים שונים, מערכות של משוואות דיפרנציאליות ושיטות של אופטימיזציה דינאמית).
מטרתה של סדרת מאמרים זו היא להקנות לקורא הבנה מה עושים מדעני נתונים (Data Scientists) נתונים וכיצד הם יכולים לקדם את מטרות הארגון. מרבית אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה מכירים בכך שהם זקוקים לידע מסוים בתחום ה- ML על מנת לשרוד בעולם שבו מספר מקומות העבודה מושפע יותר ויותר מתחום זה. כיום, כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה צריכים לדעת לעשות שימוש בתוכנת Excel ולדעת לתכנת ברמה מסוימת ב- VBA. מחר כבר כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה יצטרכו לדעת לעבוד עם מאגרי נתונים גדולים (Big Data) תוך פיתוח ושימוש באלגוריתמים של ML על מנת לזהות כיוונים ומגמות בעולמי התוכן שלהם או במגוון תחומים לרוחב הארגון.
בסדרת מאמרים זו חסכתי מהקורא את השימוש בתורת הקבוצות (קרי, מטריצות ווקטורים), למרות שלעניות דעתי אלגברה לינארית חיונית ביותר על מנת להגיע להבנה עמוקה ולשליטה ברמה גבוהה ב- ML.
לסיכום, סדרת מאמרים זו מציגה את הכלים, המודלים והאלגוריתמים הפופולריים ביותר שבהם משתמשים כיום מדעני נתונים.
- סיכום המאמר הקודם: המסווג הנאיבי של בייס (Naïve Bayes Classifier)
המסווג הנאיבי של בייס קל לשימוש כאשר ישנו מספר רב של מאפיינים. המסווג הנאיבי של בייס יוצר מערך של הנחות פשטניות שסביר להניח שאינן נכונות לגמרי בפועל. עם זאת, נמצא שהמסווג הנאיבי של בייס מועיל ביותר במצבים שונים ומגוונים. לדוגמא, המסווג הנאיבי של בייס יעיל למדי בזיהוי ספאם (Spam, דואר זבל) כאשר תדירויות המילים משמשות בתור המאפיינים.
- סיווג SVM לינארי
מכונת וקטורים תומכים (Support Vector Machine) או בקיצור SVM היא טכניקה של למידה בהשגחה המשמשת לניתוח נתונים לצורך סיווג וחיזוי כאחד.
כנהוג בלמידה בהשגחה, דוגמאות סט האימון מיוצגות כווקטורים במרחב ליניארי. עבור בעיות סיווג, בשלב האימון מתאימים מסווג שמפריד נכון ככל האפשר בין דוגמאות אימון חיוביות ושליליות. המסווג שנוצר ב-SVM הוא המפריד הליניארי אשר יוצר מרווח גדול ככל האפשר בינו לבין הדוגמאות הקרובות לו ביותר בשתי הקטגוריות. כאשר נבחנת נקודה חדשה, האלגוריתם יזהה האם היא ממוקמת בתוך הקו המגדיר את הקבוצה, או מחוצה לו.
SVM אינו מוגבל רק לסיווג ליניארי, ויכול לבצע גם סיווג לא ליניארי באמצעות הוספת תעלול קרנל (kernel, גרעין) שבו ממופה משתנה הכניסה למרחב במימד גבוה יותר.
בדומה לגישת אמידת הצפיפות, שני משתנים מסבירים מייצרים תרשים פיזור. ההבדל בין אלגוריתם השכן ה- k הקרוב ביותר לבין ה- SVM הוא שב- SVM קווים וקטוריים מחלקים את תרשים הפיזור לקבוצות; לדוגמא, הלוואות טובות מימין לקו המפריד והלוואות רעות משמאל לקו.
