





























































רגרסיה לינארית היא בוודאי איננה טכניקה חדשה של למידת מכונה. למעשה רגרסיה לינארית משחקת תפקיד מרכזי במחקרים אמפיריים מזה שנים רבות. מדעני נתונים (Data Scientists) אימצו את הרגרסיה הלינארית ככלי לניבוי/חיזוי
פורסם: 3.12.19 צילום: shutterstock
מאמר מס' 5 בסדרה
סדרת מאמרים זו מבוססת על נסיוני כמדען נתונים (Data Scientist) המתמחה בתחום למידת המכונה (ML- Machine Learning) בעולמות המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה.
חלק מהאלגוריתמים של ML למדתי בתואר הראשון שלי בכלכלה (כגון: הטיה מול שונות, בעיות רגרסיה מול בעיות סיווג, חלוקת נתונים ל- Training set ו- Testing set, נרמול נתונים, רגרסיה לינארית, Ridge, Lasso ו- Elastic Net, יישומי אלגברה לינארית בתוכנת Excel וכו'), חלק בקורסים לתואר שני בכלכלה (כגון: Dimensionality Reduction, Principle Components Analysis, K-Mean Cluster Analysis, Hierarchical Cluster Analysis ו- Time Series וכו'), חלק בתואר השני שלי במימון (כגון: Decision Trees, Random Forest, Monte Carlo Simulation, Bootstrapping, Cubic-Spline, Nelson-Siegel-Svensson וכו'), חלק למדתי בלימודי התעודה באקטואריה (המסווג הנאיבי של בייס, Overfitting, ,Underfitting Convolution and Pooling, תכנות מדעי וסטטיסטי בשפת R וכו'), חלק למדתי בלימודי התעודה בניהול סיכונים פיננסיים ועל חלק אף נבחנתי במבחנים הבינלאומיים להסמכה בתחום ניהול הסיכונים הפיננסיים FRM (כגון: רגרסיה לוגיסטית, Logit, Probit,LDA , K-Nearest Neighbor ו- Support Vector Machines וכו') ואת היתר למדתי עצמאית באינטרנט (כגון: Neural Networks, Ensemble, Bagging, Boosting, תכנות בשפת VBA וכו').
כמובן שההבנה העמוקה שלי באלגוריתמים של ML נשענת הן על הידע שלי בסטטיסטיקה (הכולל בין היתר: סוגי נתונים והצגתם באופן טבלאי וגרפי, מדדי מרכוז ומדדי פיזור, אחוזונים, מדדי קשר, התפלגות הנתונים, הסתברות פשוטה במרחב הסתברותי אחיד ובמרחב הסתברותי לא אחיד, הסתברות מותנית, נוסחת בייס, משתנים מקריים בדידים: ניסויי ברנולי, התפלגות בינומית, התפלגות פואסונית, התפלגות גיאומטרית, התפלגות היפרגיאומטרית, משתנים מקריים רציפים: התפלגות נורמלית, הסקה סטטיסטית, אמידה נקודתית, רווחי סמך, מבחני השערות וסטטיסטיקה א-פרמטרית) והן על הידע שלי בתורת הקבוצות (הכולל בין היתר: מערכות משוואות לינאריות, וקטורים ב- R^n, מטריצות ריבועיות, מטריצות אלמנטריות, מרחבים וקטורים, מרחבי מכפלה פנימית, אורתוגנליות, דטרמיננטות, ערכים עצמיים, וקטורים עצמיים, לכסון, תבניות ריבועיות, משוואות הפרשים, תכונות טופולוגיות של קבוצות במרחב אוקלידי, קבוצות קמורות, משפטי הפרדה, פונקציות קמורות וקעורות, תכונות ואפיונים, שנאת סיכון, אופטימיזציה של פונקציות עם ובלי אילוצים, משפט הפונקציות הסתומות, משפט המעטפת, משוואות דיפרנציאליות מסדרים שונים, מערכות של משוואות דיפרנציאליות ושיטות של אופטימיזציה דינאמית).
