





























































מאמר מס' 7 בסדרה
פורסם: 14.2.20 צילום: יח"צ
- הקדמה
סדרת מאמרים זו מבוססת על נסיוני כמדען נתונים (Data Scientist) המתמחה בתחום למידת המכונה (ML- Machine Learning) בעולמות המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה.
חלק מהאלגוריתמים של ML למדתי בתואר הראשון שלי בכלכלה (כגון: הטיה מול שונות, בעיות רגרסיה מול בעיות סיווג, חלוקת נתונים ל- Training set ו- Testing set, נרמול נתונים, רגרסיה לינארית, Ridge, Lasso ו- Elastic Net, יישומי אלגברה לינארית בתוכנת Excel וכו'), חלק בקורסים לתואר שני בכלכלה (כגון: Dimensionality Reduction, Principle Components Analysis, K-Mean Cluster Analysis, Hierarchical Cluster Analysis ו- Time Series וכו'), חלק בתואר השני שלי במימון (כגון: Decision Trees, Random Forest, Monte Carlo Simulation, Bootstrapping, Cubic-Spline, Nelson-Siegel-Svensson וכו'), חלק למדתי בלימודי התעודה באקטואריה (המסווג הנאיבי של בייס, Overfitting, ,Underfitting Convolution and Pooling, תכנות מדעי וסטטיסטי בשפת R וכו'), חלק למדתי בלימודי התעודה בניהול סיכונים פיננסיים ועל חלק אף נבחנתי במבחנים הבינלאומיים להסמכה בתחום ניהול הסיכונים הפיננסיים FRM (כגון: רגרסיה לוגיסטית, Logit, Probit,LDA , K-Nearest Neighbor ו- Support Vector Machines וכו') ואת היתר למדתי עצמאית באינטרנט (כגון: Neural Networks, Ensemble, Bagging, Boosting, תכנות בשפת VBA וכו').
כמובן שההבנה העמוקה שלי באלגוריתמים של ML נשענת הן על הידע שלי בסטטיסטיקה (הכולל בין היתר: סוגי נתונים והצגתם באופן טבלאי וגרפי, מדדי מרכוז ומדדי פיזור, אחוזונים, מדדי קשר, התפלגות הנתונים, הסתברות פשוטה במרחב הסתברותי אחיד ובמרחב הסתברותי לא אחיד, הסתברות מותנית, נוסחת בייס, משתנים מקריים בדידים: ניסויי ברנולי, התפלגות בינומית, התפלגות פואסונית, התפלגות גיאומטרית, התפלגות היפרגיאומטרית, משתנים מקריים רציפים: התפלגות נורמלית, הסקה סטטיסטית, אמידה נקודתית, רווחי סמך, מבחני השערות וסטטיסטיקה א-פרמטרית) והן על הידע שלי בתורת הקבוצות (הכולל בין היתר: מערכות משוואות לינאריות, וקטורים ב- R^n, מטריצות ריבועיות, מטריצות אלמנטריות, מרחבים וקטורים, מרחבי מכפלה פנימית, אורתוגנליות, דטרמיננטות, ערכים עצמיים, וקטורים עצמיים, לכסון, תבניות ריבועיות, משוואות הפרשים, תכונות טופולוגיות של קבוצות במרחב אוקלידי, קבוצות קמורות, משפטי הפרדה, פונקציות קמורות וקעורות, תכונות ואפיונים, שנאת סיכון, אופטימיזציה של פונקציות עם ובלי אילוצים, משפט הפונקציות הסתומות, משפט המעטפת, משוואות דיפרנציאליות מסדרים שונים, מערכות של משוואות דיפרנציאליות ושיטות של אופטימיזציה דינאמית).
מטרתה של סדרת מאמרים זו היא להקנות לקורא הבנה מה עושים מדעני נתונים (Data Scientists) נתונים וכיצד הם יכולים לקדם את מטרות הארגון. מרבית אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה מכירים בכך שהם זקוקים לידע מסוים בתחום ה- ML על מנת לשרוד בעולם שבו מספר מקומות העבודה מושפע יותר ויותר מתחום זה. כיום, כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה צריכים לדעת לעשות שימוש בתוכנת Excel ולדעת לתכנת ברמה מסוימת ב- VBA. מחר כבר כל אנשי המימון הכמותי, ניהול הסיכונים הפיננסיים והאקטואריה יצטרכו לדעת לעבוד עם מאגרי נתונים גדולים (Big Data) תוך פיתוח ושימוש באלגוריתמים של ML על מנת לזהות כיוונים ומגמות בעולמי התוכן שלהם או במגוון תחומים לרוחב הארגון.
בסדרת מאמרים זו חסכתי מהקורא את השימוש בתורת הקבוצות (קרי, מטריצות ווקטורים), למרות שלעניות דעתי אלגברה לינארית חיונית ביותר על מנת להגיע להבנה עמוקה ולשליטה ברמה גבוהה ב- ML.
לסיכום, סדרת מאמרים זו מציגה את הכלים, המודלים והאלגוריתמים הפופולריים ביותר שבהם משתמשים כיום מדעני נתונים.
- סיכום המאמר הקודם: חיזוי באמצעות שיטות K Nearest Neighbors
אלגוריתם השכן ה- k הקרוב ביותר הינו אלטרנטיבה פשוטה לרגרסיה. יישום האלגוריתם כולל 3 שלבים. בשלב הראשון, מנרמלים את הנתונים (Feature Scaling). בשלב השני, מודדים את המרחק, במרחב של n מימדים, של הנתונים החדשים מהנתונים שעבורם יש לנו תוויות (Labels, תוצאות ידועות).
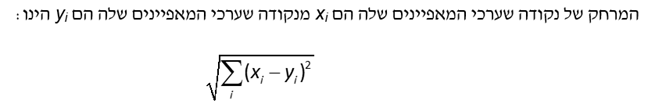
בשלב השלישי, בוחרים את k פריטי הנתונים הקרובים ביותר וממצעים את התוויות שלהם. לדוגמה, אם תחזית מכירות רכבים במדינה מסוימת בארה"ב עבור k ששווה ל- 3 ושלושת השכנים הקרובים ביותר (קרי, הקרובים ביותר מבחינת מדד המרחק האוקלידי) עבור צמיחת התוצר ושיעור הריבית נותנים לנו מכירות של 5.2, 5.4 ו 5.6 מיליון יחידות, או אז על פי אלגוריתם השכן ה- k הקרוב ביותר, עבור k ששווה ל- 3, תחזית מכירות הרכבים באותה מדינה תהיה הממוצע של התוויות של 3 השכנים הקרובים ביותר (קרי, הקרובים ביותר מבחינת מדד המרחק האוקלידי) או 5.4 מיליון יחידות. נניח שאנחנו רוצים לנבא האם הלוואה מסוימת שאנחנו רוצים להעמיד ללווה צרכני מסוים תגיע לחדלות פירעון או לא, עבור kששווה ל- 5 וחמשת השכנים הקרובים ביותר (קרי, הקרובים ביותר מבחינת מדד המרחק האוקלידי). עוד נניח שמתוך חמש ההלוואות הדומות ביותר (מבחינת המאפיינים של ההלוואה שלנו), אנחנו יודעים שארבע הגיעו לחדלות פירעון ורק אחת הוחזרה במלואה. לפיכך, לפיכך, ההסתברות לחדלות פירעון (PD- Probability to Default) של ההלוואה הנבחנת הנאמדת באמצעות אלגוריתם השכן ה- k הקרוב ביותר, עבור k שווה ל- 5, שווה שווה ל- 80% (4 הלוואות שהגיעו לחדלות פירעון מתוך 5 הלוואות דומות).
- מאפיינים של עצי החלטה (Decision Trees)
עצי החלטה הוא אלגוריתם חיזוי השייך לתחום הלמידה בהשגחה. לעצי החלטה ישנם מספר יתרונות פוטנציאליים על פני רגרסיה לינארית או לוגיסטית. לדוגמא:
- עצי החלטה תואמים לאופן שבו מרבית בני האדם חושבים על בעיה מסוימת והם פשוטים להסבר למי שאינם מומחים.
- אין שום דרישה שהקשר בין היעד לבין המאפיינים יהיה לינארי.
- העץ בוחר אוטומטית במאפיינים הטובים ביותר על מנת לבצע את החיזוי.
- עץ החלטה רגיש פחות לתצפיות חריגות מאשר רגרסיה.
עץ החלטה מציג תהליך של שלב-אחר-שלב לביצוע חיזוי. לשם הפשטות נתחיל עם דוגמא פשוטה הנוגעת לסיווג מועמדים לתפקיד מסוים לשתי קטגוריות: 1) כאלו שצריכים לקבל הצעת עבודה (job offer); ו- 2) כאלו שצריכים לומר להם "תודה אבל לא תודה" (no job offer).