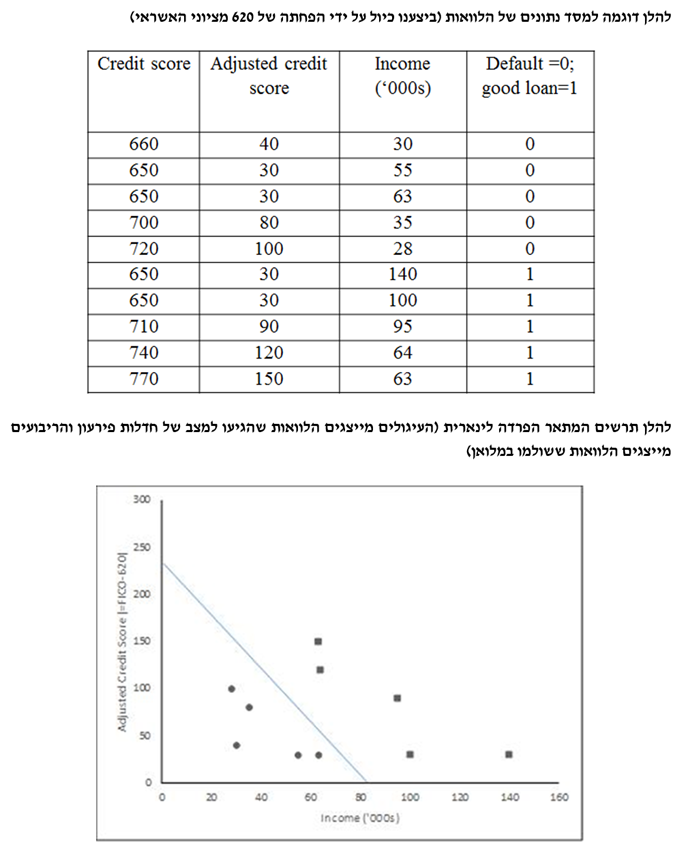
בגישת ה- SVM אנו מוצאים למעשה נתיב (pathway, על-מישור) מסוים שמפריד את הנתונים לשתי קבוצות ככל האפשר.
- הפרדה קשיחה (Hard Margin)
במקרים של "הפרדה קשיחה" (hard margin) הפרדה מושלמת אכן אפשרית (כמו בדוגמא לעיל). האלגוריתם מוצא הנתיב הרחב ביותר האפשרי. כמובן שיש לבצע תחילה נרמול של הנתונים (במקרה שלנו הפחתנו 620 מציון האשראי של כל הלוואה). הוקטורים התומכים הם למעשה התצפיות בקצה הנתיב.
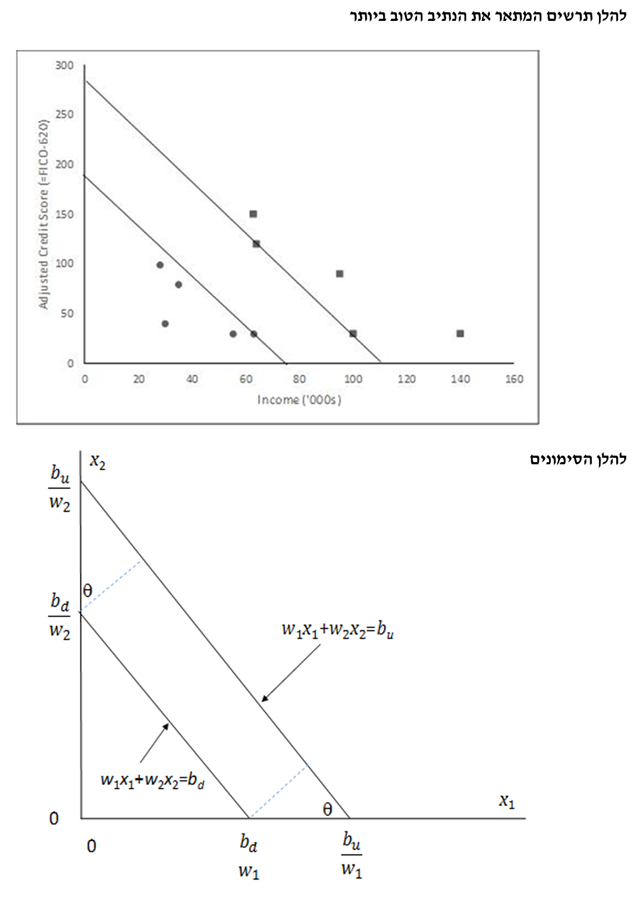

- הפרדה רכה (Soft Margin)
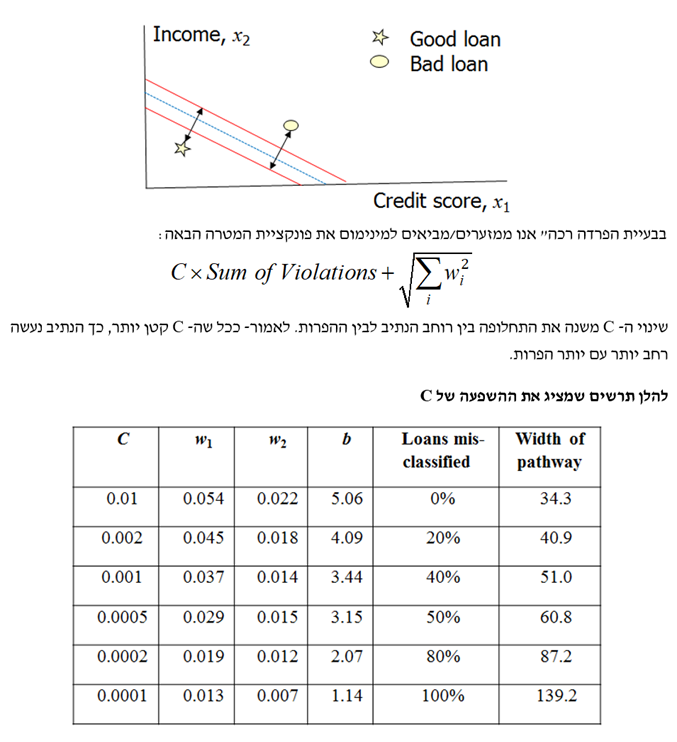
עד כה עסקנו בבעיית "הפרדה קשיחה", כלומר, ללא הפרות. כעת נגדיר "הפרדה רכה" (soft margin) כמצב שבו אין הפרדה ליניארית בין שתי הקבוצות. עבור בעיית "הפרדה רכה" אנו מחשבים את היקף ההפרה או מידת ההפרה עבור נתונים שסווגו לא נכון:
- הפרדה א-לינארית (Non-linear Separation)
המטרה היא ליצור מאפיינים חדשים כך שהגבול (boundary) יהפוך ללינארי. נניח שקיים מאפיין יחיד כלשהו (נניח גיל) ונניח שמצאנו שהערכים הנמוכים והגבוהים של אותו מאפיין נוטים לתת תוצאה אחת בעוד שהערכים הבינוניים שלו נותנים תוצאה אחרת.