מטרתה של סדרת מאמרים זו היא להקנות לקורא הבנה מה עושים מדעני נתונים (Data Scientists) נתונים וכיצד הם יכולים לקדם את מטרות הארגון. מרבית אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה מכירים בכך שהם זקוקים לידע מסוים בתחום ה- ML על מנת לשרוד בעולם שבו מספר מקומות העבודה מושפע יותר ויותר מתחום זה. כיום, כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה צריכים לדעת לעשות שימוש בתוכנת Excel ולדעת לתכנת ברמה מסוימת ב- VBA. מחר כבר כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה יצטרכו לדעת לעבוד עם מאגרי נתונים גדולים (Big Data) תוך פיתוח ושימוש באלגוריתמים של ML על מנת לזהות כיוונים ומגמות בעולמי התוכן שלהם או במגוון תחומים לרוחב הארגון.
בסדרת מאמרים זו חסכתי מהקורא את השימוש בתורת הקבוצות (קרי, מטריצות ווקטורים), למרות שלעניות דעתי אלגברה לינארית חיונית ביותר על מנת להגיע להבנה עמוקה ולשליטה ברמה גבוהה ב- ML.
לסיכום, סדרת מאמרים זו מציגה את הכלים, המודלים והאלגוריתמים הפופולריים ביותר שבהם משתמשים כיום מדעני נתונים.
- סיכום המאמר הקודם: מודלים לינאריים בבעיות רגרסיה (רגרסיה לינארית,Ridge , Lasso)
רגרסיה לינארית היא בוודאי איננה טכניקה חדשה של למידת מכונה. למעשה רגרסיה לינארית משחקת תפקיד מרכזי במחקרים אמפיריים מזה שנים רבות. מדעני נתונים (Data Scientists) אימצו את הרגרסיה הלינארית ככלי לניבוי/חיזוי.
ליישומים של למידת מכונה לעיתים קרובות ישנם מאפיינים (Features, משתנים מסבירים) רבים, אשר חלקם מתואמים מאוד (Highly Correlated) האחד עם השני. במקרה שכזה רגרסיה לינארית מהימנה תייצר תוצאה שתספק משקולת (Coefficient, מקדם) חיובית גבוהה לערכים עבור מאפיין מתואם אחד ומשקולת שלילית גבוהה לערכים עבור מאפיין מתואם אחר.
אחת הגישות להקטנת המשקולות של המאפיינים במודל הרגרסיה נקראת רגרסיה מסוג Ridge. גישה אחרת נקראת רגרסיה מסוגLasso . רגרסיה מסוג Lasso מקטינה לאפס את המשקולות של המאפיינים הלא חשובים. גישה נוספת נקראת רגרסיה מסוג Elastic Net והיא עושה שימוש ברעיונות שעומדים בבסיסן של הרגרסיות מסוג Ridge ו- Lasso. למעשה, רגרסיה מסוג Elastic Net יכולה לשמש להשגת היתרונות של שתי הרגרסיות הללו (קרי, קבלת משקולות שקטנות יותר בגודלן והשמטת המאפיינים לא חשובים).
ניתן להכניס משתנים קטגוריאליים (Categorical Variables) לרגרסיה לינארית באמצעות יצירת משתנה דמה (Dummy Variable), אחד לכל קטגוריה. משתנה הדמה עבור תצפית מסוימת נקבע כשווה ל- 1 אם התצפית 'נופלת' באותה קטגוריה ו- 0 אם לאו.
- ניתוח מפלה לינארי (Linear Discriminant Analysis)
המטרה היא "לפרק" את האוכלוסייה לקבוצות משנה, כאשר תחילה מגדירים מספר קבוצות (Classes) ולאחר מכן מפעילים מודל מסוים (למשל רגרסיה לינארית) על מנת לסווג חברה מסוימת לקבוצה מסוימת. הדוגמא הקלאסית היא מודל ה- Z-score של אלטמן. כלכלנים יודעים שכאשר עוסקעם ביחסים פיננסיים, יש כאלה המציעים לצרף מספר יחסים ביחד למודל סטטיסטי המבוסס לרוב על רגרסיה מרובת משתנים כדי לסייע בניבוי חדלות פירעון של חברות. החוקר שהיה מהחלוצים בתחום הוא אד אלטמן אשר פרסם לראשונה את המודל שלו ב- 1968. המודל שלו התבסס על חמישה יחסים והוא אמד פונקציה שסייעה לסווג חברות כבעלות סיכון גבוה לחדלות פירעון במהלך השנתיים הקרובות.
