






























































מאמר מס' 3 בסדרה
פורסם: 8.11.19 צילום: shutterstock
מאת: רועי פולניצר
- הקדמה
סדרת מאמרים זו מבוססת על נסיוני כמדען נתונים (Data Scientist) המתמחה בתחום למידת המכונה (ML- Machine Learning) בעולמות המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה.
חלק מהאלגוריתמים של ML למדתי בתואר הראשון שלי בכלכלה (כגון: הטיה מול שונות, בעיות רגרסיה מול בעיות סיווג, חלוקת נתונים ל- Training set ו- Testing set, נרמול נתונים, רגרסיה לינארית, Ridge, Lasso ו- Elastic Net, יישומי אלגברה לינארית בתוכנת Excel וכו'), חלק בקורסים לתואר שני בכלכלה (כגון: Dimensionality Reduction, Principle Components Analysis, K-Mean Cluster Analysis, Hierarchical Cluster Analysis ו- Time Series וכו'), חלק בתואר השני שלי במימון (כגון: Decision Trees, Random Forest, Monte Carlo Simulation, Bootstrapping, Cubic-Spline, Nelson-Siegel-Svensson וכו'), חלק למדתי בלימודי התעודה באקטואריה (המסווג הנאיבי של בייס, Overfitting, ,Underfitting Convolution and Pooling, תכנות מדעי וסטטיסטי בשפת R וכו'), חלק למדתי בלימודי התעודה בניהול סיכונים פיננסיים ועל חלק אף נבחנתי במבחנים הבינלאומיים להסמכה בתחום ניהול הסיכונים הפיננסיים FRM (כגון: רגרסיה לוגיסטית, Logit, Probit,LDA , K-Nearest Neighbor ו- Support Vector Machines וכו') ואת היתר למדתי עצמאית באינטרנט (כגון: Neural Networks, Ensemble, Bagging, Boosting, תכנות בשפת VBA וכו').
כמובן שההבנה העמוקה שלי באלגוריתמים של ML נשענת הן על הידע שלי בסטטיסטיקה (הכולל בין היתר: סוגי נתונים והצגתם באופן טבלאי וגרפי, מדדי מרכוז ומדדי פיזור, אחוזונים, מדדי קשר, התפלגות הנתונים, הסתברות פשוטה במרחב הסתברותי אחיד ובמרחב הסתברותי לא אחיד, הסתברות מותנית, נוסחת בייס, משתנים מקריים בדידים: ניסויי ברנולי, התפלגות בינומית, התפלגות פואסונית, התפלגות גיאומטרית, התפלגות היפרגיאומטרית, משתנים מקריים רציפים: התפלגות נורמלית, הסקה סטטיסטית, אמידה נקודתית, רווחי סמך, מבחני השערות וסטטיסטיקה א-פרמטרית) והן על הידע שלי בתורת הקבוצות (הכולל בין היתר: מערכות משוואות לינאריות, וקטורים ב- R^n, מטריצות ריבועיות, מטריצות אלמנטריות, מרחבים וקטורים, מרחבי מכפלה פנימית, אורתוגנליות, דטרמיננטות, ערכים עצמיים, וקטורים עצמיים, לכסון, תבניות ריבועיות, משוואות הפרשים, תכונות טופולוגיות של קבוצות במרחב אוקלידי, קבוצות קמורות, משפטי הפרדה, פונקציות קמורות וקעורות, תכונות ואפיונים, שנאת סיכון, אופטימיזציה של פונקציות עם ובלי אילוצים, משפט הפונקציות הסתומות, משפט המעטפת, משוואות דיפרנציאליות מסדרים שונים, מערכות של משוואות דיפרנציאליות ושיטות של אופטימיזציה דינאמית).
מטרתה של סדרת מאמרים זו היא להקנות לקורא הבנה מה עושים מדעני נתונים (Data Scientists) נתונים וכיצד הם יכולים לקדם את מטרות הארגון. מרבית אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה מכירים בכך שהם זקוקים לידע מסוים בתחום ה- ML על מנת לשרוד בעולם שבו מספר מקומות העבודה מושפע יותר ויותר מתחום זה. כיום, כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה צריכים לדעת לעשות שימוש בתוכנת Excel ולדעת לתכנת ברמה מסוימת ב- VBA. מחר כבר כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה יצטרכו לדעת לעבוד עם מאגרי נתונים גדולים (Big Data) תוך פיתוח ושימוש באלגוריתמים של ML על מנת לזהות כיוונים ומגמות בעולמי התוכן שלהם או במגוון תחומים לרוחב הארגון.
בסדרת מאמרים זו חסכתי מהקורא את השימוש בתורת הקבוצות (קרי, מטריצות ווקטורים), למרות שלעניות דעתי אלגברה לינארית חיונית ביותר על מנת להגיע להבנה עמוקה ולשליטה ברמה גבוהה ב- ML.
לסיכום, סדרת מאמרים זו מציגה את הכלים, המודלים והאלגוריתמים הפופולריים ביותר שבהם משתמשים כיום מדעני נתונים.