- ניבוי משתנה רציף
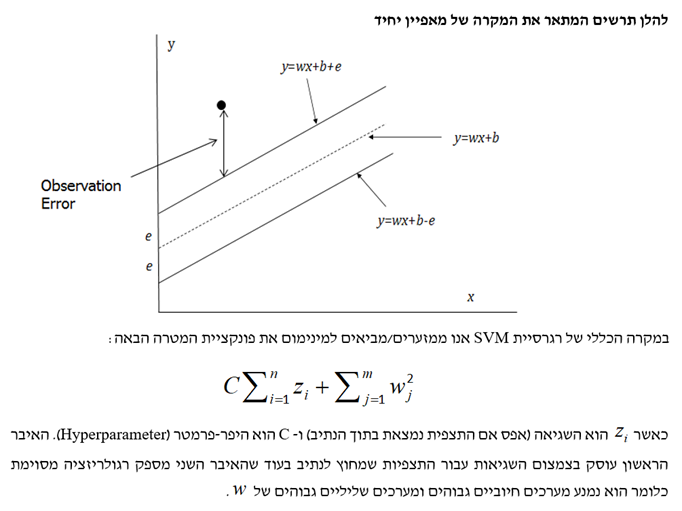
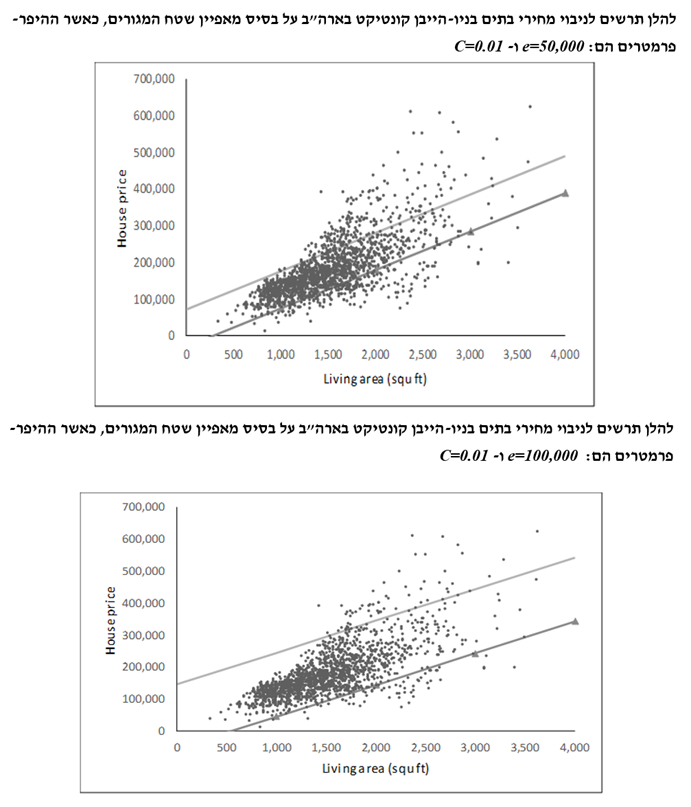
כעת נדבר על רגרסיית SVM, הווה אומר, שימוש ב- SVM לצורך ניבוי ערכו של משתנה רציף. אנו מחפשים נתיב בעל רוחב מסוים הכולל כמה שיותר ערכי target. אם ערך ה- target נמצא בתוך הנתיב, או אז ההנחה היא שלא תהיה שגיאה. מאידך, אם ערך ה- target נמצא מחוץ לנתיב, או אז השגיאה היא ההפרש שבין הערך האמיתי והערך שנחזה באמצעות הקצה החיצוני של הנתיב.
נסביר שהיפר-פרמטר הוא פרמטר שערכו מוגדר לפני תחילת תהליך הלמידה ושאיננו חלק מהנתונים. לעומת זאת, הערכים של הפרמטרים האחרים נגזרים מהנתונים של סט אימון. אלגוריתמים שונים דורשים היפר-פרמטרים שונים, בעוד שחלק מהאלגוריתמים הפשוטים (כמו למשל רגרסיה לינארית פשוטה מסוג הריבועים הפחותים) אינם דורשים היפר-פרמטרים. בהתחשב בהיפר-פרמטרים אלה, אלגוריתמים המאומנים על סט האימון לומדים את הפרמטרים מתוך הנתונים. לדוגמה, רגרסיה מסוג Lasso היא אלגוריתם שמוסיף היפר-פרמטר לרגרסיה מסוג הריבועים הפחותים, היפר-פרמטר שאותו יש להגדיר לפני שמכמתים את הפרמטרים באמצעות סט האימון.
