





























































מאמר מס' 9 בסדרה
פורסם: 25.3.20 צילום: יח"צ
- הקדמה
סדרת מאמרים זו מבוססת על נסיוני כמדען נתונים (Data Scientist) המתמחה בתחום למידת המכונה (ML- Machine Learning) בעולמות המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה.
חלק מהאלגוריתמים של ML למדתי בתואר הראשון שלי בכלכלה (כגון: הטיה מול שונות, בעיות רגרסיה מול בעיות סיווג, חלוקת נתונים ל- Training set ו- Testing set, נרמול נתונים, רגרסיה לינארית, Ridge, Lasso ו- Elastic Net, יישומי אלגברה לינארית בתוכנת Excel וכו'), חלק בקורסים לתואר שני בכלכלה (כגון: Dimensionality Reduction, Principle Components Analysis, K-Mean Cluster Analysis, Hierarchical Cluster Analysis ו- Time Series וכו'), חלק בתואר השני שלי במימון (כגון: Decision Trees, Random Forest, Monte Carlo Simulation, Bootstrapping, Cubic-Spline, Nelson-Siegel-Svensson וכו'), חלק למדתי בלימודי התעודה באקטואריה (המסווג הנאיבי של בייס, Overfitting, ,Underfitting Convolution and Pooling, תכנות מדעי וסטטיסטי בשפת R וכו'), חלק למדתי בלימודי התעודה בניהול סיכונים פיננסיים ועל חלק אף נבחנתי במבחנים הבינלאומיים להסמכה בתחום ניהול הסיכונים הפיננסיים FRM (כגון: רגרסיה לוגיסטית, Logit, Probit,LDA , K-Nearest Neighbor ו- Support Vector Machines וכו') ואת היתר למדתי עצמאית באינטרנט (כגון: Neural Networks, Ensemble, Bagging, Boosting, תכנות בשפת VBA וכו').
כמובן שההבנה העמוקה שלי באלגוריתמים של ML נשענת הן על הידע שלי בסטטיסטיקה (הכולל בין היתר: סוגי נתונים והצגתם באופן טבלאי וגרפי, מדדי מרכוז ומדדי פיזור, אחוזונים, מדדי קשר, התפלגות הנתונים, הסתברות פשוטה במרחב הסתברותי אחיד ובמרחב הסתברותי לא אחיד, הסתברות מותנית, נוסחת בייס, משתנים מקריים בדידים: ניסויי ברנולי, התפלגות בינומית, התפלגות פואסונית, התפלגות גיאומטרית, התפלגות היפרגיאומטרית, משתנים מקריים רציפים: התפלגות נורמלית, הסקה סטטיסטית, אמידה נקודתית, רווחי סמך, מבחני השערות וסטטיסטיקה א-פרמטרית) והן על הידע שלי בתורת הקבוצות (הכולל בין היתר: מערכות משוואות לינאריות, וקטורים ב- R^n, מטריצות ריבועיות, מטריצות אלמנטריות, מרחבים וקטורים, מרחבי מכפלה פנימית, אורתוגנליות, דטרמיננטות, ערכים עצמיים, וקטורים עצמיים, לכסון, תבניות ריבועיות, משוואות הפרשים, תכונות טופולוגיות של קבוצות במרחב אוקלידי, קבוצות קמורות, משפטי הפרדה, פונקציות קמורות וקעורות, תכונות ואפיונים, שנאת סיכון, אופטימיזציה של פונקציות עם ובלי אילוצים, משפט הפונקציות הסתומות, משפט המעטפת, משוואות דיפרנציאליות מסדרים שונים, מערכות של משוואות דיפרנציאליות ושיטות של אופטימיזציה דינאמית).
מטרתה של סדרת מאמרים זו היא להקנות לקורא הבנה מה עושים מדעני נתונים (Data Scientists) נתונים וכיצד הם יכולים לקדם את מטרות הארגון. מרבית אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה מכירים בכך שהם זקוקים לידע מסוים בתחום ה- ML על מנת לשרוד בעולם שבו מספר מקומות העבודה מושפע יותר ויותר מתחום זה. כיום, כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה צריכים לדעת לעשות שימוש בתוכנת Excel ולדעת לתכנת ברמה מסוימת ב- VBA. מחר כבר כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה יצטרכו לדעת לעבוד עם מאגרי נתונים גדולים (Big Data) תוך פיתוח ושימוש באלגוריתמים של ML על מנת לזהות כיוונים ומגמות בעולמי התוכן שלהם או במגוון תחומים לרוחב הארגון.