תהליך הניתוח המפלה הלינארי או בקיצור ה- LDA כרוך בזיהוי תחילה של סט מאפיינים (כלומר משתנים המסבירים את ההבדל בין חברה המצויה שבבעיית איתנות פיננסית לבין חברה בעלת איתנות פיננסית) ולאחר מכן בחיפוש אחר הצירוף הליניארי המפריד בצורה הטובה ביותר בין שתי הקבוצות: חברות המצויות בבעיית איתנות פיננסית (Default) וחברות בעלות איתנות פיננסית (Non-Default).
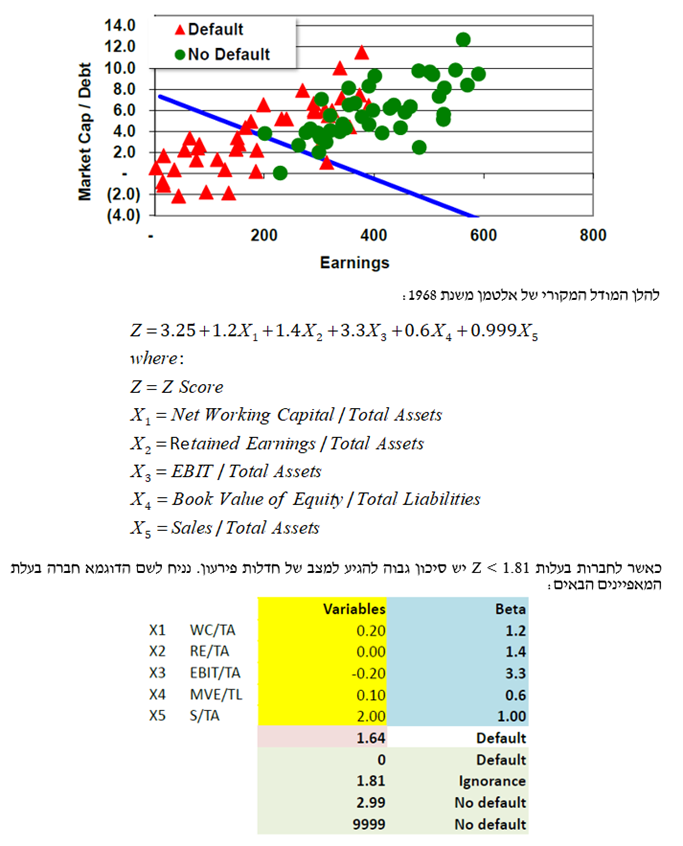

- הפליה פרמטרית (Parametric Discrimination)
הנוסחה המפלה יכולה להיות פרמטרית (לרבות לינארית). לעתים קרובות, אנו זקוקים להסתברות בין 0 ל- 1. הן מודל ה- Logit והן מודל ה- Probit והן מודל ה- Tobit יודעים להתמיר מודל דירוג לטווח הסתברויות בין אפס (0) לאחד (1).
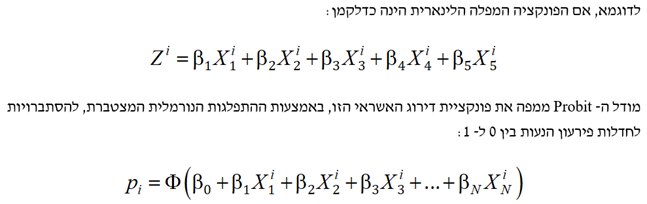
- רגרסיה לוגיסטית
המטרה היא לסווג את התצפיות ל"תוצאה חיובית" ו- "תוצאה שלילית" באמצעות נתונים אודות המאפיינים. ההסתברות לתוצאה חיובית מתקבלת מהצבת ה- Y בפונקציית הסיגמואיד (Sigmoid Function) שלהלן:
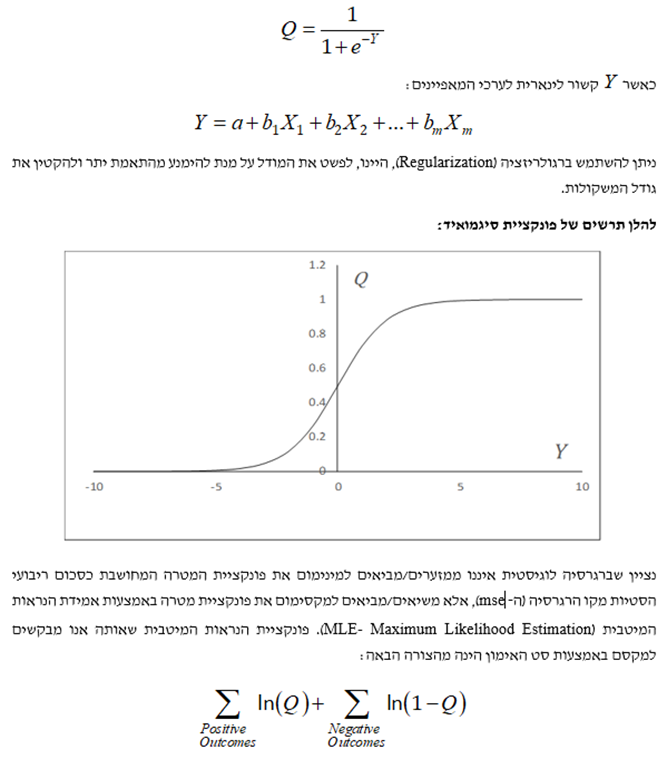
אלגוריתם מעלה הגרדיאנט (Gradient Ascent Algorithm) נבחר לצורך קבלת פתרון נומרי מאחר ואין פתרון אנליטי לבעיית הנראות המיטבית.