- סיכום
מכונת וקטורים תומכים (Support Vector Machine) או SVM מנסה לסווג תצפיות באמצעות גזירת נתיב שמחלק את הקטגוריות (Classes).
במצב הפשוט ביותר, המשוואה עבור כל אחד מצדדיו של הנתיב הינה פונקציה לינארית של המאפיינים וכל התצפיות אשר סווגו נכונה. מצב זה מכונה הפרדה קשיחה (Hard Separation). דא עקא, הפרדה מושלמת לעיתים קרובות איננה אפשרית וקיימת תחלופה בין הרוחב של הנתיב לבין ההפרות (Violations). עבור תצפית מסוימת שאינה "שוכבת" על הצד הנכון של הנתיב – מידת ההפרה נמדדת כמרחק הקצר ביותר שבין התצפית לבין המקום שבו היא הייתה אמורה להיות על מנת להיות מסווגת בצורה נכונה.
באמצעות עבודה עם פונקציות של ערכי המאפיינים חלף עם ערכי המאפיינים עצמם ניתן להפוך את הנתיב, שמפריד את התצפיות לשתי קבוצות, לנתיב א-לינארי. כך למשל, קיימת אפשרות ליצור מאפיינים חדשים על ידי העלאת ערכי המאפיינים הקיימים בריבוע, בשלישית, בחמישית וכו'. לחילופין, ניתן ליצור ציוני דרך (Landmarks) במרחב המאפיינים (Feature Space) באמצעות המאפיינים החדשים שהם פונקציות של המרחקים של תצפית מסוימת מציוני הדרך.