בסדרת מאמרים זו חסכתי מהקורא את השימוש בתורת הקבוצות (קרי, מטריצות ווקטורים), למרות שלעניות דעתי אלגברה לינארית חיונית ביותר על מנת להגיע להבנה עמוקה ולשליטה ברמה גבוהה ב- ML.
לסיכום, סדרת מאמרים זו מציגה את הכלים, המודלים והאלגוריתמים הפופולריים ביותר שבהם משתמשים כיום מדעני נתונים.
- סיכום המאמר הקודם: אלגוריתם יער אקראי (Random Forest) ושיטות מורכבות (Ensemble Learning)
לעיתים נעשה שימוש ביותר מאלגוריתם אחד של למידת מכונה על מנת לבצע חיזוי. לאחר מכן ניתן לשלב את התוצאות המתקבלות מהאלגוריתמים השונים. זה נקרא שימוש בשיטות מורכבות. במקרה של סיווג ניתן להשתמש בהליך הצבעת הרוב. אם מרבית האלגוריתמים מנבאים תוצאה מסוימת, הרי שניתן לבחור בתוצאה זו כתוצאה החזויה. במקרה של חיזוי של משתנה נומרי, ניתן למצע את התוצאות המתקבלות מאלגוריתמים שונים על מנת לבצע חיזוי מורכב.
אלגוריתם יער אקראי הינו אלגוריתם של למידת מכונה הנוצר על ידי בניית עצי החלטה רבים ושילוב התוצאות המתקבלות מהם באופן שתואר לעיל. את העצים ניתן ליצור על ידי דגימה מתוך התצפיות, לחילופין באמצעות דגימה מתוך המאפיינים או לחילופי חילופין על בסיס דגימה משניהם ביחד. בנוסף, ניתן לייצר עצים על ידי הגרלה מקרית של רמות סף.
Bagging הוא המונח המשמש כאשר משתמשים בתתי-קבוצות שונות של התצפיות שבסט האימון ליצירת מודלים מרובים. Boosting היא שיטה מורכבת שבמסגרתה מודלי חיזוי נבחרים ברצף, כאשר כל מודל נועד לתקן את השגיאות של המודל הקודם. בעת סיווג אחת הדרכים לעשות זאת היא להגדיל את משקלן של התצפיות שלא סווגו נכונה. דרך נוספת היא להשתמש בלמידת מכונה לניבוי השגיאות שהתקבלו במודל הקודם.
- המסווג הנאיבי של בייס (Naïve Bayes Classifier)
הזכרנו את משפט בייס במאמר מס' 2 בסדרה שכותרתו "מבוא ללמידת מכונה (Machine Learning)". למידה בייסיאנית כרוכה איך לא בשימוש במשפט בייס על מנת לעדכן הסתברויות. לצורך הדוגמא, הראנו במאמר מס' 2 כיצד משפט בייס יכול לסייע לזהות עסקאות הונאה.
ניתן להתייחס אל העץ שהוצג במאמר מס' 7 בסדרה שכותרתו "אלגוריתם עצי החלטה (Decision Trees)" כדוגמא ללמידה בייסיאנית.