- מקרה מבחן נתוני הלוואות של Prosper Marketplace
חברת Prosper Marketplace היא מלווה מסוגpeer-to-peer (הלוואות חברתיות) המאפשר למשקיעים להלוות כסף ללווים ללא תיווך. חברת Prosper Marketplace משתמשת בלמידת מכונה ומפרסמת נתונים על הלוואותיה.
לקחתי סט של נתונים של חברת Prosper Marketplace שמייצג את החלטות מתן האשראי שלה, כאשר סט הנתונים מורכב מהלוואות שהועמדו ללווים וממידע האם ההלוואות הוכיחו את עצמן כהלוואות טובות או שהן הגיעו למצב של חדלות פירעון (Default) (המגבלה היחידה היא שאין לנו נתונים אודות הלוואות שהוחלט לא לתת).
השתמשתי בסט אימון וסט בדיקה. סט האימון מורכב מ- 8,695 תצפיות שמתוכן 1,499 הן הלוואות שהגיעו למצב של חדלות פירעון ויתר ה- 7,196 הן הלוואות שהוכחו כטובות. סט הבדיקה מורכב מ- 5,916 תצפיות שמתוכן 1,058 הן הלוואות שהגיעו למצב של חדלות פירעון ויתר ה- 4,858 הן הלוואות שהיו טובות. השתמשתי בארבעה מאפיינים (אחד מהם, בעלות על בית, היה קטגוריאלי ולכן היה עליי לקדד אותו באמצעות משתנה דמה שמקבל 0 או 1). המשקולות שנאמדו עבור סט האימון מוצגות להלן:
ניסיתי לשפר את הקריטריון של חברת Prosper Marketplace באמצעות למידת מכונה. מצ"ב תמצית מהנתונים שבהם השתמשתי.
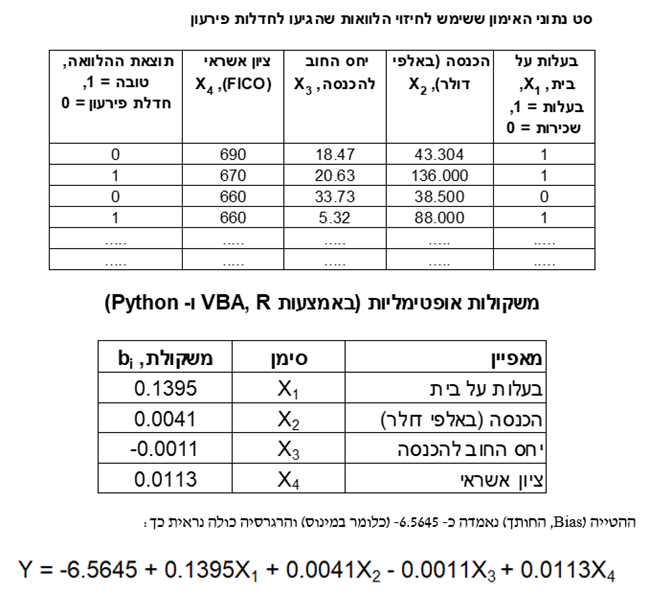
כעת עלינו להחליט על קריטריון לסיווג האם הלוואה מסוימת הינה טובה או לא טובה. ההחלטה על קריטריון כרוכה בהגדרת רמת סף, Z, עבור הערך של Q כך שאםQ > Z או אז ההלוואה מסווגת כטובה ואם Q ≤ Z או אז ההלוואה מסווגת כלא טובה. ניתן לסכם את התוצאות, המתקבלות מיישום ערך מסוים של Z על סט הבדיקה, באמצעות מה שמכונה מטריצת טעות (Confusion Matrix). מטריצת הטעות מציגה את הקשר שבין הסיווגים לבין התוצאות בפועל.