רגרסיית ה- SVM משתמשת ברעיונות שעומדים בבסיס קלסיפיקציית ה- SVM, על מנת לחזות או לנבא את ערכו של משתנה רציף מסוים, באמצעות יצירת נתיב שעובר דרך התצפיות לצורך חיזוי היעד (Target, המשתנה המוסבר). אם הערך של היעד עבור תצפית מסוימת הוא בתוך הנתיב, הרי שמונח שלא קיימת כל שגיאת חיזוי (Predictor Error). מאידך, אם הערך של היעד עבור תצפית מסוימת הוא מחוץ לנתיב, או אז שגיאת החיזוי היא ההפרש שבין ערך היעד לבין מה שערך היעד היה צריך להיות אם הוא היה בתוך הנתיב. רוחבו של הנתיב (הנמדד בכיוון של ערך היעד) מוגדר על ידי המשתמש. לבסוף, נזכיר כי קיימת תחלופה בין שגיאת החיזוי הממוצעת לבין כמות הרגולריזציה.
"מדען נתונים הוא אחד שגם טוב יותר בסטטיסטיקה ואקונומטריקה מכל בוגר מדעי המחשב או מהנדס תוכנה וגם טוב יותר בהנדסת תוכנה מכל סטטיסטיקאי או כלכלן", רועי פולניצר, אקטואר ומעריך שווי, 2019.

רועי הינו מדען נתונים (Data Scientist) העושה שימוש ב- Machine Learning לצורך פיתוח מודלים מתקדמים לניהול סיכונים (בדגש על אשראי קמעונאי) כגון מודלים מנבאי התנהגות לקוחות ו/או מודלי תחזיות בתחום ניהול הסיכונים, שיפור מודלים בתחום ניהול הסיכונים, ניתוח צרכים עסקיים בעולמות ניהול הסיכונים, אפיון פתרונות מתאימים באמצעות עבודה מול בסיס נתונים גדולים ויישום כלים אנליטיים מתקדמים בעולם הבינה המלאכותית, הערכת סיכוני מודל וניטור פעולות מתקנות, ניתוח ועיבוד גורמי סיכון עיקריים, וניתוח הבדלים בין חלופות ואיפיון גורמי סיכון.
ניסיונו של רועי בתחום ה- Data Analysis, כולל: עבודה עם מאגרי מידע גדולים Big Data תוך שימוש ב- Statistical Learning (כגון: סטטיסטיקה תיאורית, הסתברות, הסקה סטטיסטית, סטטיסטיקה א-פרמטרית, חלוקת נתונים, נרמול נתונים, Fitting ו- Bayes Theorem) ובאלגוריתמים מסוג Unsupervised Learning (כגון: k-means Clustering, Hierarchical Clustering, Density-based Clustering, Distribution-based Clustering ו- Principle Components Analysis) למציאת דפוסים וזיהוי מגמות ואנומליות בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, פיתוח תשתית לצורך ניתוח נתונים, שילוב והטמעת כלים לצורך גישה ושליפה עצמאית של נתונים ממאגרי מידע, פיתוח דוחות, ממשקים ומסכים באמצעות כלי ויזואליזציה.
ניסיונו של רועי בתחום ה- Data Science, כולל: עבודה עם מסדי נתונים גדולים Big Data תוך שימוש באלגוריתמים מסוג Supervised Learning (כגון: Linear Regression, Ridge Regression, Lasso Regression, Elastic Net Regression, Logistic Regression, Maximum Likelihood Estimation, k-Nearest Neighbors, Decision Tree, Random Forest, Ensemble, Bagging, Boosting, Naïve Bayes Classifier, Linear Separation, Support Vector Machine, Non-Linear Separation, SVM Regression, Artificial Neural Network, Convolutional Neural Network ו- Recurrent Neural Network) לניבוי וסיווג בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה ובמודלים מסוג Reinforcement Learning (כגון: Q-learning, Monte Carlo Simulation, Temporal Difference Learning ו- n-Step Bootstrapping) לקבלת החלטות מרובות שלבים בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, זיהוי אתגרים עסקיים שבהםDATA יכול להוות גורם מכריע בשיפור קבלת החלטות, איתור ואיסוף מקורות מידע, הגדרה ואיפיון של שימושי המידע, בניית מסד המידע, אפיון והגדרת הצגת המידע ותוצריו, פיתוח כלים, מודלים, תהליכים ומערכות בתחום האנליזה, תוך שימוש בכלי אנליזה מתקדמים (VBA, R Programming ו- Python).
מגזין "סטטוס" מופק ע"י:


