





























































נפגשתי עם חוקר מדע הנתונים ומדען הנתונים רועי פולניצר בעליו של משרד הייעוץ הסטטיסטי "פרדיקציות יועצים", המתמחה בין היתר בבניית מודלים סטטיסטיים לטובת פתרון בעיות עסקיות, ביישום שיטות ניתוח סטטיסטי מתקדמות כולל Machine Learning על מסדי נתונים גדולים תוך עבודה עם כלי מחשוב מבוזרים ובפיתוח כלי סימולציה ואופטימיזציה בשפות Python ו- R – להרמת כוסית לרגל ערב פסח ולראיון קצר. רועי הינו מייסד ומנכ"ל האיגוד הישראלי למדעני נתונים מקצועיים (PDSIA) ואני מתעניין מאוד בבינה מלאכותית
פורסם: 5.4.21 צילום: יח"צ
רועי עוסק מזה כ-15 שנים בתחומי הנתונים, האלגוריתמיקה, והבינה המלאכותית (או בשמה האקדמי "אקונומטריקה") – הן ברמה הן ברמה הפרקטית (בתעשייה). במשך 4 שנים מתוך אותן 15 שנים רועי שימש כעוזר מחקר אקונומטרי של ד"ר שילה ליפשיץ המנוח, כלומר, כחוקר מדע נתונים. במסגרת תפקידו כחוקר מדע נתונים. רועי ערך מחקרי מידע מעמיקים על מנת להפיק תובנות עסקיות וכלכליות, ניקה, טייב וסידר את המידע ששימש למחקרים השונים, הפעיל אלגוריתמים שונים של מידול, כריית מידע ואקונומטריקה (כיום Machine Learning או למידת מכונה) על המידע והוביל את תהליכי הכנת המידע ואופטימיזציה של האלגוריתמים השונים.
מהי אקונומטריקה?
אקונומטריקה מודדת קשרים כלכליים. באקונומטריקה, או מה שקוראים היום Data Science השיטה הבסיסית היא שאני כחוקר מדע נתונים. מגדיר תחילה השערה (היפוטתזה) שאני מצפה שתאשש או שתפריך את התוצאות האקונומטריות שאקבל. לאחר מכן אני אוסף נתונים ומנסח מודל מסוים, שלאחר מכן נאמד, והתוצאות האקונומטריות המתקבלות מספקות לי ממצאים אשר מאששים או מפריכים את המודל שבניתי.
האם אתה כחוקר מדע נתונים חוקר רק מודל אחד?
שאלה טובה. כחוקר מדע נתונים אני רשאי לחקור מספר סוגי מודלים על מנת לראות אלו מביניהם הוא הטוב ביותר הן מבחינה תיאורטית והן מבחינה פרקטית. לבסוף, כחוקר מדע נתונים אני עושה שימוש בתוצאות המודל לצורך ביצוע תחזיות.
האם תוכל לתאר בבקשה את המתודולוגיה האקונומטרית?
בוודאי. ישנם 8 שלבים במתודולוגיה זו, כאשר אני מסתכל עליהם כעל שמונת התפקידים של חוקר מדע נתונים.
מהו השלב הראשון?
לשלב הראשון או לתפקיד הראשון, זה היינו הך, אני קורא "קביעת ההשערה הנבחנת בהתבסס על התיאוריה המונחת". שלב זה יכול להיות פשוט ממש כמו לבדוק את התיאוריה לפיה, קיים קשר בין הכמות המבוקשת למחיר (קרי, כלל הביקוש). אני כחוקר מדע נתונים מתחיל בהשערה ש"אין כל קשר בין הכמות המבוקשת למחיר" כאשר מטרתו של היישום האקונומטרי אחת היא – לשלול את ההשערה הזו. כמובן שאני יכול לבחון אינספור השערות (למשל, "אין כל קשר בין שערי הריבית במדינות שונות לשערי החליפין"). כמו במקרה הראשון, גם כאן אני בדרך כלל מקווה לשלול את ההשערה. במהלך התהליך, אני כחוקר מדע נתונים יכול לקבל אומדנים לקשר האמיתי (למשל, עבור כל עליה של שקל במחיר, הכמות המבוקשת קטנה בסכום נתון מסוים).
ברשותך אני רוצה לתת כותרת לשלב הראשון במתודולוגיה האקונומטרית