- רמת הדיוק של הרגרסיה הלוגיסטית
משעה שקיבלנו את תוצאות הרגרסיה עלינו לגבש קריטריון החלטה. סט הנתונים שלנו איננו מאוזן הואיל והוא כולל בחוהו הרבה יותר הלוואות טובות מאשר הלוואות שהגיעו למצב של חדלות פירעון. נעיר כי קיימות פרוצדורות ליצירת סט נתונים מאוזן.
אילו סט הנתונים שלנו היה מאוזן (קרי, מורכב ממספר שווה של הלוואות טובות והלוואות שהגיעו למצב של חדלות פירעון), או אז היינו יכולים לסווג תצפיות כחיובית אם Q>0.5 אחרת מדובר בתצפית שלילית. הבעיה שהקריטריון הזה של Q>0.5 איננו לוקח בחשבון את העלות הנגרמת כתוצאה מסיווג שגוי (Misclassifying) של הלוואה רעה (קרי, הלוואה רעה שסווגה בטעות כהלוואה טובה) ומאובדן הרווח כתוצאה מסיווג שגוי של הלוואה טובה (קרי, הלוואה טובה שסווגה בטעות כהלוואה רעה).
אחד הפתרונות לבעיה זו היא לנסות ולחקור רמות סף (Thresholds) שונות, Z, כך שאם Q>Z אז נקבל את הבקשה להלוואה ואם Q≤ Z אז נדחה את הבעיה להלוואה.
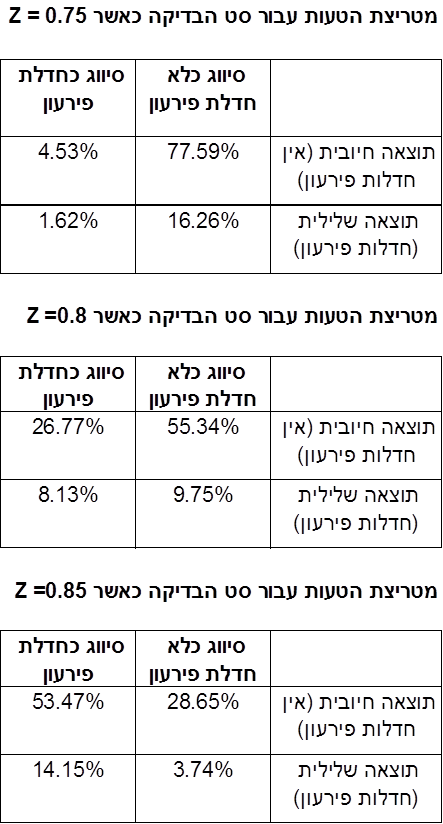
על מנת להבין את התוצאות של מטריצת הטעות, ראשית אני אגדיר את ארבעת האלמנטים של מטריצת הטעות כדלקמן:
- חיובי אמיתי (TP- True Positive): כאשר הן הסיווג והן התוצאה הם חיוביים.
- שלילי כוזב (FN- False Negative): כאשר הסיווג הוא שלילי אך התוצאה היא חיובית.
- חיובי כוזב (FP- False Positive): כאשר הסיווג הוא חיובי אך התוצאה היא שלילית.
- שלילי אמיתי (TN- True Negative): כאשר הן הסיווג והן התוצאה הם שליליים.
- עקומת ROC
למעשה קיימים מספר יחסי תחלופה. אני יכול להגדיל את שיעור השליליים האמיתיים (קרי, לזהות אחוז גבוה יותר של הלוואות שיגיעו לחדלות פירעון) רק אם אני אזהה אחוז נמוך יותר של הלוואות שהוכחו כטובות. כמובן שהנכונות יורדת ככל ששיעור השליליית האמיתיים עולה.
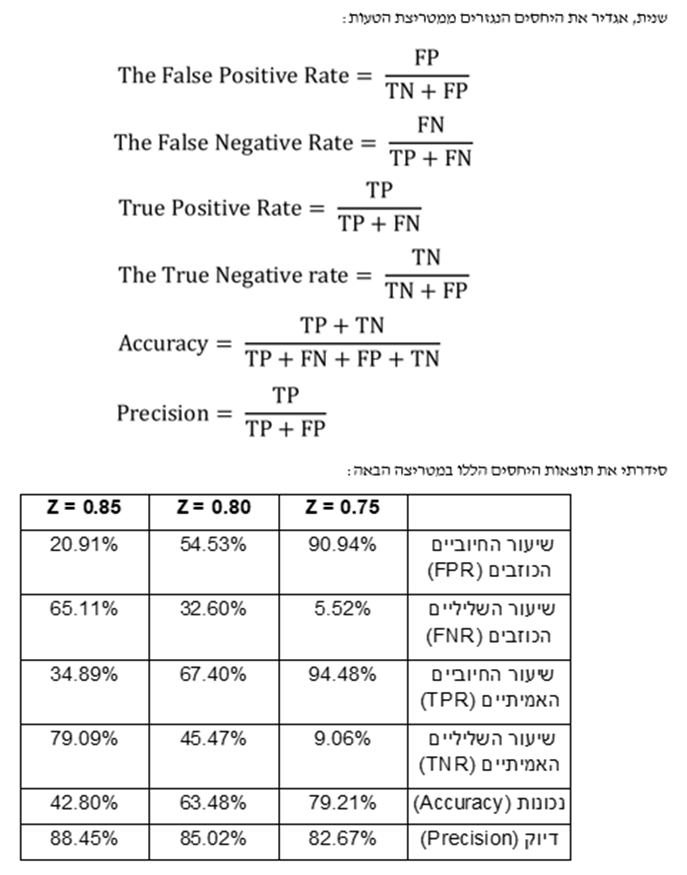
עקומת ה- ROC מתארת את שיעור החיוביים האמיתיים (TPR) ביחס שיעור החיוביים הכוזבים (FPR). כאשר אנו משנים את קריטריון ה- Z אנו מקבלים את עקומת ROC (עקומה אופיינית למסווג, Receiver Operating Characteristics Curve):
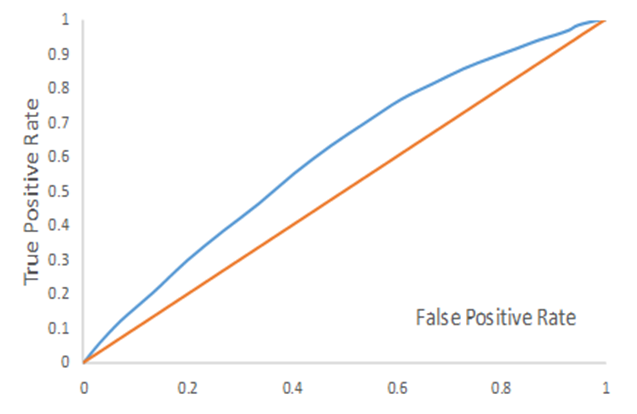
מתוך עקומת ה- ROC מוגדר מדד "השטח שמתחת לעקומה" (AUC- Area Under Curve) שהוא השטח שמתחת לעקומת ה- ROC. ה- AUC הוא דרך פופולרית לסיכום יכולת הניבוי של מודל לאמידת משתנה בינארי. כאשר AUC = 1 המודל מושלם, לחילופין כאשר AUC = 0.5 למודל אין יכולת ניבוי או לחילופי חילופין כאשר AUC < 0.5 המודל גרוע יותר מאקראי. לסיכום, המשמעות של ה- AUC זה הסיכוי שהמודל שלנו ייתן פרדיקציה גבוהה יותר לערך חיובי אקראי מאשר לערך שלילי אקראי (כשאנחנו מניחים שהסיווג האמיתי המתאים לכל דגימה חיובית גבוה מהסיווג המתאים לכל דגימה שלילית). ככל שהשטח הזה קרוב יותר ל- 1, כך המדד נחשב טוב יותר. לעומת זאת, AUC של 5.0 הוא ערך לניחוש אקראי, ולכן כל ערך מתחת אליו נחשב גרוע במיוחד, וערך AUC מעליו אומר שהמודל מסוגל ללמוד משהו על הנתונים.
השטח שמתחת לעקומה (AUC) הינו דרך פופולארית לסכם את יכולת הסיווג של המודל. אם ה- AUC הוא 1.0, אז המודל הוא מושלם היות ושיעור החיובים האמיתיים (TPR) הוא 100% ושיעור החיוביים הכוזבים (FPR) הוא 0%. הקו הכתום שבתרשים לעיל מתאים ל- AUC של 0.5, מה שמתאים למודל ללא יכולת סיווג. למשל, למודל שמבצע סיווג מקרי יש AUC של 0.5.