- סיכום המאמר הקודם: מבוא ללמידת מכונה (Machine Learning)
למידת מכונה היא ענף של בינה מלאכותית העוסקת בלמידה מתוך מאגרי מידע גדולים (Big Data). למידת מכונה כרוכה בפיתוח וגיבוש אלגוריתמים לצורך ניבוי, סיווג נתונים (Cluster Data), או לקבלת סדרת החלטות רצופות (Sequential Decisions) תוך אינטראקציה אופטימלית עם הסביבה.
ניתוח סטטיסטי עוסק באופן מסורתי ביצירת השערות (מבלי להסתכל על הנתונים) ולאחר מכן בבדיקת ההשערות באמצעות נתונים. למידת מכונה שונה מניתוח סטטיסטי בכך שהיא לא יוצרת השערות אלא גוזרת את המודל לחלוטין מתוך הנתונים.
היבט חשוב של למידת מכונה הינו תיקוף ובדיקה (Validation and Testing). רוצה לומר שיש לבדוק ולתקף מודלים שנוצרו באמצעו אלגוריתמים של למידת מכונה, בעזרת סט נתונים אחר, כזה שלא שימש ליצירת המודל (Out-of-Sample). מחד גיסא, מודל מורכב מדי עשוי להתאים את עצמו יתר על המידה (Over-fit, ללמוד יותר מדי טוב את) לנתונים ששימשו לאימון המודל ובכך הוא עלול שלא להצליח להכליל (Generalize) באופן מספק דיו את הנתונים החדשים. מאידך גיסא, מודל פשוט מדי עלול שלא להצליח לתפוס היבטים חשובים של הנתונים. למידת מכונה גורסת שיש לחלק את הנתונים הזמינים ל- 3 סטים של נתונים. סט האימון (Training Set) משמש לגיבוש/פיתוח מודלים אלטרנטיביים. סט התיקוף (Validation Set) משמש לבדיקה עד כמה המודלים מכלילים טוב את הנתונים החדשים. סט הבדיקה (Testing Set) נשמר בצד לאורך כל התהליך שתואר עד כה ומשמש כמבחן סבירות סופי לרמת הדיוק של המודל הנבחר.
טרם השימוש באלגוריתם של למידת מכונה, חשוב מאוד לנקות תחילה את הנתונים. המאפיינים (Features, המשתנים המסבירים) המהווים את הנתונים יכולים להיות נומריים או קטגוריים. בכל מקרה עשויים להיות מצבים של חוסר עקביות (Inconsistencies) באופן שבו הנתונים הוכנסו למאגר הנתונים. לפיכך, יש לזהות ולתקן מצבים של חוסר עקביות. חלק מהתצפיות עשויות להיות לא רלוונטיות למשימה הנוכחית ועל כן יש להשמיטן. בנוסף, יש לבדוק שאין תצפיות כפולות או כפילויות בנתונים, דבר שעלול ליצור הטיות. יש להשמיט חריגים אשר נוצרו בוודאות כתוצאה מטעויות הקלדה או מטעויות בהכנסת הנתונים למאגר. לבסוף, יש לטפל בנתונים חסרים באופן שלא יטה את התוצאות.
משפט בייס (Bayes Theorem, נוסחת בייס) הוא תוצאה המשמשת לעתים כאשר היא נדרש לכמת את אי הוודאות. משפט בייס הוא דרך להפוך משהו להתניה. נניח שאנו רוצים לדעת מהי ההסתברות שמאורע Y יתרחש ונניח שאנו גם יכולים לדעת האם מאורע אחר שקשור למאורע Y, נקרא לו מאורע X, התרחש או לא. עוד נניח שעל סמך ניסיון אנו יודעים את ההסתברות המותנה (Intensity) שמאורע X יתרחש בהינתן שידוע שמאורע Y התרחש. למעשה משפט בייס מאפשר לנו לחשב את ההסתברות המותנה שמאורע Y יתרחש בהינתן שידוע שמאורע X התרחש.
ללמידת מכונה ישנה טרמינולוגיה משלה אשר שונה מזו המסורתית המשמשת בסטטיסטיקה. במסגרת הטרמינולוגיה של למידת מכונה: מאפיין (Feature) הוא משתנה אשר לגביו יש לנו תצפיות; יעד (Target) הוא המשתנה אשר עליו אנו רוצים לבצע תחזיות; תוויות (Labels) הן תצפיות על היעד; למידה בהשגחה (Supervised Learning) היא תחום של למידת מכונה שבמסגרתה אנו משתמשים בנתונים על המאפיינים והיעדים לצורך ניבוי היעד על סמך נתונים חדשים; למידה ללא השגחה (Unsupervised Learning) היא תחום של למידת מכונה שבמסגרתה אנו מנסים למצוא דפוסים בנתונים על מנת לסייע לנו בהבנת מבנה הנתונים (בלמידה ללא השגחה אין יעד ועל כן אין גם תוויות); למידה בהשגחה למחצה (Semi-Supervised Learning) היא תחום של למידת מכונה שבמסגרתה אנו מבצעים תחזיות על היעד על סמך נתונים אשר לחלקם יש תוויות (קרי, יש להם ערכים של היעד) וליתר אין תוויות (קרי, אין להם ערכים של היעד); למידה בחיזוקים (Reinforcement Learning) היא תחום של למידת מכונה שבמסגרתו אנו יוצרים אלגוריתמים לקבלת סדרת החלטות רצופות כאשר מקבל ההחלטה פועל בתוואי של סביבה משתנה.
- מהי למידה ללא השגחה (Unsupervised Learning)?
בלמידה ללא השגחה אנחנו לא מנסים לנבא שום דבר, אנחנו רק מנסים לזהות דפוסים בנתונים. המטרה היא פשוט לבצע ניתוח אשכולות (cluster) לנתונים על מנת להעמיק את ההבנה שלנו את הסביבה.
נסביר זאת באמצעות דוגמא של ניתוח אשכולות על לקוחות. נניח שלבנק מסוים יש מאות אלפי לקוחות ו- 100 מאפיינים המתארים כל אחד מהלקוחות. למעשה ניתן להשתמש באלגוריתמים של למידה ללא השגחה על מנת לבצע ניתוח אשכולות ללקוחות הבנק על מנת שניתן יהיה לצפות את הצרכים שלהם ולתקשר איתם בצורה יעילה יותר.
- קליברציה לערכי המאפיינים (Feature Scaling)
לפני שמשתמשים באלגוריתמים רבים של למידת מכונה (לרבות אלה של למידה ללא השגחה), חשוב לבצע קליברציה לערכי המאפיינים על מנת להפוך אותם לברי השוואה.
במסגרת קליברציה מסוג Z-score אנו מבצעים קליברציה לערכי המאפיינים כך שבסופו של דבר אלו יהיו בעלי תוחלת של 0 וסטיית תקן של 1. בשלב הראשון של קליברציה מסוג Z-score אנו מחשבים את התוחלת וסטיית התקן של כל אחד מהמאפיינים. בשלב השני של קליברציה מסוג Z-score אנו מבצעים קליברציה לערכו של כל אחד מהמאפיינים על ידי חיסור התוחלת שלו מערכו וחלוקת תוצאת החיסור בסטיית התקן שלו.