מהו השלב השני?
לשלב השני אני קורא "איסוף הנתונים". בשלב זה אני כחוקר מדע נתונים אוסף נתונים ראויים או הולמים. כמובן, שהנתונים הנאספים חייבים להתייחס להשערה הנבחנת (למשל, עבור בחינת כלל הביקוש, עליי להשתמש בנתונים אודות הכמויות הנמכרות והמחירים).
כמובן שאחת הסוגיות בשלב זה היא האם לאסוף נתוני סדרה-עתית, נתוני חתך-רוחב או נתונים מאוגמים? האם לאסוף רק נתונים כמותיים או גם נתונים איכותיים?.
בנוסף, עליי כחוקר מדע נתונים להכיר מקורות מידע רבים שמהם אני יכול לכרות נתונים. האינטרנט מספק כיום מגוון אדיר של אתרים אשר מהם ניתן להוריד נתונים. כך למשל, ממשלת ארה"ב מממנת אתרים רבים המספקים סטטיסטיקות בנוגע לדמוגרפיה, תעסוקה, מחירים וכו'. הפדראל ריזרב מספק משתנים מוניטריים כמו למשל שערי ריבית ונתונים בדבר כמות הכסף. כמובן שאני כחוקר מדע נתונים יכול גם לקנות נתונים ממקורות פרטיים (למשל, תחזיות הנבנות על ידי פירמת חיזוי הן דוגמא למידע שנרכש).
זרקת כאן כמה מושגים. מהם נתוני סדרה-עתית?
נתוני סדרה-עתית ((Time Series data מייצגים צמדי תצפיות של מחיר וכמות עבור מוצר מסוים על פני תקופות זמן. ברגיל, התקופות הן יומיות, שבועיות, חודשיות, רבעוניות, חצי שנתיות או שנתיות. צמד התצפיות הראשון מייצג את המחיר והכמות בתקופה הראשונה, הצמד השני מייצג את המחיר והכמות בתקופה השנייה, וכך הלאה. למעשה כחוקר מדע נתונים אני מוגבל על ידי מקור הנתונים האם להשתמש בנתונים יומיים, חודשיים וכו'. עבור כלל הביקוש, ככל הנראה לחוקר נדרשים לכל הפחות נתונים חודשיים היות והמוצר נמכר על פני זמן. אעיר כי הגם שנתונים אחרים מתקבלים על בסיס יומי (למשל, מחירי מניות ושערי ריבית), עדיין אני כחוקר מדע נתונים יכול לבחור לעשות בהם שימוש גם במרווחים ארוכים יותר.
מהם נתוני חתך-רוחב?
נתוני חתך-רוחב ((Cross-sectional data מייצגים צמדי תצפיות של מחיר וכמות בנקודת זמן מסוימת אולם באזורים גיאוגרפים שונים. כחוקר מדע נתונים אני עשוי יכול להשיג מחירים וכמויות נמכרות עבור כל עיר בישראל, הווה אומר 77 תצפיות (כנגד 77 ערים בישראל נכון ל- 2020). הנתונים כולם מתייחסים כאמור לנקודת זמן מסויימת (נניח 31 בדצמבר 2020).
מהם נתונים מאוגמים?
מערך נתונים מאוגמים (Pooled data) כולל מערך של תצפיות חתך-רוחב על פני מספר תקופות זמן. לדוגמא, עבור כל אחת מהשנים כחוקר מדע נתונים אני אוסף מערך של קשרים בין המחיר לכמות על פני 77 ערים. אם אני אוסף נתונים שנתיים על פני 10 שנים, אז יהיו לי 770 צמדי תצפיות של מחיר וכמות. נתוני פאנל (Panel data) הם סוג אחד של נתונים מאוגמים כאשר אני כחוקר מדע נתונים מסתכל על יחידה מסוימת של תצפיות, כמו למשל משפחה, ומתעד את השינויים עבור כל אחד מבני המשפחה על פני זמן. נתונים אלו יכולים לתעד את הדינמיקה של המשפחה על פני זמן.
ברשותך אני רוצה לתת כותרת לשלב השני במתודולוגיה האקונומטרית

מהו השלב השלישי?
לשלב השלישי אני קורא "איפיון המודל או הייצוג המתמטי של התיאוריה". עבור היצע וביקוש, הייצוג המתמטי הוא:
Quantity = a + b x Price
באמצעות Q ו- P עבור כמות ומחיר בהתאמה, אני כחוקר מדע נתונים יכול לייצג את הקשר כסדרה-עתית באופן הבא:
Qt = a + b x Pt
כאשר "t" מציין את האופן שבו המשתנה שלנו משתנה על פני זמן. עבור נתוני חתך-רוחב, המודל עשוי להשתמש ב- "i" חלף ב- "t", כאשר הכתב התחתי מייצג את הערים השונות, כגון: אופקים, אור יהודה, אור עקיבא וכו'.
הערה אינפורמטיבית: על מנת להתאים את גודל האוכלוסיה המשתנה על פני הערים השונות, אני כחוקר מדע נתונים מקפיד להשתמש בכמות המבוקשת פר אדם או פר תושב.
האיברים a ו- b נקראים פרמטרים, והם המדדים של הקשר שבין המשתנה שבצד שמאל (קרי, המשתנה התלוי או המשתנה המוסבר) והמשתנה שבצד ימין (קרי, המשתנה הבלתי תלוי או המשתנה המסביר). לעיתים קרובות, במשוואת הרגרסיה, הפרמטרים הללו מוצגים כאלפא α, וביתא β, בהתאמה. האלפא מייצגת את מקדם החותך (a, α או b0), והביתא מייצגת את מקדם השיפוע (b, β או b1). כמובן שיכולים להיות מספר משתנים בלתי תלויים בצד ימין ולא רק משתנה אחד.
ברשותך אני רוצה לתת כותרת לשלב השלישי במתודולוגיה האקונומטרית

מהו השלב הרביעי?
לשלב הרביעי אני קורא "איפיון המודל האקונומטרי של התיאוריה". המודל האקונומטרי חייב להתייחס לתכונות הספציפיות של הקשר כמו למשל לאופן שבו המקדמים שנאמדו עשויים להשתנות ממדגם אחד למשנהו. תכונה אחרת שיש לתת עליה את הדעת היא העובדה שהמודל איננו "דטרמיניסטי" (קרי, הוא איננו מייצג קשר מדויק). התקנון הבסיסי ביותר להתאמת הסוגיה הזו הינו על ידי הוספת "איבר שגיאה" מסוים למשוואה:
Qt = a + b x Pt + et
על המודל האקונומטרי להניח שלאיבר השגיאה, et, ישנן תכונות ספציפיות שעליהן לא נרחיב במסגרת ראיון זה.
ברשותך אני רוצה לתת כותרת לשלב הרביעי במתודולוגיה האקונומטרית

מהו השלב החמישי?
לשלב החמישי אני קורא "אמידת הפרמטרים". כחוקר מדע נתונים אני מחשב את האומדנים באמצעות נהלים נאותים. שיטת הריבועים הפחותים (OLS- Ordinary Least Squares) היא הנוהל הפופולארי ביותר. קיימות חבילות תוכנה רבות, כולל גיליונות אלקטרוניים, אשר יכולים לחשב במהירות את אומדני ה- OLS של המקדמים במודל. ה- OLS מספקת משוואה שממזערת או מביאה למינימום את סכום ריבועי איברי השגיאה. הערכים של a ו- b אשר מתקבלים מנוהל ה- OLS הם האומדנים של הקשר האמיתי.
הערה אינפורמטיבית: קיימים נהלים מתוחכמים יותר אשר מביאים בחשבון את התכונות של איברי השגיאה, ברם הם לעיתים קרובות מניבים תוצאות הדומות מאוד לתוצאות ה- OLS.
ברשותך אני רוצה לתת כותרת לשלב החמישי במתודולוגיה האקונומטרית

מהו השלב השישי?
לשלב השישי אני קורא "בחינת האיפיון של המודל". ה"איפיון" פירושו הבחירה של משתני הכניסה (Input variables). במקרה של מודל הכמות המבוקשת, כחוקר מדע נתונים אני עשוי לרצות לדעת האם גם משתנים אחרים (מלבד המחיר) עשויים למלא תפקיד בחיזוי הכמות המבוקשת. לפיכך, אני עשוי להוסיף מרכיב של הכנסה ולאמוד את המשוואה הבאה:
Qt = a + b1 x Pt + b2 x It + et
כאשר "I" מייצג את הכנסתו של הצרכן. כחוקר מדע נתונים אני עשוי גם לבחור לחקור האם התמרות שונות של הנתונים (למשל, המרת הנתונים ללוגריתמים טבעיים) עשויות לשפר את התוצאות.
ברשותך אני רוצה לתת כותרת לשלב השישי במתודולוגיה האקונומטרית