עבור הנתונים שבחנתי למודל שלנו יש יכולת סיווג נמוכה. בהינתן שחברת Prosper Marketplace כבר משתמשת בלמידת מכונה לצורך קבלת החלטות ההלוואה שלה ושאני משתמש רק בארבעה מאפיינים, אז אין זה מפתיע שה- AUC של המודל שלנו הוא רק מעט מעל ל- 0.5 (העקום הכחול). הנקודה החשובה היא שאין לצפות שמודל שכזה יבצע סיווג מושלם.
המבחן העיקרי עבור מודל הסיווג הוא האם המודל מסוגל לקבל החלטות שטובות לפחות כמו ההחלטות שהיה מקבל בנאדם. רוצה לומר שבעת ההחלטה על הערך הראוי של Z (קרי, מיקום על עקומת ה- ROC) על הלווה לשקול הן את הרווח הממוצע מהלוואות שלא מגיעות לחדלות פירעון והן את ההפסד הממוצע מההלוואות שמגיעות לחדלות פירעון.
נשאלת השאלה, מה קורה אם הרווח מהלוואה שלא מגיעה לחדלות פירעון הוא X, בזמן שההפסד מהלוואה שמגיעה לחדלות פירעון הוא 4X? אז הרווח של המלווה הוא הגבוה ביותר כאשר הוא ממקסם את הפונקציה הבאה:
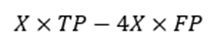
עבור האלטרנטיבות שבדקנו לעיל (Z של 0.75, 0.8 ו- 0.85) הפונקציה הבאה שווה ל- 12.55X, 16.34X ו- 13.69X, בהתאמה. זה מצביע על כך שמשלושת ערכי ה- Z האלטרנטיביים, 0.8 = Z הוא הרווחי ביותר.
נקודה נוספת היא שרגרסיות מסוג Ridge, Lasso ו- Elastic Net יכולות לשמש בשילוב עם רגרסיה לוגיסטית ממש כמו בשילוב עם רגרסיה רגילה. כמובן שזה שימושי מבחינה פוטנציאלית כאשר ישנם מאפיינים רבים. אני רק אעיר שזה נעשה אך ורק עבור אמידת הפרמטרים ולא עבור הסיווג משעה שהפרמטרים כבר נאמדו.
- לסיכום
רגרסיה לוגיסטית (Regression Logistic), ממש כמו רגסיה לינארית, משמשת במחקר האמפירי מזה שנים רבות. כעת הרגרסיה הלוגיסטית הופכת לכלי סיווג חשוב עבור מדעני נתונים. באופן טבעי קיימות שתי קבוצות. האחת מכונה "חיובית"; האחרת מכונה "שלילית". פונקציית הסיגמואיד (Function Sigmoid) בצורת S משמשת להגדרת ההסתברות של תצפית מסוימת 'ליפול' בקבוצה החיובית.
הליך חיפוש איטרטיבי משמש למציאת הפונקציה הלינארית של ערכי המאפיינים שכאשר מכניסים אותה לתוך פונקציית הסיגמואיד היא עושה את העבודה הטובה ביותר בהקצאת הסתברות גבוהה לתוצאות חיוביות והסתברות נמוכה לתוצאות שליליות. מקובל לסכם את תוצאות השימוש ברגרסיה לוגיסטית על נתוני סט הבדיקה (Test Set) באמצעות שימוש במטריצת הטעות (Matrix Confusion).
משעה שסיימנו לבנות את הרגרסיה הלוגיסטית, עלינו להחליט באיזה אופן ישמשו התוצאות. כך למשל, אם הרגסיה הלוגיסטית משמשת להחלטת מתן אשראי, הרי שעל מקבל ההחלטה להגדיר ערך Z מסוים. כאשר ההסתברות לקבלת תוצאה חיובית מההלוואה נאמדת כגבוהה יותר מ- Z, או אז הבקשה להלוואה מאושרת. כאשר ההסתברות לקבלת תוצאה חיובית מההלוואה נמוכה יותר מ- Z, או אז הבקשה להלוואה נדחית.