הדוגמא מתארת את אחד המאפיינים העיקריים של עצי החלטה. ההחלטה מתקבלת על ידי הבאה בחשבון של המאפיינים אחד בכל פעם במקום כולם בבת אחד. תחילה, נלקח בחשבון המאפיין החשוב ביותר (תואר רלוונטי במקרה דנן שלפנינו), לאחר מכן נלקחים שנות הניסיון, וכך הלאה.
להלן דוגמה לעץ החלטה לקביעת קריטריון להעסקת עובד
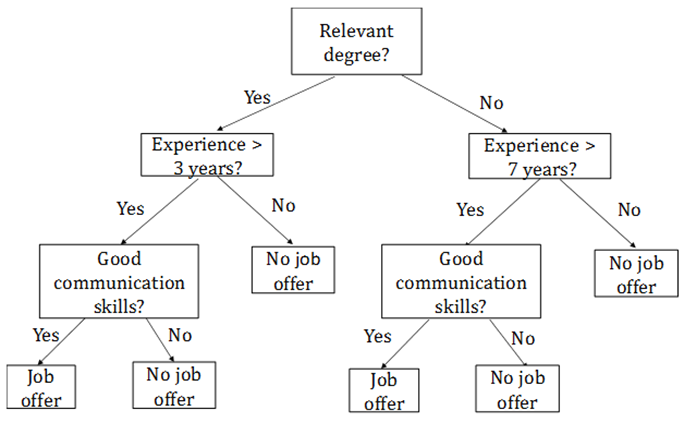
חשוב להבין שמעסיק יכול בתת-מודע שלו להשתמש בעץ החלטה שכזה, מבלי לרשום אותו. כאשר עצי החלטה משמשים ככלי של למידת מכונה, או אז העץ נבנה מתוך נתונים היסטוריים באמצעות אלגוריתם, כפי שנסביר בהמשך.
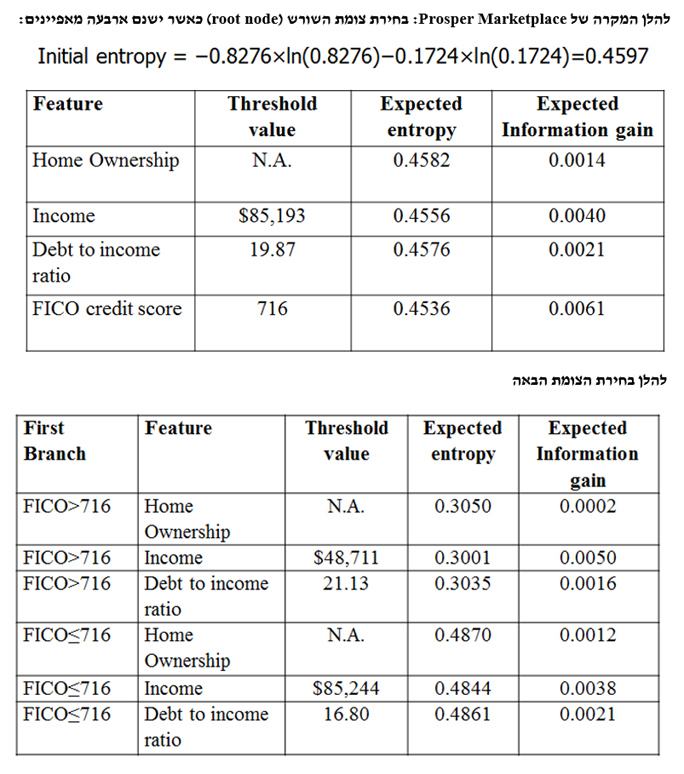
- מדדים לרווח ממידע
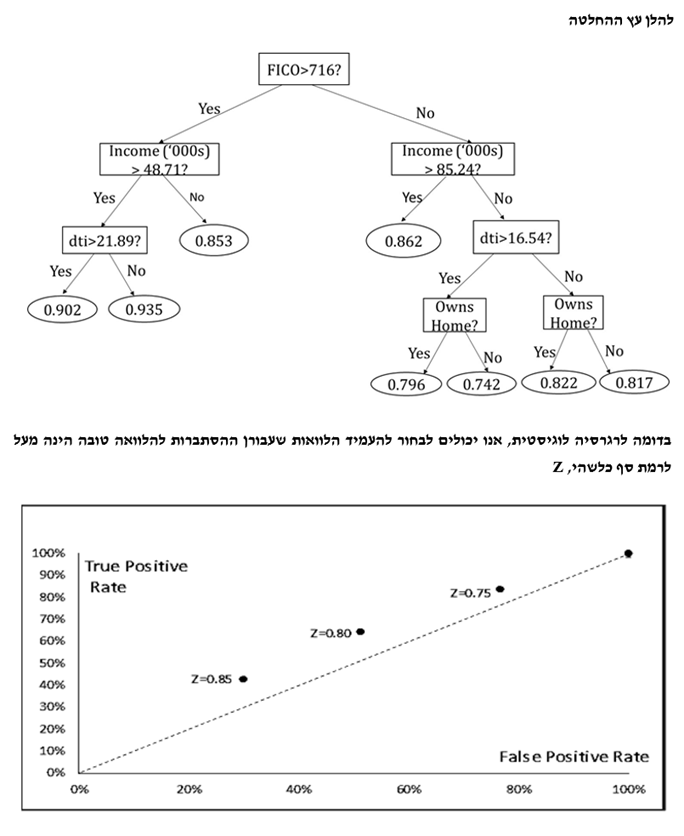
מהו המאפיין הטוב ביותר לבחירה עבור צומת השורש? נניח שמטרת הניתוח שלנו היא לשכפל את האופן שבו החלטות העסקה התקבלו בעבר (הערה אינפורמטיבית: ניתוח מתוחכם יותר יכל לנסות למצוא קשר בין הביצועים של עובדים לבין המאפיינים שהיו ידועים במועד שהתקבלה ההחלטה על העסקתם). המאפיין שאותו נשים בשורש של העץ הוא זה שהרווח שלו מהמידע הוא הגדול ביותר. נניח שיש לנו המון נתונים על מועמדים לתפקיד וכי הצענו עבודה ל- 20% מהם. עוד נניח של- 50% מהמועמדים לתפקיד יש תואר רלוונטי. אם גם לאלו שיש להם תואר רלוונטי וגם לאלו שאין להם תואר רלוונטי יש סיכוי של 20% לקבל הצעת עבודה, הרי שאין רווח מהמידע האם למועמד מסוים יש תואר רלוונטי או אם לאו. עם זאת, נניח ש:
- 30% מאלו שיש להם תואר רלוונטי מקבלים הצעת עבודה
- 10% מאלו שאין להם תואר רלוונטי מקבלים הצעת עבודה
או אז, ברור שקיים רווח מהמידע האם למועמד מסוים יש תואר רלוונטי או אם לאו.

כאשר בונים את עץ ההחלטה, תחילה עלינו לחפש את המאפיין שהרווח שלו מהמידע הוא הגדול ביותר. מאפיין זה יוצב בשורש של העץ. עבור כל אחד מהצמתים שיוצא מהשורש אנו מחפשים את המאפיין (ששונה מזה שבצומת השורש) שהרווח שלו מהמידע הוא הגדול ביותר. הן עבור "יש תואר רלוונטי" והן עבור "אין תואר רלוונטי", המאפיין שממקסם את הרווח מהמידע הצפוי (ירידה באנטרופי הצפוי) בדוגמא דנן הוא מספר שנות הניסיון העסקי. כאשר למועמד יש תואר רלוונטי, רמת הסף עבור מאפיין זה הממקסמת את הרווח מהמידע הצפוי היא 3 שנים. ברמה השנייה של העץ, "יש תואר רלוונטי" מתפתצלת ל- 2 ענפים: "ניסיון > 3" ו- "ניסיון ≤ 3". עבור הענף התואם למועמד שאין לו תואר רלוונטי רמת הסף הממקסמת את הרווח מהמידע הצפוי היא 7 שנים. לפיכך, שני הענפים הבאים הם: "ניסיון > 7" ו- "ניסיון ≤ 7". אנו עושים שימוש באותה הפרוצדורה לבניית יתר העץ.

- אלגוריתם עץ ההחלטה
אלגוריתם עץ ההחלטה בוחר את המאפיין בשורש העץ (root) בעל רווח המידע הצפוי הגבוה ביותר, בעוד שבצמתים הבאים האלגוריתם בוחר במאפיין (שטרם נבחר) בעל רווח המידע הצפוי הגבוה ביותר. כאשר קיימת רמת סף (threshold) מסוימת, האלגוריתם קובע את רמת הסף האופטימלית עבור כל אחד מהמאפיינים (כלומר, את רמת הסף שמשיאה/מביאה למקסימום את רווח המידע הצפוי עבור אותו מאפיין) ומבסס את החישובים על אותה רמת סף.
- משתני יעד רציפים (Continuous Target Variables)
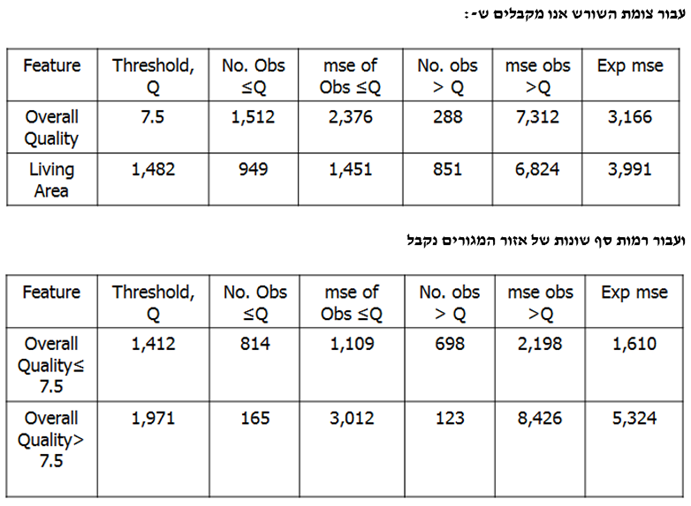
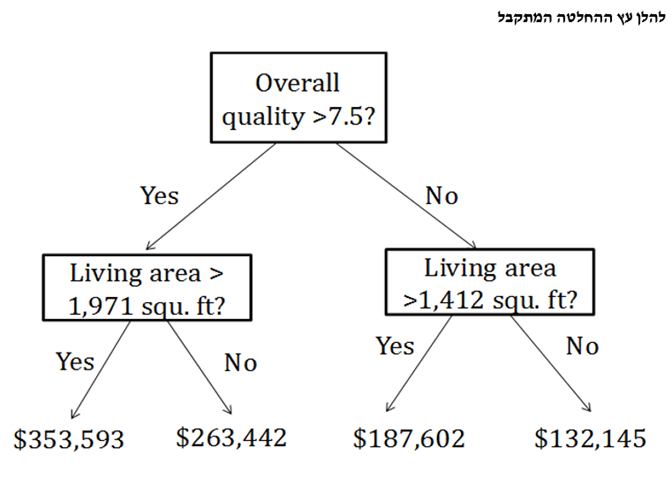
אנו יכולים לבנות עץ החלטה שבמקום להשיא/להביא למקסימום את רווח המידע הצפוי אנו יכולים להשיא/להביא למקסימום את הירידה הצפויה בשגיאה הריבועית הממוצעת (MSE- Mean Square Error). כך למשל בדוגמא של מחירי הבתים בניו הייבן קונטיקט בארה"ב (באלפי דולר ארה"ב), שקלנו למעשה רק את האיכות הכוללת ואת אזור המגורים.
- לסיכום
עץ החלטה (Decision Tree) הינו אלגוריתם לסיווג או לחיזוי ערכו של משתנה, כאשר המאפיינים מסודרים לפי סדר החשיבות. לצורך סיווג, קיימים שני מדדים אלטרנטיביים לאי וודאות: מדד אנטרופי (Entropy) ומדד ג'יני (Gini). כאשר ערכו של משתנה מסוים נחזה, אי הוודאות נמדדת באמצעות שורש השגיאה הריבועית הממוצעת (RMSE- Root Mean Squared Error) של התחזית. חשיבותו של מאפיין הינו הרווח מהמידע הצפוי שלו (Expected Information Gain). הרווח מהמידע הצפוי נמדד על ידי הירידה באי הוודאות הצפויה אשר תתרחש כאשר יתקבל מידע אודות המאפיין.
במקרה של מאפיינים קטגוריאליים, המידע המתקבל הינו על פי רוב אודות התווית (Label) של המאפיין (למשל, האם יש בבעלותו של לווה פוטנציאלי מסוים בית או שמא הוא שוכר דירה). במקרה של מאפיין נומרי יש לקבוע ערך סף (Threshold) אחד (או יותר) המגדיר שני טווחים (או יותר) עבור ערך המאפיין. ערכי סף אלו נקבעים באופן שממקסם את רווח המידע הצפוי.
אלגוריתם עץ ההחלטה קובע תחילה את צומת השורש (Root Node) האופטימלי של העץ באמצעות קריטריון "מקסום הרווח מהמידע" שהוגדר לעיל. לאחר מכן, אלגוריתם עץ ההחלטה ממשיך לעשות אותו הדבר עבור הצמתים העוקבים. הקצוות של הענפים הסופיים של העץ מכונים צמתי עלים (Leaf Nodes). כאשר עץ ההחלטה משמש לסיווג, או אז צמתי העלים כוללים בחובם את ההסתברויות של כל אחת מהקטגוריות להיות הקטגוריה הנכונה. כאשר כאשר עץ ההחלטה משמש לחיזוי ערך נומרי, או אז צמתי העלים מספקים את הערך התוחלתי של היעד. הגיאומטריה של העץ נקבעת באמצעות סט האימון (Training Set), אך הסטטיסטיקה שעוסקת ברמת הדיוק של העץ צריכה כמו תמיד בלמידת מכונה לבוא מתוך סט הבדיקה (Test Set) ולא מתוך סט האימון.
"מדען נתונים הוא אחד שגם טוב יותר בסטטיסטיקה ואקונומטריקה מכל בוגר מדעי המחשב או מהנדס תוכנה וגם טוב יותר בהנדסת תוכנה מכל סטטיסטיקאי או כלכלן", רועי פולניצר, אקטואר ומעריך שווי, 2019.

רועי הינו מדען נתונים (Data Scientist) העושה שימוש ב- Machine Learning לצורך פיתוח מודלים מתקדמים לניהול סיכונים (בדגש על אשראי קמעונאי) כגון מודלים מנבאי התנהגות לקוחות ו/או מודלי תחזיות בתחום ניהול הסיכונים, שיפור מודלים בתחום ניהול הסיכונים, ניתוח צרכים עסקיים בעולמות ניהול הסיכונים, אפיון פתרונות מתאימים באמצעות עבודה מול בסיס נתונים גדולים ויישום כלים אנליטיים מתקדמים בעולם הבינה המלאכותית, הערכת סיכוני מודל וניטור פעולות מתקנות, ניתוח ועיבוד גורמי סיכון עיקריים, וניתוח הבדלים בין חלופות ואיפיון גורמי סיכון.
ניסיונו של רועי בתחום ה- Data Analysis, כולל: עבודה עם מאגרי מידע גדולים Big Data תוך שימוש ב- Statistical Learning (כגון: סטטיסטיקה תיאורית, הסתברות, הסקה סטטיסטית, סטטיסטיקה א-פרמטרית, חלוקת נתונים, נרמול נתונים, Fitting ו- Bayes Theorem) ובאלגוריתמים מסוג Unsupervised Learning (כגון: k-means Clustering, Hierarchical Clustering, Density-based Clustering, Distribution-based Clustering ו- Principle Components Analysis) למציאת דפוסים וזיהוי מגמות ואנומליות בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, פיתוח תשתית לצורך ניתוח נתונים, שילוב והטמעת כלים לצורך גישה ושליפה עצמאית של נתונים ממאגרי מידע, פיתוח דוחות, ממשקים ומסכים באמצעות כלי ויזואליזציה.
ניסיונו של רועי בתחום ה- Data Science, כולל: עבודה עם מסדי נתונים גדולים Big Data תוך שימוש באלגוריתמים מסוג Supervised Learning (כגון: Linear Regression, Ridge Regression, Lasso Regression, Elastic Net Regression, Logistic Regression, Maximum Likelihood Estimation, k-Nearest Neighbors, Decision Tree, Random Forest, Ensemble, Bagging, Boosting, Naïve Bayes Classifier, Linear Separation, Support Vector Machine, Non-Linear Separation, SVM Regression, Artificial Neural Network, Convolutional Neural Network ו- Recurrent Neural Network) לניבוי וסיווג בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה ובמודלים מסוג Reinforcement Learning (כגון: Q-learning, Monte Carlo Simulation, Temporal Difference Learning ו- n-Step Bootstrapping) לקבלת החלטות מרובות שלבים בעולמות ניהול הסיכונים, ההשקעות, האקטואריה, הביטוח והפנסיה, זיהוי אתגרים עסקיים שבהםDATA יכול להוות גורם מכריע בשיפור קבלת החלטות, איתור ואיסוף מקורות מידע, הגדרה ואיפיון של שימושי המידע, בניית מסד המידע, אפיון והגדרת הצגת המידע ותוצריו, פיתוח כלים, מודלים, תהליכים ומערכות בתחום האנליזה, תוך שימוש בכלי אנליזה מתקדמים (VBA, R Programming ו- Python).
מגזין "סטטוס" מופק ע"י:
Tags: אקטואריה הערכת שווי