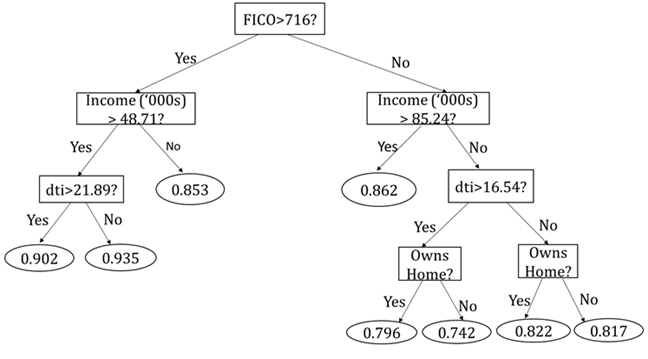
ההסתברות להלוואה טובה בסט האימון ללא מידע אודות המאפיין היא 0.8276. ההסתברות שציון ה- FICO יהיה גבוה יותר מ- 716 המותנית בכך שהלוואה היא טובה הינה 0.2076 וההסתברות שאיננה מותנית בציון FICO הגבוה יותר מ- 716 הינה 0.1893. ממשפט בייס עולה כי ההסתברות להלוואה טובה המותנית בציון FICO הגבוה יותר מ- 716 היא:

נעיר כי ניתן להשתמש בחישובים בייסיאנים אחרים (מורכבים יותר) לעידכון הסתברויות. לדוגמא, בשלב הבא אנחנו יכולים לחשב את ההסתברות להלוואה טובה המותנית הן בציון FICO הגבוה יותר מ- 716 והן בהכנסה הגבוהה יותר מ- 48,710 דולר.
המסווג הנאיבי של בייס הינו פרוצדורה שיכולה לשמש אם הערכים של המאפיינים עבור התצפיות המסווגים בדרך מסויימת מונחים כבלתי תלויים זה בזה. אם C הוא תוצאת הסיווג ו- xj הוא הערך של המאפיין ה- j (m ≥ j ≥ 1), או אז אנו יודעים מתוך משפט בייס ש-
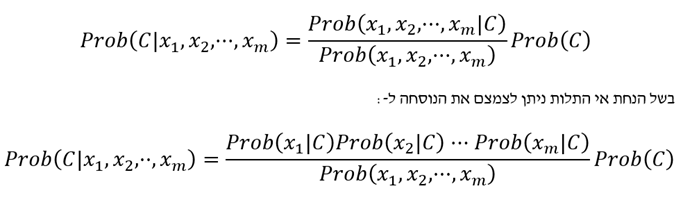
מה שמראה שאם אנחנו יודעים את ההסתברות של כל אחד מהמאפיינים המותנית בסיווג, הרי שאנחנו יכולים לחשב את ההסתברות של הסיווג המותנית בכך שיתרחש תמהיל מסוים של מאפיינים.
כדוגמא פשוטה לשימוש של זה נניח שההסתברות הלא מותנית (unconditional, השולית) להלוואה טובה היא 85% וכי ישנם שלושה מאפיינים בלתי תלויים זה בזה, כאשר ההלוואה מוערכת:
- האם בבעלותו של מבקש ההלוואה ישנו בית (מסומן ב- H), או אם לאו. ההסתברות לכך שבבעלותו של מבקש ההלוואה ישנו בית אם ההלוואה היא טובה הינה 60% בשעה שההסתברות לכך שבבעלותו של מבקש ההלוואה ישנו בית אם ההלוואה היא רעה (default, מגיעה למצב של חדלות פירעון) הינה רק 50%.
- האם מבקש ההלוואה מועסק למעלה משנה (מסומן ב- E), או אם לאו. ההסתברות לכך שמבקש ההלוואה מועסק למעלה משנה אם ההלוואה היא טובה הינה 70% בשעה שההסתברות לכך שמבקש ההלוואה מועסק למעלה משנה אם ההלוואה היא רעה הינה רק 60%.
- האם ישנם שני מבקשי הלוואה (מסומן ב- T), או רק מבקש הלוואה אחד. ההסתברות לכך שקיימים שני מבקשי הלוואה כאשר ההלוואה היא טובה הינה 20% בשעה שההסתברות לכך שקיימים שני מבקשי הלוואה כאשר ההלוואה היא רעה הינה רק 10%.
נחשב את ההסתברות המותנית להלוואה טובה בהינתן שידוע שבבעלותו של מבקש ההלוואה ישנו בית וגם שמבקש ההלוואה מועסק למעלה משנה וגם שישנם שני מבקשי הלוואה עבור אותה הלוואה. בהנחה שהמאפיינים הינם בלתי תלויים זה בזה על פני הלוואות טובות והלוואות רעות כאחד הרי ש-:
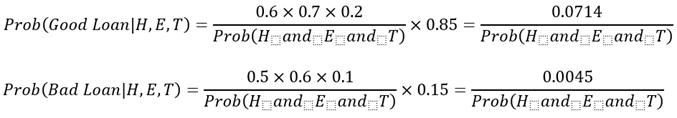
היות וההסתברות להלוואה טובה וההסתברות להלוואה רעה חייבות להסתכם לאחד, הרי שאנחנו לא צריכים לחשב את הערך של Prob(H and E and T). ההסתברות להלוואה טובה הינה אם כך:
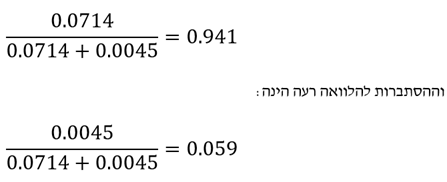
כלומר עבור מבקש הלוואה אשר סימן שהוא עומד בכל שלושת המאפיינים שלעיל במצטבר, ההסתברות להלוואה טובה עולה מ- 85% ל- 94%.
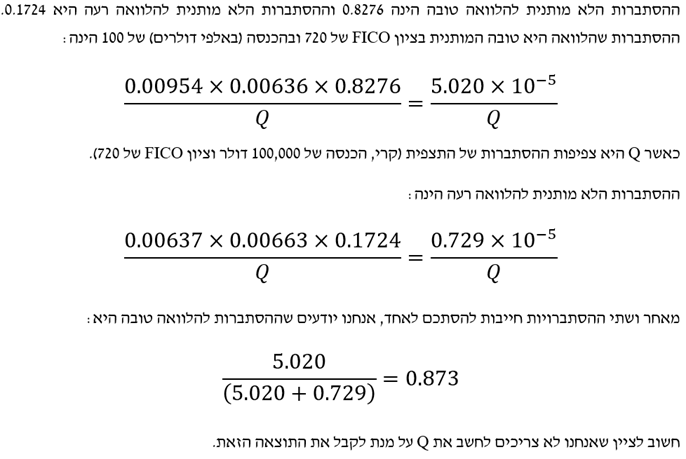
אנחנו גם יכולים להשתמש במסווג הנאיבי של בייס עם התפלגויות רציפות. נניח שאנחנו רוצים להשתמש בנתונים שבמאמר מס' 5 בסדרה שכותרתו "מודלים לינאריים בבעיות סיווג (רגרסיה לוגיסטית ו- LDA)" על מנת לייצר תחזית להלוואה באמצעות שני מאפיינים: ציון FICO והכנסה. אנחנו מניחים שהמאפיינים הללו בלתי תלויים זה בזה הן עבור נתונים על הלוואות טובות והן עבור נתונים על הלוואות רעות. נציין כי הנחת אי התלות הינה קירוב. עבור הלוואות רעות הקורלציה שבין ציון ה- FICO לבין ההכנסה היא בערך 0.07 ועבור הלוואות טובות הקורלציה היא בערך 0.11.
הטבלה הבאה מציגה את התוחלת (Mean) וסטיית התקן (SD) של ציון ה- FICO וההכנסה בהינתן הלוואה טובה והלוואה רעה. להלן נתונים סטטיסטיים על ציון ה- FICO וההכנסה בהינתן תוצאות ההלוואה (ההכנסה נמדדת באלפי דולרים).
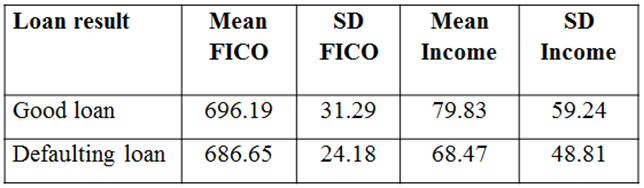
נניח מבקש הלוואה בודד שציון ה- FICO שלו הוא 720 ושהככנסה שלו (באלפי דולרים) היא 100. בהינתן שההלוואה היא טובה הרי שלציון ה- FICO יש תוחלת של 698.18 וסטיית תקן של 31.28.
נזכיר ש- X נקרא משתנה מקרי אם X מקבל כל ערך בקטע נתון (גובה, משקל, טמפרטורה…). מאחר ובהתפלגות רציפה הסתברות 'ליפול' על נקודה ספציפית שואפת לאפס, הרי שעלינו לעבור לדבר על הסתברות 'ליפול' בקטע מסוים, והסתברות שכזו נקראת צפיפות ההסתברות (probability density). במקום "להקצות" הסתברויות לערכים, אנו מקצים הסתבויות לקטעים בעלי אורכים שונים.

- לסיכום
המסווג הנאיבי של בייס קל לשימוש כאשר ישנו מספר רב של מאפיינים. המסווג הנאיבי של בייס יוצר מערך של הנחות פשטניות שסביר להניח שאינן נכונות לגמרי בפועל. עם זאת, נמצא שהמסווג הנאיבי של בייס מועיל ביותר במצבים שונים ומגוונים. לדוגמא, המסווג הנאיבי של בייס יעיל למדי בזיהוי ספאם (Spam, דואר זבל) כאשר תדירויות המילים משמשות בתור המאפיינים.
"מדען נתונים הוא אחד שגם טוב יותר בסטטיסטיקה ואקונומטריקה מכל בוגר מדעי המחשב או מהנדס תוכנה וגם טוב יותר בהנדסת תוכנה מכל סטטיסטיקאי או כלכלן", רועי פולניצר, אקטואר ומעריך שווי, 2019.

הכותב הינו מדען נתונים (Data Scientist) העושה שימוש ב- Machine Learning לצורך פיתוח מודלים מתקדמים לניהול סיכונים (בדגש על אשראי קמעונאי) כגון מודלים מנבאי התנהגות לקוחות ו/או מודלי תחזיות בתחום ניהול הסיכונים, שיפור מודלים בתחום ניהול הסיכונים, ניתוח צרכים עסקיים בעולמות ניהול הסיכונים, אפיון פתרונות מתאימים באמצעות עבודה מול בסיס נתונים גדולים ויישום כלים אנליטיים מתקדמים בעולם הבינה המלאכותית, הערכת סיכוני מודל וניטור פעולות מתקנות, ניתוח ועיבוד גורמי סיכון עיקריים, וניתוח הבדלים בין חלופות ואיפיון גורמי סיכון.
ניסיונו של רועי בתחום ה- Data Analysis, כולל: עבודה עם מאגרי מידע גדולים Big Data תוך שימוש ב- Statistical Learning (כגון: סטטיסטיקה תיאורית, הסתברות, הסקה סטטיסטית, סטטיסטיקה א-פרמטרית, חלוקת נתונים, נרמול נתונים, Fitting ו- Bayes Theorem) ובאלגוריתמים מסוג Unsupervised Learning (כגון: k-means Clustering, Hierarchical Clustering, Density-based Clustering, Distribution-based Clustering ו- Principle Components Analysis) למציאת דפוסים וזיהוי מגמות ואנומליות בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, פיתוח תשתית לצורך ניתוח נתונים, שילוב והטמעת כלים לצורך גישה ושליפה עצמאית של נתונים ממאגרי מידע, פיתוח דוחות, ממשקים ומסכים באמצעות כלי ויזואליזציה.
ניסיונו של רועי בתחום ה- Data Science, כולל: עבודה עם מסדי נתונים גדולים Big Data תוך שימוש באלגוריתמים מסוג Supervised Learning (כגון: Linear Regression, Ridge Regression, Lasso Regression, Elastic Net Regression, Logistic Regression, Maximum Likelihood Estimation, k-Nearest Neighbors, Decision Tree, Random Forest, Ensemble, Bagging, Boosting, Naïve Bayes Classifier, Linear Separation, Support Vector Machine, Non-Linear Separation, SVM Regression, Artificial Neural Network, Convolutional Neural Network ו- Recurrent Neural Network) לניבוי וסיווג בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה ובמודלים מסוג Reinforcement Learning (כגון: Q-learning, Monte Carlo Simulation, Temporal Difference Learning ו- n-Step Bootstrapping) לקבלת החלטות מרובות שלבים בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, זיהוי אתגרים עסקיים שבהםDATA יכול להוות גורם מכריע בשיפור קבלת החלטות, איתור ואיסוף מקורות מידע, הגדרה ואיפיון של שימושי המידע, בניית מסד המידע, אפיון והגדרת הצגת המידע ותוצריו, פיתוח כלים, מודלים, תהליכים ומערכות בתחום האנליזה, תוך שימוש בכלי אנליזה מתקדמים (VBA, R Programming ו- Python).
מגזין "סטטוס" מופק ע"י:
Tags: אקטואריה הערכת שווי כלכלה פיננסים