קיים יחס תחלופה בין ההצלחה לזהות הלוואות טובות לבין הצלחה לזהות הלוואות שתגענה למצב של חדלות פירעון (Default). באופן טבעי שיפור ההצלחה לזהות הלוואות שתגענה למצב של חדלות פירעון מביא להרעה בהצלחה לזהות הלוואות טובות, ולהיפך. ניתן לסכם את יחס תחלופה הזה באמצעות עקומת ה- ROC (עקומה אופיינית למסווג, Receiver Operating Characteristic Curve ) המקשרת בין שיעור החיובים האמיתיים (TPR, כלומר, רמת הביטחון או רמת הסמך ופירושו האחוז מהזמן שבו תוצאה חיובית מסווגת כחיובית) לבין שיעור החיוביים הכוזבים (FPR, רמת המובהקות ופירושו האחוז מהזמן שבו תוצאה חיובית מסווגת כשלילית).
"מדען נתונים הוא אחד שגם טוב יותר בסטטיסטיקה ואקונומטריקה מכל בוגר מדעי המחשב או מהנדס תוכנה וגם טוב יותר בהנדסת תוכנה מכל סטטיסטיקאי או כלכלן", רועי פולניצר, אקטואר ומעריך שווי, 2019.

הכותב רועי פולניצר הינו מדען נתונים (Data Scientist) העושה שימוש ב- Machine Learning לצורך פיתוח מודלים מתקדמים לניהול סיכונים (בדגש על אשראי קמעונאי) כגון מודלים מנבאי התנהגות לקוחות ו/או מודלי תחזיות בתחום ניהול הסיכונים, שיפור מודלים בתחום ניהול הסיכונים, ניתוח צרכים עסקיים בעולמות ניהול הסיכונים, אפיון פתרונות מתאימים באמצעות עבודה מול בסיס נתונים גדולים ויישום כלים אנליטיים מתקדמים בעולם הבינה המלאכותית, הערכת סיכוני מודל וניטור פעולות מתקנות, ניתוח ועיבוד גורמי סיכון עיקריים, וניתוח הבדלים בין חלופות ואיפיון גורמי סיכון.
ניסיונו של רועי בתחום ה- Data Analysis, כולל: עבודה עם מאגרי מידע גדולים Big Data תוך שימוש ב- Statistical Learning (כגון: סטטיסטיקה תיאורית, הסתברות, הסקה סטטיסטית, סטטיסטיקה א-פרמטרית, חלוקת נתונים, נרמול נתונים, Fitting ו- Bayes Theorem) ובאלגוריתמים מסוג Unsupervised Learning (כגון: k-means Clustering, Hierarchical Clustering, Density-based Clustering, Distribution-based Clustering ו- Principle Components Analysis) למציאת דפוסים וזיהוי מגמות ואנומליות בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, פיתוח תשתית לצורך ניתוח נתונים, שילוב והטמעת כלים לצורך גישה ושליפה עצמאית של נתונים ממאגרי מידע, פיתוח דוחות, ממשקים ומסכים באמצעות כלי ויזואליזציה.
ניסיונו של רועי בתחום ה- Data Science, כולל: עבודה עם מסדי נתונים גדולים Big Data תוך שימוש באלגוריתמים מסוג Supervised Learning (כגון: Linear Regression, Ridge Regression, Lasso Regression, Elastic Net Regression, Logistic Regression, Maximum Likelihood Estimation, k-Nearest Neighbors, Decision Tree, Random Forest, Ensemble, Bagging, Boosting, Naïve Bayes Classifier, Linear Separation, Support Vector Machine, Non-Linear Separation, SVM Regression, Artificial Neural Network, Convolutional Neural Network ו- Recurrent Neural Network) לניבוי וסיווג בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה ובמודלים מסוג Reinforcement Learning (כגון: Q-learning, Monte Carlo Simulation, Temporal Difference Learning ו- n-Step Bootstrapping) לקבלת החלטות מרובות שלבים בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, זיהוי אתגרים עסקיים שבהםDATA יכול להוות גורם מכריע בשיפור קבלת החלטות, איתור ואיסוף מקורות מידע, הגדרה ואיפיון של שימושי המידע, בניית מסד המידע, אפיון והגדרת הצגת המידע ותוצריו, פיתוח כלים, מודלים, תהליכים ומערכות בתחום האנליזה, תוך שימוש בכלי אנליזה מתקדמים (EXCEL, VBA ושפת R).
מגזין "סטטוס" מופק ע"י:
Tags: הערכת שווי פיננסים