מהו השלב השביעי?
לשלב השביעי אני קורא "בחינת ההשערות". כחוקר מדע נתונים אני מתחיל עם ההשערה הנבדקת. משעה שהאיפיון הטוב ביותר של המודל נקבע ונאמד, אני יכול להתחיל לבחון האם הסטטיסטיים מתוך המודל (קרי, הפונקציות של התצפיות במדגם) מאששים או מפריכים את ההשערה הנבדקת. במקרה של כלל הביקוש, ההשערה היא שאין כל קשר בין הכמות המבוקשת למחיר. התוצאות יספקו ממצאים לדחיית או לחילופין לאי דחיית התיאוריה האמורה. במקרה שמקדם השיפוע גבוה דיו, בערכים אבסולוטיים, והשגיאה הנאמדת הינה קטנה למדי, אני כחוקר אדחה את ההשערה ואסיק כי הקשר אכן קיים.
כחוקר מדע נתונים אני גם יכול לבחון מצב של ערכים השונים מאפס. כך למשל, אני יכול לבדוק האם מקדם השיפוע שווה למינוס אחד, והתוצאה יכולה גם כן לתמוך או לדחות את ההשערה הנבדקת.
ברשותך אני רוצה לתת כותרת לשלב השביעי במתודולוגיה האקונומטרית

מהו השלב השמיני והאחרון במתודולוגיה האקונומטרית?
לשלב השמיני והאחרון אני קורא "שימוש במודל לצרכי ניבוי". כחוקר מדע נתונים אני רוצה להשתמש במודל על מנת לייצר תחזיות. לדוגמא, חברה מסוימת עשויה לשכור את שירותיי כחוקר מדע נתונים על מנת לאמוד את הקשר שבין המחיר של מוצר החברה לבין הכמות הנמכרת שלו. המטרה תהיה לנבא כיצד הכמות הנמכרת תשתנה בהינתן שינוי במחיר. במקרה זה, כחוקר מדע נתונים אני יכול לעשות שימוש במודל הנאמד על מנת לקבוע האם העלאת מחירים היא רעיון טוב או לא.
הערה אינפורמטיבית: כחוקר מדע נתונים אני מקפיד להזכיר לעצמי שכל התחזיות נתונות לטעות חיזוי, וכי ההכנסה בפועל במרבית המקרים תהיה שונה מזו הנחזית.
ברשותך אני רוצה לתת כותרת לשלב השמיני והאחרון במתודולוגיה האקונומטרית

הזכרת מקודם נתונים כמותיים ונתונים איכותיים, תרצה להרחיב?
וודאי. תכונה אחרת של נתונים מלבד סדרות עתיות או נתוני רוחב היא האם הם כמותיים או איכותיים. במשוואת הכמות, הן הכמות והן המחיר מעידים על כמויות, ממש כמו ההכנסה. כל אחד מהמשתנים הללו יכול לעלות או לרדת בדרגות שונות. משתנה איכותי הוא בדרך כלל "משתנה מסוג הכל או כלום" המציין תנאי. בעת אמידת סדרה עתית של משוואת הכמות המבוקשת, כחוקר מדע נתונים אני עשוי לרצות לבחון האם קיים הבדל כלשהו בצריכה של המוצר כאשר ראש העיר הוא שמאלני (נציג של מפלגת שמאל) או ימני (נציג של מפלגת ימין), למשל, ברוח הבחירות. דבר זה יכול לתת אינדיקציה ל"מצב הרוח" העיר. משתנה "מצב רוח" שכזה יכול להיות מסומן באמצעות האות M, כאשר M=0 בתקופות שבהן ראש העיר הוא שמאלני ו-M=1 כאשר ראש העיר הוא ימני. ואז נקבל את המשוואה הבאה:
Qt = a + b1 x Pt + b2 x It + b3 x Mt + et
משתנים כמו למשל M נקראים משתני דמה או משתנים קטגוריאליים.
אז כיצד אתה מאפיין למעשה המודל האקונומטרי?
אם אתה זוכר ברשימה של 8 השלבים של המתודולוגיה האקונומטרית, בשלבים 3 ו- 4 אמרתי שאני מאפיין את המודל. לאורך התהליך, כחוקר מדע נתונים אני מפרש ומתקף את המודל. איפיון המודל מתייחס לקביעת נתוני הקלט (Inputs). אם אתה זוכר, בדוגמא הקודמת, השתמשתי תחילה במחיר על מנת להסביר את הכמות, אך לאחר מכן הבאתי בחשבון גם את הכנסת הצרכן. משתנה נוסף, שעשוי לעניין אותי כחוקר מדע נתונים יכול להיות מחירו של מוצר תחליפי.
כיצד אתה נותן פרשנות למודל האקונומטרי?
כמובן שאני כחוקר מדע נתונים רוצה לבדוק את הסימנים של הפרמטרים. במשוואת הביקוש:
Qt = a + b1 x Pt + b2 x It + et
אני כחוקר מדע נתונים רוצה לבדוק האם אכן b1 < 0 וגם b2 > 0, כמתיישב ועולה בקנה אחד עם התכונות הבסיסיות הקשורות לכלל הביקוש. לאמור- b1 < 0 פירושו שכאשר המחיר עולה הכמות המבוקשת יורדת, ו- b2 > 0 פירושו שכאשר ההכנסה עולה הכמות המבוקשת עולה גם כן.
כחוקר מדע נתונים אני מפרש את הערך והעוצמה של כל אחד מהפרמטרים. כך, למשל ערך של b1 = -1,000 פירושו שעבור כל עליה במחיר, נגיד של 1 ש"ח, הכמות המבוקשת תקטן ב- 1,000 יחידות.
מה לגבי תיקוף או בחינת התקפות של המודל האקונומטרי?
מבלי להיכנס לנושאים כמותיים מסובכים, אומר שכחוקר מדע נתונים אני משתמש במבחנים הבודקים האם הקשר שמתואר על ידי תוצאות המודל אכן יכול היה להתרחש במקרה, או אם לאו, כמו גם עד כמה טובה יכולת הניבוי של המודל. תוצאות המבחנים הללו הן שיעידו, הן שיגידו האם המודל שבניתי אכן תקף מבחינה סטטיסטית או שעליי לשקול איפיונים נוספים.
איך היית מסכם את האקונומטריקה ב- 3 נקודות?
הנקודה ראשונה היא שהאקונומטריקה מודדת את הקשרים בין משתנים. שישנם 8 שלבים העוסקים בהערכת קשרים בין משתנים. השלבים הללו כוללים: קביעת ההשערה הנבחנת בהתבסס על התיאוריה המונחת, איסוף הנתונים, איפיון המודל או הייצוג המתמטי של התיאוריה, איפיון המודל האקונומטרי של התיאוריה, אמידת הפרמטרים, בחינת האיפיון של המודל, בחינת ההשערות ושימוש במודל לצרכי ניבוי.
הנקודה השניה היא שקיימים שלושה סוגים של נתונים שניתן לאסוף: נתוני סדרה-עתית, נתוני חתך-רוחב ונתונים מאוגמים. נתוני סדרה-עתית הם נתונים על פני זמן, נתוני חתך-רוחב הם נתונים מאזורים שונים לאותה תקופת זמן ונתונים מאוגמים משלבים את העקרונות של נתוני סדרה-עתית ונתוני חתך-רוחב.
הנקודה השלישית היא שאיפיון, פרוש ותיקוף המודל חשובים ללא שום קשר לבחינת ההשערה הנבדקת. איכות התוצאות היא פונקציה עולה של איכות המודל והנתונים המשמשים לבניית המודל.
האם תוכל לתת דוגמא לפרוייקט אקונומטרי פרקטי?
וודאי. נניח לרגע שחברת ביטוח מעוניינת לבטח דירות ברחבי הארץ ובכדי לתמחר את ביטוחי הדירות (לאו דווקא בצורה לגיטימית…), עליה לבנות מודל AI לשיערוך פרמיות ביטוח דירה. חברת הביטוח פונה אליי כמדען נתונים על מנת שאייצר לה כלי שכזה שישמש אותה ביום-יום.
על פניו מדובר בבעיית שערוך קלאסית:

מה הלקוח מצפה ממך בפרוייקט שכזה?
הלקוח (חברת הביטוח במקרה דנן שלפנינו) מצפה ממני לרוב ל- 4 דברים: 1) לאסוף נתונים רלוונטיים; 2) לבנות מודל שיערוך (טוב); 3) לתת הערכה לגבי השגיאה הצפויה; ו- 4) להסביר למנכ"ל על מה הוא שילם.
מהו השלב הראשון בפרוייקט שכזה?
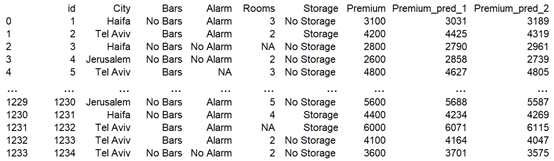
השלב הראשון מבחינתי כמדען נתונים הוא איסוף והכנת הנתונים. ברגיל, המידע הזמין והמעודכן ביותר נמצא אצל הלקוח. במקרים רבים המידע הגולמי אינו "נקי" ויש לעבד אותו. בעת העיבוד אני מתמודד עם סוגיות של נתונים חסרים (מוקפים בכחול), שגיאות (מוקפות באדום), כפילויות ועוד.