במסגרת קליברציה מסוג Min-Max אנו מבצעים קליברציה לערכי המאפיינים כך שבסופו של דבר אלו ינועו בין 0 ל- 1. בשלב הראשון של קליברציה מסוג Min-Max אנו מחשבים את הערך המינימלי והערך המקסימלי של כל אחד מהמאפיינים. בשלב השני של קליברציה מסוג Min-Max אנו מבצעים קליברציה לערכו של כל אחד מהמאפיינים על ידי חיסור הערך המינימלי מערכו וחלוקת תוצאת החיסור בהפרש שבין הערך המקסימלי לערך המינימלי.
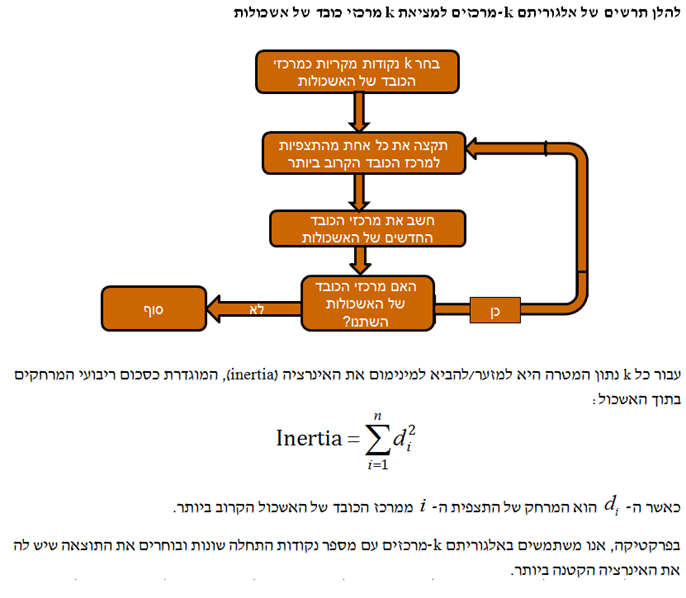
- אלגוריתם k-מרכזים (k-means)
על מנת לבצע ניתח אשכולות אנו צריכים את מדד המרחק. מדד המרחק הפשוט ביותר מכונה מדד המרחק האוקלידי (ED- Euclidean Distance). המרחק בין נקודה A לנקודה B מחושב באמצעות הנוסחה הבאה:
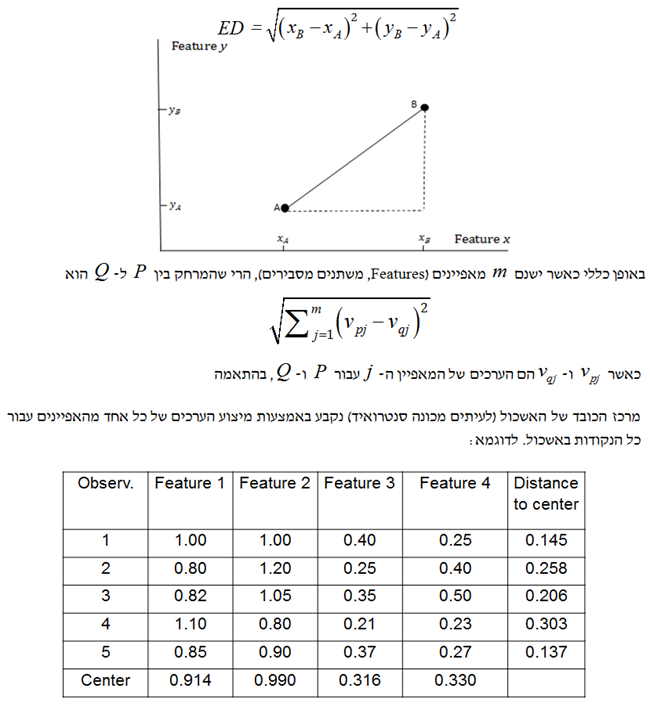
- בחירת ה- k
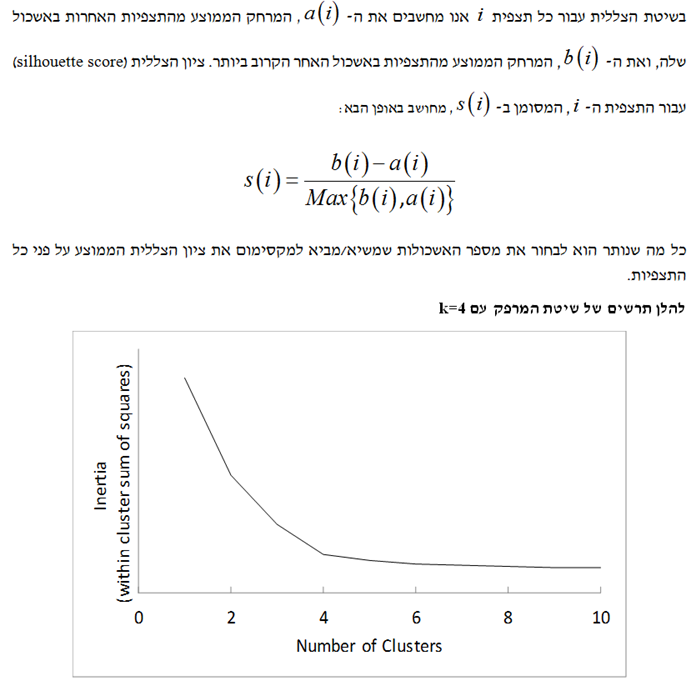
קיימות שלוש שיטות לבחירת ה- k: שיטת המרפק (Elbow Method), שיטת הצללית (Silhouette Method) ושיטת הפער (המשווה בין סכום ריבועי המרחקים בתוך האשכול לבין מה שהיה צפוי להתקבל באמצעות נתונים מקריים).
- צמצום ממדים (Dimensionality Reduction)
קללת הממדים הוא כינוי לתכונת מדד המרחק האוקלידי (ED) לפיה, ככל שמספר המאפיינים עולה כך עולה מדד המרחק האוקלידי.
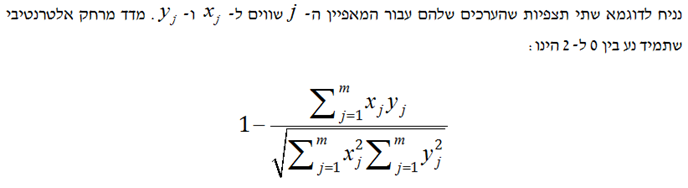
- אלגוריתמים לניתוח אשכולות (Clustering Algorithms)
קיימים ארבעה אלגוריתמים לניתוח אשכולות: 1) ניתוח אשכולות עם k-מרכזים (K-Means Clustering); 2) ניתוח אשכולות היררכי (Hierarchical Clustering); 3) ניתוח אשכולות מבוסס-צפיפות (Density-based Clustering); ו- 4) ניתוח אשכולות מבוסס-התפלגות (Distribution-based Clustering).
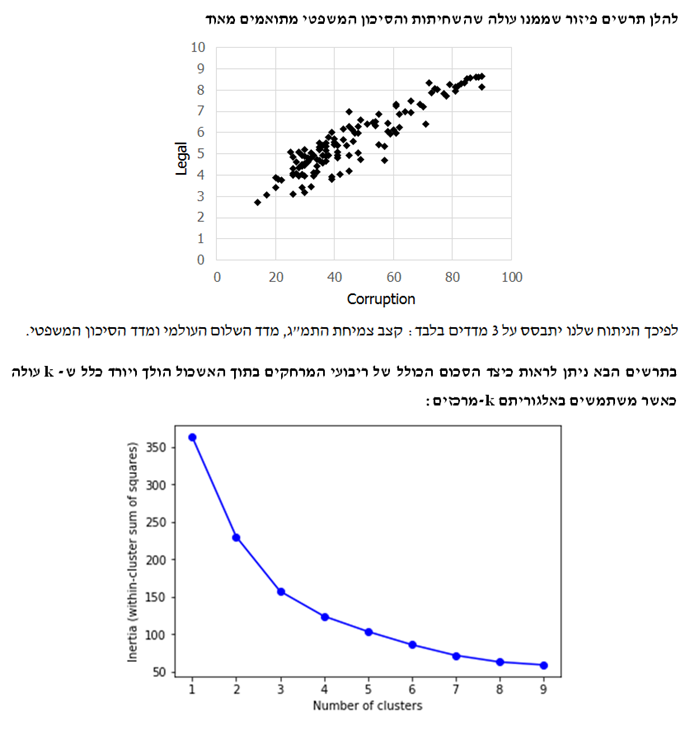
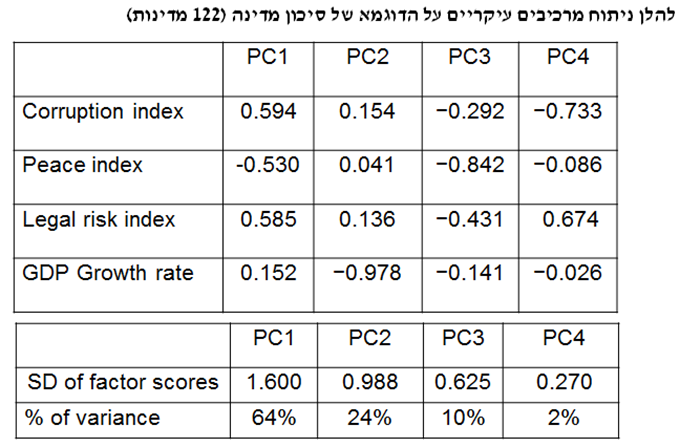
נציג דוגמא לניתוח אשכולות עם k-מרכזים. המטרה היא לבצע ניתוח אשכולות למדינות בהלימה למידת המסוכנות שלהם עבור השקעות זרות. בחרתי 4 מדדים לסיכון מדינה: 1) קצב צמיחת התמ"ג (GDP Growth Rate) מתוך נתוני קרן המטבע העולמית; 2) מדד השחיתות העולמי (Corruption Index) מתוך נתוני עמותת שקיפות בינלאומית; 3) מדד השלום העולמי (Peace Index) מתוך נתוני המכון לכלכלה ושלום; ו- 4) מדד הסיכון המשפטי (Legal Risk Index) מתוך נתוני ה- Property Rights Association.
אספתי נתונים אודות 122 מדינות וביצעתי קליברציה מסוג Z-score לערכי המאפיינים.
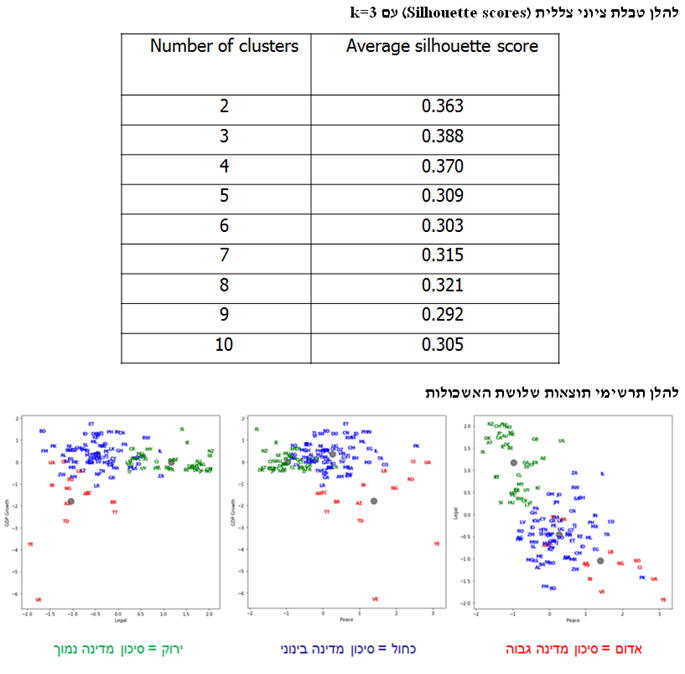
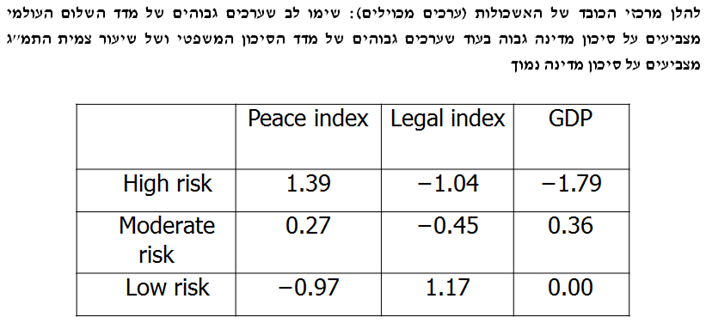
שיטה אחרת לניתוח אשכולות הינה ניתוח אשכולות היררכי. בשיטה זו אנו מתחילים עם כל אחת מהתצפיות באשכול משלה, לאחר מכן אנו משלבים בין שני האשכולות הקרובים ביותר ואנו ממשיכים לעשות כך עד לשילוב כל התצפיות לכדי אשכול יחיד. קיימים 4 מדדים למידת הקרבה של אשכולות (Closeness of Clusters) של אשכולות: 1) המרחק האוקלידי הממוצע בין נקודות באשכולות; 2) המרחק המקסימלי בין נקודות באשכולות; 3) המרחק המינימלי בין נקודות באשכולות; ו- 4) עלייה באינרציה (ורסיה של שיטת וורד – Ward's Method).
שיטה אחרת לניתוח אשכולות הינה הינה ניתוח אשכולות מבוסס-צפיפות. בשיטה זו אנו יוצרים למעשה אשכולות על בסיס מידת הקרבה של תצפיות בודדות. להבדיל מאלגוריתם k-מרכזים ניתוח אשכולות מבוסס צפיפות איננו מתבסס על מרכזי הכובד של האשכולות. בתחילה אנו עשויים לבחור 8 תצפיות קרובות. לאחר מכן נוסיף תצפית לאשכול אם הוא קרוב ל- 5 תצפיות אחרות לפחות באשכול, וחוזר חלילה.

בנוסף, ניתוח אשכולות מבוסס-התפלגות מניח כי התצפיות מגיעות מתמהיל של התפלגויות והוא עושה שימוש בנהלים סטטיסטיים על מנת להפריד בין ההתפלגויות השונות.
- ניתוח מרכיבים עיקריים (Principal Components Analysis)
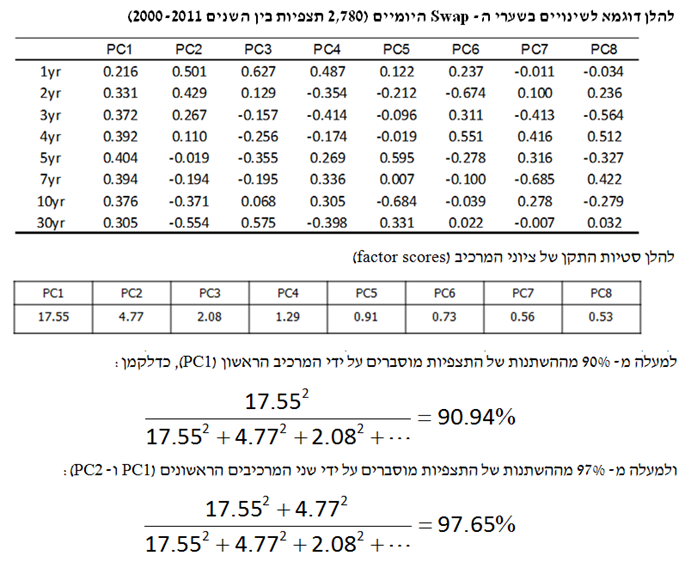
ניתוח מרכיבים עיקריים או בקיצור PCA היא גישה נוספת לצמצום ממדים (Dimensionality Reduction) או לצמצום מספר המשתנים.
ה- PCA מחליף קבוצה של n משתנים ב- n גורמים כך שכל אחת מהתצפיות של המשתנים המקוריים היא קומבינציה לינארית של n הגורמים, כאשר פעם אחת n הגורמים אינם מתואמים ופעם שנייה הכמות של גורם מסוים בתצפית מסוימת היא ציון הגורם (factor score). נעיר כי מידת החשיבות של גורם מסוים נמדדת באמצעות סטיית התקן של ציון הגורם שלו על פני התצפיות השונות.
הרעיון הוא לקחת מספר מסוים של משתנים מסבירים ולמצוא מתוכם את אלו שמסבירים אחוז גבוה מההשתנות של התצפיות.
- טבלאות תמותה (Mortality Tables)
טבלת תמותה (Mortality Table, לוח חיים) הינה תוצר של מחקר סטטיסטי המגדירה בין היתר את הסתברות המוות של אדם בכל גיל נתון. על מנת להתמודד עם השוני בין קבוצות שונות של אנשים ניתן לקבוע טבלאות תמותה נפרדים עבור קבוצות שונות. נדגיש כי מאחר שמדובר בטבלה סטטיסטית, הרי שהטבלה גופה מייצגת את המצב הממוצע, כלומר, את הסתברות המוות של האדם הממוצע על פני גילאים שונים.
טבלאות תמותה הן המפתח להערכת שווי חוזי ביטוח חיים וחוזי ביטוח פנסיוניים. הטבלאה הבאה מציגה קטע מתוך טבלת תמותה של הביטוח הלאומי האמריקאי (U.S. Department of Social Security).
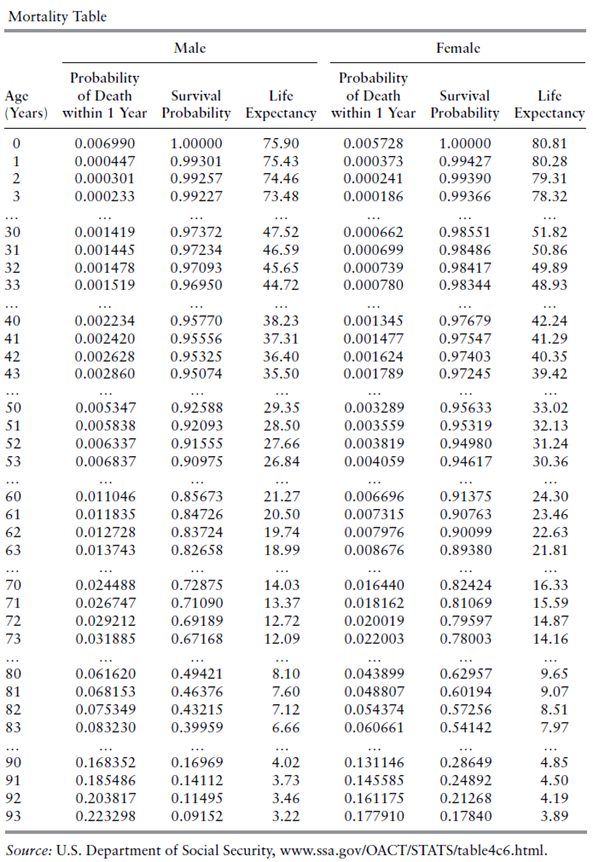
על מנת להבין את הטבלה, ניקח את השורה המתאימה לגיל 31. מהעמודה השנייה משמאל עולה כי ההסתברות של גבר בן 31 למות במהלך השנה הקרובה היא 0.001445 (או 0.1445%). מהעמודה השלישית משמאל עולה כי ההסתברות של תינוק שזה עתה נולד להגיע בחיים לגיל 31 היא 0.97234 (או 97.234%). מהעמודה הרביעית משמאל עולה כי יתרת תוחלת החיים של גבר בן 31 היא 46.59 שנים. המשמעות היא שהגיל הממוצע בעת מוות (Average Age at Death) עבור גבר בן 31 הוא 77.59. שלוש העמודות הנותרות מציגות נתונים סטטיסטיים דומים עבור אישה. ההסתברות של אישה בת 31 למות במהלך השנה הקרובה היא שנה היא 0.000699 (0.0699%), ההסתברות של תינוקת שזה עתה נולדה להגיע בחיים לגיל 31 היא 0.98486 (98.486%) ויתרת תוחלת החיים של אישה בת 31 היא 50.86 שנים, כלומר, הגיל הממוצע בעת מוות (Average Age at Death) עבור אישה בת 31 הוא 81.86.
הטבלה המלאה מראה כי ההסתברות למוות בשנה הקרובה היא פונקציה יורדת של הגיל עבור 10 השנים הראשונות של החיים ואז היא מתחילה לעלות. הנתונים הסטטיסטיים אודות תמותת נשים הם מעט טובים יותר מאלו של תמותת גברים. ההסתברות של גבר בן 90 למות במהלך השנה הקרובה היא כ- 16.8%, ההסתברות של גבר בן 100 למות במהלך השנה הקרובה היא כ- 35.4% וההסתברות של גבר בן 110 למות במהלך השנה הקרובה היא כ- 57.6%. אצל נשים, ההסתברות של אישה בת 90 למות במהלך השנה הקרובה היא כ- 13.1%, ההסתברות של אישה בת 100 למות במהלך השנה הקרובה היא כ- 29.9% וההסתברות של אישה בת 110 למות במהלך השנה הקרובה היא כ- 53.6%.

- לסיכום
למידת ללא השגחה עוסקת בהבנת דפוסים בתוך נתונים. באופן טבעי למידה ללא השגחה כרוכה בהתבוננות על אשכולות (Clusters), הווה אומר, על קבוצות של תצפיות דומות. לעיתים קרובות חברות עושות שימוש בלמידה ללא השגחה על מנת לנסות ולהבין טוב יותר את סוגי הלקוחות שלהן כך שהן תוכלנה לתקשר עמם בצורה יעילה יותר.
ביצוע קליברציה לערכי המאפיינים (Feature Scaling) הינו שלב מקדים (Precursor) לשלב ניתוח האשכולות (Clustering). ללא ביצוע קליברציה לערכי המאפיינים, השפעתו של מאפיין מסוים על ניתוח אשכולות תהיה בקנה המידה (Scale) אשר משמש למדידתו.
קיימות שתי גישות עיקריות לביצוע קליברציה לערכי המאפיינים. הגישה הראשונה נקראת קליברציה מסוג Z-score ובמסגרתה ערכי המאפיינים מותאמים כך שבסופו של דבר תהיה להם תוחלת של 0 וסטיית תקן של 1. הגישה השניה נקראת קליברציה מסוג Min-Max ובמסגרתה ערכי המאפיינים מותאמים כך שבסופו של דבר הם ינועו בין 0 ל- 1.
אלגוריתם ניתוח אשכולות דורש לדעת למדוד מרחקים (משהו שלמדנו מתישהו בתיכון). המדד הפופולארי ביותר עבור מרחק נקרא המרחק האוקלידי (Euclidian Distance) והוא מחושב כשורש הריבועי של סכום ריבועי ההפרשים שבין ערכי המאפיינים. מרכז הכובד של האשכול הינו נקודה המתקבלת על ידי מיצוע ערכי המאפיינים עבור כל התצפיות באשכול. אלגוריתם ניתוח האשכולות הפופולארי ביותר נקרא k-מרכזים (k-means). עבור ערך מסוים של k (מספר האשכולות), אלגוריתם ה- k-מרכזים ממזער את האינרציה (Inertia), המוגדרת כסכום ריבועי המרחקים בתוך האשכול בין התצפיות לבין מרכזי הכובד של האשכולות שלהן.
בחירת הערך הטוב ביותר עבור מספר האשכולות, k, איננה משימה קלה. גישה אחת לבחירת ה- k נקראת "שיטת המפרק" (Elbow Method) הגורסתת שיש להמשיך ולהעלות את ה- k עד להגעה לשיפור זניח יחסית באינרציה. גישה אחרת נקראת "שיטת הצללית" (Silhouette Method) והיא עורכת השוואה בין המרחק הממוצע של תצפית מסוימת מהנקודות האחרות באשכול שלה לבין המרחק הממוצע שלה מהנקודות באשכול האחר הקרוב ביותר. הגישה השלישית כרוכה בחישוב סטטיסטי הפער, אשר משווה את התצפיות שבתוך האשכולות (Clustered Observations) לתצפיות הנוצרות באופן אקראי.
ישנן מספר חלופות לאלגוריתם k-מרכזים. החלופה הראשונה נקראת ניתוח אשכולות היררכי (Hierarchical Clustering). בניתוח אשכולות היררכי אנו מתחילים ממצב שבו כל אחת מהתצפיות נמצאת באשכול שלה. לאחר מכן אנו מורידים באיטיות את מספר האשכולות על ידי צירוף אשכולות שקרובים אחת לשני לכדי אשכולות חדשים. החלופה השניה נקראת ניתוח אשכולות מבוסס-התפלגות (Distribution-based Clustering) והיא כרוכה בהתבוננות על אזורים שבהם הנתונים צפופים/דחוסים ללא קשר למרכזי הכובד של האשכולות.
ניתוח מרכיבים עיקריים (PCA- Principal Components Analysis) הוא כלי חשוב בלמידת מכונה. ניתוח מרכיבים עיקריים כרוך בהחלפת מספר גדול של מאפיינים במספר קטן יותר של מאפיינים המכונים "המאפיינים המסבירים ביותר" (Manufactured Features) אשר תופסים את מרבית ההשתנות של היעד (Target Variability, השתנות המשתנה המוסבר). נעיר רק שהמאפיינים המסבירים ביותר אינם מתואמים האחד עם השני.

הכותב רועי פולניצר הינו מדען נתונים (Data Scientist) העושה שימוש ב- Machine Learning לצורך פיתוח מודלים מתקדמים לניהול סיכונים (בדגש על אשראי קמעונאי) כגון מודלים מנבאי התנהגות לקוחות ו/או מודלי תחזיות בתחום ניהול הסיכונים, שיפור מודלים בתחום ניהול הסיכונים, ניתוח צרכים עסקיים בעולמות ניהול הסיכונים, אפיון פתרונות מתאימים באמצעות עבודה מול בסיס נתונים גדולים ויישום כלים אנליטיים מתקדמים בעולם הבינה המלאכותית, הערכת סיכוני מודל וניטור פעולות מתקנות, ניתוח ועיבוד גורמי סיכון עיקריים, וניתוח הבדלים בין חלופות ואיפיון גורמי סיכון.
ניסיונו של רועי בתחום ה- Data Analysis, כולל: עבודה עם מאגרי מידע גדולים Big Data תוך שימוש ב- Statistical Learning (כגון: סטטיסטיקה תיאורית, הסתברות, הסקה סטטיסטית, סטטיסטיקה א-פרמטרית, חלוקת נתונים, נרמול נתונים, Fitting ו- Bayes Theorem) ובאלגוריתמים מסוג Unsupervised Learning (כגון: k-means Clustering, Hierarchical Clustering, Density-based Clustering, Distribution-based Clustering ו- Principle Components Analysis) למציאת דפוסים וזיהוי מגמות ואנומליות בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, פיתוח תשתית לצורך ניתוח נתונים, שילוב והטמעת כלים לצורך גישה ושליפה עצמאית של נתונים ממאגרי מידע, פיתוח דוחות, ממשקים ומסכים באמצעות כלי ויזואליזציה.
ניסיונו של רועי בתחום ה- Data Science, כולל: עבודה עם מסדי נתונים גדולים Big Data תוך שימוש באלגוריתמים מסוג Supervised Learning (כגון: Linear Regression, Ridge Regression, Lasso Regression, Elastic Net Regression, Logistic Regression, Maximum Likelihood Estimation, k-Nearest Neighbors, Decision Tree, Random Forest, Ensemble, Bagging, Boosting, Naïve Bayes Classifier, Linear Separation, Support Vector Machine, Non-Linear Separation, SVM Regression, Artificial Neural Network, Convolutional Neural Network ו- Recurrent Neural Network) לניבוי וסיווג בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה ובמודלים מסוג Reinforcement Learning (כגון: Q-learning, Monte Carlo Simulation, Temporal Difference Learning ו- n-Step Bootstrapping) לקבלת החלטות מרובות שלבים בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, זיהוי אתגרים עסקיים שבהםDATA יכול להוות גורם מכריע בשיפור קבלת החלטות, איתור ואיסוף מקורות מידע, הגדרה ואיפיון של שימושי המידע, בניית מסד המידע, אפיון והגדרת הצגת המידע ותוצריו, פיתוח כלים, מודלים, תהליכים ומערכות בתחום האנליזה, תוך שימוש בכלי אנליזה מתקדמים (EXCEL, VBA ושפת R).
מגזין "סטטוס" מופק ע"י:
Tags: אקטואריה כלכלה מימון