בסופו של דבר אני מייצר טבלת נתונים premiums "נקייה" ומוכנה לעבודה
באיזה מודל אקונומטרי היית משתמש בפרוייקט שכזה?
המודל שהייתי בוחר בו לשערוך הינו מודל הרגרסיה הלינארית. בבעיות רגרסיה אנו מניחים שקיים קשר ידוע כלשהו (נוסחה) הקושר בין המשתנים המסבירים לבין המשתנה המשוערך. ברגרסיה לינארית מניחים שהקשר הזה הוא לינארי
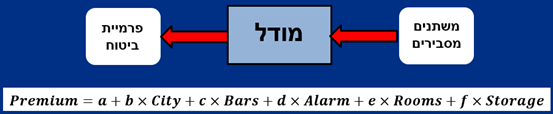
כיצד נבחרים המקדמים במודל שלך?
המקדמים נבחרים באופן אופטימלי, כך ש"השגיאה הממוצעת" (המרחק מהנתונים לשערוך) קטנה ככל האפשר

מה קורה כאשר יש לך משתנים מסבירים איכותיים?
כאשר ישנם משתנים מסבירים קטגוריאליים, הופכים אותם למספריים באמצעות משתני "דמה" (dummy). למשל, הפרמטר Rooms הינו נומרי ולכן אין צורך להמיר אותו, אולם שווה לבדוק האם ניתן לשפר את המודל אם מתייחסים ל- Rooms כאל משתנה קטגוריאלי במקום כמשתנה נומרי.
משעה שבנית מודל, מה לגבי תיקוף המודל?
על מנת לתקף את המודל שבניתי עליי כמדען נתונים לבדוק את ביצועיו על נתונים חדשים. על פי רוב, אני מחלק את הנתונים הקיימים לשתי קבוצות: 1) קבוצת "אימון" (train set) המשמשת לאימון המודל; ו- 2) קבוצת "ביקורת" (test set) המשמשת לתיקוף המודל.
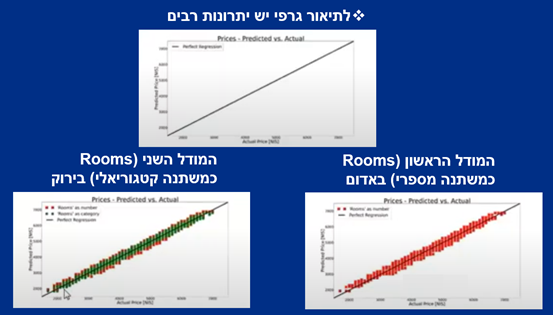
כיצד מקובל להציג את התוצאות?
ברגיל, התוצאות המספריות הן העיקר, אבל קשה לקבל מהן אינטואיציה.
לפיכך, לתיאור גרפי יש יתרונות רבים
וכאן מסתיים הפרוייקט שלך?
ממש לא. אל תשכח שבסוף התהליך ישנו משתמש-קצה שצריך להשתמש במודל ולכן עליי כמדען נתונים לדאוג לייצר עבורו כלי אינטואיטיבי ונוח לשימוש כמו גם ללוות את המשתמשים בכלי ניבוי זה.

מר רועי פולניצר הינו חוקר בתחום ה-AI העוסק במחקר וכתיבת אלגוריתמים על כמויות גדולות של מידע, תוך שליטה מלאה בספריות PANDAS ,NUMPY בשפת PYTHON ובחבילות הפיתוח שלה Tensorflow ,Keras ו- Scikit learn.
למר פולניצר ניסיון מוכח ומומחיות בתחומים Image, ML/DL ,Audio ,Video ,NLP וזיהוי אנומליות ובעבודה עם DOCKER בסביבת ענן ציבורי על GPU.
לרועי תואר ראשון ושני במסלול DATA (מדע נתונים ולמידת מכונה) בהצטיינות מאוניברסיטה מובילה עם שקיל תזה בתחום ה- DEEP LEARNING.
מגזין "סטטוס" מופק ע"י:


