































































מגפת ה- COVID-19 (להלן: "הקורונה") גרמה להתפרצות גדולה בלמעלה מ- 150 מדינות ברחבי העולם, ויש לה השפעה אדירה על בריאותם וחייהם של אנשים רבים ברחבי העולם. אחד הצעדים המכריעים במאבק בקורונה הוא היכולת לאתר את החולים הנגועים בשלב מוקדם מספיק ולהעניק להם טיפול מיוחד
פורסם: 10.11.20 צילום: יח"צ
בהיעדר זמינות של תרופה או חיסון לקורונה, הרי שקיימת חשיבות אמיתית לאבחון מוקדם של הנגיף על מנת לאפשר בידוד מיידי של האדם החשוד כנשא קורונה ובכך להפחית את הסיכוי לזיהום בקרב אוכלוסייה בריאה.
זיהוי קורונה מתוך צילומי רנטגן חזה הוא אולי אחת הדרכים המהירות ביותר לאבחון מטופלים המתלוננים על קשיי נשימה, כאבים בחזה, שיעול וחום (להלן: "התסמינים"). מחקרים מוקדמים מצביעים על אנומליות ספציפיות המופיעות בצילומי רנטגן חזה של חולי קורונה עם התסמינים.
בעבודה זו מוצעת דרך לזיהוי קורונה בצילומי רנטגן של חולים עם התסמינים. שימוש בשיטה המוצגת מאפשר זיהוי קורונה בקרב חולים המגיעים לחדר מיון עם התסמינים – דבר שיכול למנוע מהם מלהגיע למחלקות הפנימיות של בית החולים ולהדביק שם את החולים ואנשי הצוות הרפואי.
בהתחשב בשיעור העצום של חשודים כנשאי קורונה ובמספר המוגבל של רדיולוגים מומחים המסוגלים לפענח אנומליות כה עדינות בצילומי רנטגן חזה כקורונה, הרי שרק שיטות אוטומטיות יכולות לסייע בהליך האבחון ולהעלות הן את קצב האבחון המוקדם והן את רמת הדיוק שלו.
חשיבותה של עבודה זו נעוצה בהגדרת מצב ה"לא קורונה", כחלק מתהליך הקלסיפיקציה הבינארית, לזיהוי קורונה.
- הקדמה
מאז דצמבר 2019 התפשט וירוס קורונה חדש (SARS-CoV-2) מוווהאן לסין כולה ולמדינות רבות אחרות. עד ל- 5 בנובמבר 2020 דווח על למעלה מ- 49.9 מיליון מקרים מאושרים ולמעלה מ- 1,250,000 מקרי מוות בעולם (מקור: האתר worldometers). בהיעדר זמינות של תרופה או חיסון למחלת הקורונה, הרי שקיימת חשיבות אמיתית לאבחון מוקדם של הנגיף על מנת לאפשר בידוד מיידי של האדם החשוד כנשא קורונה ובכך להפחית את הסיכוי לזיהום בקרב אוכלוסייה בריאה.
Wang ואחרים (2020) מציינים כי תגובת שרשרת פולימראזית עם שעתוק לאחור (להלן "RT-PCR") או רצף גנים (DNA) לדגימות נשימה או דם, הינם הדרכים העיקריות לזיהוי קורונה.
Yang ואחרים (2020) מצאו כי רמת המהימנות (Accuracy) של ה- RT-PCR בדגימות משטח גרון נעה בסך הכל בין 30% ל- 60%, וכפועל יוצא מכך נשאי קורונה בפועל אינם מאובחנים כנדבקים, מה שעלול להביא להדבקת אוכלוסייה עצומה של אנשים בריאים.
Ai ואחרים (2020) מצאו כי דימות רדיוגרפי של החזה (למשל, על ידי צילומי רנטגן או טומוגרפיה ממוחשבת – CT), המשמש ככלי שגרתי לאבחון דלקת ריאות, יכול לשמש לאבחון מהיר של קורונה. החוקרים מצאו שלצילום CT חזה ישנה רגישות גבוהה לאבחון קורונה.
Kanne ואחרים (2020) מדווחים על כך שצילומי רנטגן חזה מציגים אינדקסים חזותיים התואמים לקורונה.
הדיווחים על דימות חזה מצביעים הן על מעורבות רבת-אונות ואטימות במרחב האווירי ההיקפי. Kong and Agarwal (2020) מצאו כי שני הסוגים של האטימות המדווחים בתדירות הגבוהה ביותר הינם: זכוכית טחונה (57%) והחלשה מעורבת (29%).
Hansell ואחרים (2008) מצאו כי בחלקה המוקדם של מחלת הקורונה, הדפוס של אטימות מסוג זכוכית טחונה נצפה בקצות כלי הריאה מה שעלול להקשות על הערכה חזותית או זיהוי קורונה בעין בלתי מזויינת.
Rodrigues (2020) מדווח על אטימות אסימטרית או מפוזרת של חלל האויר בקרב חולי קורונה. חשוב לציין שרק רדיולוגים מומחים מסוגלים לפרש אנומליות עדינות שכאלה כקורונה.
בהתחשב בשיעור העצום של חשודים כנשאי קורונה ובמספר המוגבל של רדיולוגים מומחים כאמור, הרי ששיטות אוטומטיות לזיהוי אנומליות כה עדינות יכולות לסייע בהליך האבחון ולהעלות הן את קצב האבחון המוקדם והן את רמת הדיוק שלו. לעניות דעתי, פתרונות של בינה מלאכותית (Artificial intelligence) ובייחוד פתרונות של למידת עמוקה (Deep Learning) הינם כלים פוטנציאליים חזקים לפתרון בעיות מסוג זה.
עד כה, בשל היעדר זמינות לציבור של צילומי רנטגן של חולי קורונה, לא ניתן היה לעשות שימוש בפתרונות של בינה מלאכותית לזיהוי אוטומטי של קורונה מתוך צילומי רנטגן (או CT חזה).
Cohen ואחרים (2020) מדווחים על כך שלאחרונה נאסף מערך קטן של צילומי רנטגן חזה של קורונה, מה שמאפשר לחוקרי בינה מלאכותית לאמן מודלים של למידת עמוקה לטובת ביצוע אבחון אוטומטי של קורונה מתוך צילומי רנטגן חזה אלו. תמונות אלה חולצו מתוך פרסומים אקדמיים המציגים ממצאי קורונה בצילומי רנטגן ו- CT.
בעבודה זו אני בונה מודל סיווג דו-כיווני מבוסס Convolution Neural Network שמסווג צילומי רנטגן חזה של נבדקים עם התסמינים לאחת משתי הקטגוריות הבאות: "קורונה" ו- "לא קורונה".
המשך המאמר בנוי כדלקמן: בחלק הראשון מוגדרים שני סוגים של קלספיקציה בינארית (דו-קטגורית) וכן מוגדר מהו מצב של "לא קורונה". בחלק השני מוסבר מהו מודל Convolution Neural Network ומהם השלבים לבנייתו. בחלק השלישי, נבנים 5 מודלים לזיהוי קורונה בצילומי רנטגן חזה ונבחר המודל הטוב ביותר מבין החמישה. בחלק הרביעי, נמדדים ביצועיו של המודל הנבחר. חלקו האחרון של המאמר מוקדש לסיכום ולמסקנות.
- הגדרת מצב של "לא קורונה" במודל קלסיפיקציה בינארית
מודל קלסיפיקציה בינארית (דו-קטגורית), כשמו כן הוא, מבקש בראשיתו להגדיר שתי קבוצות או קטגוריות לאבחון שאליהן ישוייכו או יסווגו רשומות מסוימת. למשל: חולה מול לא חולה או חולה מול בריא.
בקלספיקציה בינארית (דו-קטגורית) מקובל להבחין בין שני סוגי מודלים. הסוג הראשון, המכונה מודל הסיווג הדו-כיווני, הינו מודל שמנסה לאבחן רשומה מסוימת לקטגוריה שלילית ברורה ומובהקת (למשל, חולה, חדל פירעון, עבריין וכיוצא באלה סטטוסטים שליליים) או לחילופין לקטגוריה חיובית ברורה ומובהקת (למשל, בריא, סולבנטי, זכאי, וכיוצא באלה סטטוסטים חיוביים).
הרעיון שעומד בבסיסו של מודל הסיווג הדו-כיווני הינו אבחון לשתי קטגוריות מובהקות וברורות, כאשר המודל לומד מתוצאות הסיווג לשתי הקטגוריות ביחד. לאמור- אם יש לנו מודל קלסיפיקציה בינארית דו-כיווני שמסווג חשודים לקורונה למצב "חולה" או "בריא" לצורך קבלת החלטה כמו למשל, האם לתת להם טיפול תרופתי מסוים או אם לאו – הרי שאם מודל הסיווג הדו-כיווני שלנו מסווג נבדק מסוים לקטגוריית ה"חולה", או אז ניתן לאותו נבדק טיפול תרופתי מסוים; אך אם מודל הסיווג הדו-כיווני שלנו מסווג נבדק מסוים לקטגוריית ה"בריא", אזי לא ניתן לאותו נבדק טיפול תרופתי.
ברגיל, מודל סיווג דו-כיווני משמש לקבלת החלטות (go/no-go). כפועל יוצא מכך, מדד הערכה הרלוונטי למודלי סיווג דו-כיווניים הינו מדד המהימנות אשר לומד מתוצאות הסיווג לשתי הקטגוריות. רוצה לומר שמדד המהימנות מביא בחשבון לא רק את אחוז המקרים שבהם המודל צדק (או סיווג נכון) כאשר הוא סיווג נבדקים לקטגוריית ה"חולה", אלא גם את אחוז המקרים שבהם המודל צדק כאשר הוא סיווג נבדקים לקטגוריית ה"בריא" ולכן הוא משקלל את אחוז המקרים שבהם המודל צדק בסיווג לשתי הקטגוריות ולא רק למצב הטבע השלילי (היא קטגוריית ה"חולה" במקרה דנן שלפנינו). לפיכך, מדד הערכה שמתאים למודל מודל סיווג דו-כיווני הוא מדד המהימנות שעליו נרחיב בהמשך.
הסוג השני של מודלים של קלספיקציה בינארית (דו-קטגורית), המכונה מודל הסיווג החד-כיווני, מודל "דגל אדום" או מודל ניהול סיכונים, הינו מודל שמנסה לאבחן רשומה מסוימת לקטגוריה שלילית ברורה ומובהקת (למשל: חולה, חדל פירעון, עבריין וכיוצא באלה סטטוסטים שליליים) או לחילופין לקטגוריה א-שלילית לא ברורה ולא מובהקת (למשל: לא-חולה, לא-חדל פירעון, לא-עבריין וכיוצא באלה סטטוסטים א-שליליים).
הרעיון שעומד בבסיסו של מודל הסיווג החד-כיווני הינו אבחון לקטגוריה אחת מובהקת וברורה ולקטגוריה שניה לא מובהקת ולא ברורה, כאשר המודל לומד מתוצאות הסיווג לקטגוריה אחת בלבד, היא היא הקטגוריה השלילית המובהקת והברורה. לאמור- אם יש לנו מודל קלסיפיקציה בינארית חד-כיווני שמסווג חשודים לקורונה למצב "חולה" או "לא-חולה" לצורך קבלת החלטה כמו למשל, האם לתת להם טיפול תרופתי מסוים או אם לאו – הרי שאם מודל הסיווג החד-כיווני שלנו מסווג נבדק מסוים לקטגוריית ה"חולה", או אז ניתן לאותו נבדק טיפול תרופתי מסוים; אך אם המודל מודל הסיווג החד-כיווני שלנו מסווג נבדק מסוים לקטגוריה ה"לא-חולה", אזי נמשיך לבצע לאותו נבדק בדיקות נוספות עד אשר נוכל לקבוע בוודאות שהוא אכן "בריא" ולא רק "לא חולה" במחלה ספציפית.
ברגיל, מודל סיווג חד-כיווני משמש כמודל שנועד להרים "דגל אדום" או להדליק "נורה אדומה" ולא מודל שמקבל החלטות. כפועל יוצא מכך, מדדי הערכה הרלוונטיים הרלוונטי למודלי סיווג חד-כיווניים הינם מדד הדיוק (Precision) ומדד הרגישות (Recall) אשר לומדים מתוצאות הסיווג לקטגוריה אחת בלבד, היא מצב הטבע השלילי המובהק והברור (קרי, קטגוריית ה"חולה" במקרה דנן שלפנינו).
מדד הרגישות בודק כמה חולים זיהיתי (או סיווגתי נכון) מתוך סך החולים הקיימים מקרב הנבדקים, כלומר, באיזה אחוז מהזמן כשהמכונה נדרשה לסווג נבדק, שידוע בפועל שהוא חולה, היא אכן סיווגה אותו כ"חולה". מאידך, מדד הדיוק בודק כמה מתוך כל הנבדקים שסיווגתי כחולים, הם אכן באמת חולים, כלומר, באיזה אחוז מהזמן כשהמכונה סיווגה נבדק מסוים כ"חולה" הוא אכן היה חולה. למעשה, מדד הדיוק בודק אך ורק את אחוז המקרים שבהם המודל צדק כאשר הוא סיווג נבדקים לקטגוריית ה"חולה" אך הוא איננו מתחשב באחוז המקרים שבהם המודל צדק כאשר הוא סיווג נבדקים לקטגוריית ה"לא חולה".
מדד נוסף שמשמש להערכת למודלי סיווג חד-כיווניים הינו מדד ה- F1-Score. זהו מדד שהוא למעשה מיקס בין מדד הרגישות ומדד הדיוק. נניח שיש לי מודל סיווג חד-כיווני אחד עם מדד דיוק של 99% ומדד רגישות של 0% ומודל מודל סיווג חד-כיווני אחר עם מדד דיוק של 0% ומדד רגישות של 92% ואז נשאלת השאלה "איך משווים בין המודלים הללו?". כאן בדיוק נכנס לתמונה מדד ה- F1-Score. מדד ה- F1-Score הוא ממוצע הרמוני של מדד הדיוק ומדד הרגישות אך אין לו משמעות פיזיקלית. נוסחת החישוב שלו הינה 2 כפול מדד הדיוק כפול מדד הרגישות חלקי סך הצברם של שני המדדים – מה שאומר שאם אחד מהם הוא אפס או קרוב לאפס אז מדד ה- F1-Score שלנו יהיה אפס או מאוד קרוב לאפס. באופן הזה ניתן להשוות בין מודלי סיווג חד-כיווניים באמצעות השוואת מדד אחד בלבד, הלא הוא מדד ה- F1-Score. כפי שכבר ציינתי מדד המהימנות מתאים למודל סיווג דו-כיווני אך לא למודל סיווג חד-כיווני ולכן למרות שניתן תמיד להסתכל על מדד המהימנות, הרי שמדד זה יוביל למסקנה שגויה בהשוואה בין מודלי סיווג חד-כיווניים. מאידך, מדד ה- F1-Score מביא בחשבון הן את מדד הדיוק והן את מדד הרגישות.
מדד אחר שמשמש להערכת למודלי סיווג חד-כיווניים הינו מדד "איכות הניבוי" (ROC AUC) שמציג לנו גרפית את איכות הניבוי של המודל ביחס לאיכות הניבוי של הטלת מטבע הוגן (50%, תחת הנחת מטבע הוגן במספר רב של פעמים – אלפי הטלות) וקביעת ציון הניבוי, על בסיס למידה מתוצאות הסיווג לקטגוריה אחת בלבד, היא מצב הטבע השלילי (קרי, קטגוריית ה"חולה" במקרה דנן שלפנינו).
בתחילה, בניתי מודל סיווג דו-כיווני לזיהוי קורונה מתוך צילומי רנטגן חזה, כאשר מערך הנתונים הלא מובנה (Unstructured, צילומי הרנטגן במקרה דנן שלפנינו) שאספתי ממקורות מידע שונים כלל הן צילומי רנטגן חזה, אשר זוהו בוודאות על ידי רדיולוגים מומחים כקורונה והן צילומי רנגטן חזה אשר זוהו כהאי לישנא: "ללא ממצא פתולוגי בחזה". לצילומים האחרונים הענקתי Label של "בריא" בעוד שלצילומים הראשונים הענקתי Label של "קורונה".
מצ"ב 2 צילומי רנטגן חזה האחד של "קורונה" והשני של "בריא":

לאחר שבניתי את המודל הסיווג הדו-כיווני הגעתי למסקנה שרמת האפליקביליות שלו הינה נמוכה, הואיל ומשעה שמטופל המתלונן על התסמינים נשלח לביצוע צילום רנטגן חזה, הרי שברמת סבירות גבוהה ניתן לקבוע שהרופא ששלח אותו לבצע צילום רנטגן חזה חושד שלאותו מטופל אכן יש ממצא פתולוגי כלשהו בחזה אשר גורם לתסמינים. ולכן, הערכתי את שווייה של האפליקציה המסחרית האפשרית הנגזרת ממודל הסיווג הדו-כיווני שבניתי כ- 0 שכן במכלול מצבי הטבע המסחריים האפשריים אשר בחנתי, אין לה לתוקף, לחילופין ערכה אפס או לחילופי חילופין ערכה אינו מהותי.
מעיון במחקרים שבוצעו בשנה האחרונה בחו"ל עולה שחוקרי בינה מלאכותית רבים מעדיפים דווקא לבנות מודלים של קלסיפיקציה מרובת-קטגוריות, חלף מודלים של קלסיפיקציה בינארית (דו-קטגורית), כפי שאני בניתי, אשר מסווגים נבדקים לאחת מארבעת הקטגוריות הבאות: "Covid" (קורונה), "SARS" (תסמונת נשימתית חמורה חדה), "Streptococcus" (פנאומוקוקוס) ו- "Pneumocystis" (דלקת ריאות מפנימוציסטיס קריניי). מיותר לציין שמדובר במודלי סיווג דו-כיווניים, הווה אומר, מודלים מקבלי החלטה ולא במודלי סיווג חד-כיווניים.
לאחר חשיבה מחדש ולצורך בניית מודל סיווג חד-כיווני לזיהוי קורונה, יצרתי תרחיש דמיוני אשר ממנו גזרתי את דרך הפעולה שלי. על פי התרחיש שיצרתי, קיים בית החולים וירטואלי (לשם הנוחות נקרא לו בית החולים "דן החולה") שמעוניין שחולי קורונה עם התסמינים לא יגיעו למחלקות פנימיות של בית החולים. למעשה בית החולים רוצה לזהות חולי קורונה עם התסמינים מבין החולים שמגיעים לחדר המיון עם התסמינים.
לשם כך בית החולים זקוק לפתרון יעיל ומהיר לזיהוי קורונה בלבד באמצעות פענוח צילומי רנטגן חזה (להבדיל מבדיקת מטוש) עבור חולים עם התסמינים. הנחת העבודה היא שבית החולים פנה אליי לפתח עבורו כלי מבוסס Deep Learning בשפת Python תוך שימוש בספריות הפיתוח: Numpy, Pandas, Tensorflow ו- .Keras
התרחיש שיצרתי מציג כאמור בעיית סיווג תמונות בינארית (Binary Image Classification) קלאסית:

כאמור, להבדיל ממודל הסיווג הדו-כיווני, שבניתי בתחילה, שמסווג נבדקים לאחת מ- 2 קטגוריות: "קורונה" ו- "בריא", החלטתי לבנות מודל סיווג חד-כיווני שמסווג נבדקים לאחת מ- 2 הקטגוריות הבאות: "קורונה" ו- "לא קורונה". רוצה לומר- מודל שמרים "דגל אדום" בעת זיהוי קורונה, אך במידה והוא לא זיהה קורונה זה עדיין לא אומר ששהחולה שלנו הוא בריא.
נשאלת השאלה מה באמת בית החולים "דן החולה" מצפה ממני. להבנתי בית החולים מצפה ממני ל- 6 דברים:
- לאסוף מאות צילומי רנטגן חזה של קורונה (covid).
- להגדיר מהו מצב של "לא קורונה" (no-covid) ולאסוף מאות צילומים בהתאם.
- לבנות מודל סיווג חד-כיווני להבדיל ממודל סיווג דו-כיווני.
- לתת הערכה לגבי אחוז הדיוק, הרגישות ואיכות הניבוי של המודל.
- להסביר למנכ"ל בית החולים על מה הוא שילם.
- להדריך את משתמש הקצה כיצד להשתמש במודל שבניתי על צילומי רנטגן חזה חדשים.
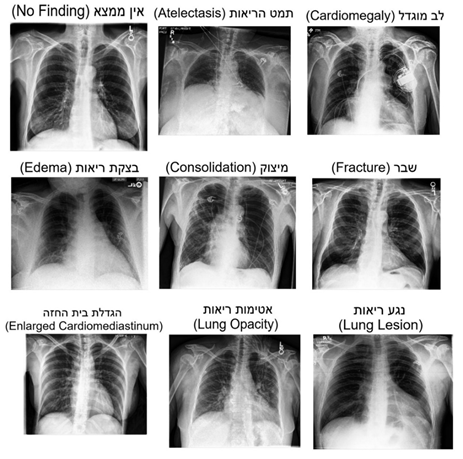
לאחר התייעצות עם רדיולוג מומחה החלטתי להגדיר מצב של "לא קורונה" כאחד מ- 13 הממצאים הבאים השכיחים ביותר לעניות דעתו של הרדיולוג בצילומי רנטגן חזה:
- תמט הריאות- אובדן של נפח הריאה בשל פגיעה ביכולת הרחבת חללי האוויר (נאדיות) שבה.
- לב מוגדל- הגדלה של הלב, המופיעה בהפרעות שגורמות ללב לעבוד קשה יותר מהתקין.
- מיצוק- מחלת ריאות בה הנאדיות מלאות בנוזל שנוצר על-ידי רקמה דלקתית, כמו בדלקת ריאות.
- בצקת בריאות- הצטברות נוזלים בחלל הריאה, העשויה להוביל להפרעה בחילוף הגזים בריאה ועד לכשל נשימתי.
- בית חזה מוגדל/הגדלת בית החזה.
- שבר.
- נגע (סרטני) או גוש– יכול להיות שפיר או ממאיר.
- אטימות ריאות– אזור בריאות שסופג יותר קרינת רנטגן מאזורים אחרים ולכן הוא נראה אטום יותר יחסית לאזור שמסביבו.
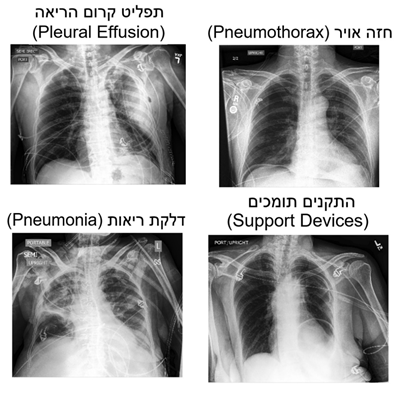
- תפליט קרום הריאה- הצטברות של נוזל (המכונה תפליט) בחלל האֶדֶר (פְּלֶאוּרַה) העוטף את הריאות. הצטברות נוזל בחלל זה מעידה על קיומה של פתולוגיה, היכולה לנבוע כתוצאה ממספר סיבות, כגון אי ספיקת לב, זיהומים שונים וכן סרטן.
- דלקת ריאות- מחלה זיהומית נפוצה של הריאות, אשר יכולה להופיע בכל הגילאים, ומביאה בדרך כלל לבעיות כגון קשיי נשימה, חום, כאבי חזה ושיעול.
- חזה אויר- מצב שבו מצטבר אוויר בין קרומי האֶדֶר המחברים את הריאות לסרעפת או לשרירי הצלעות ובכך נמנע מהריאה להתרחב ולהתכווץ – להכניס אוויר ולהוציאו בתהליך של דיפוזיה כתוצאה מאיבוד הריק.
- התקנים תומכים- כגון: LVAD, RVAD, BiVAD, HEART ARTIFICIAL TOTAL וכיוצא באלה קוצבים והתקנים מושתלים.
- אין ממצא פתולוגי בחזה.
להלן 13 צילומי רנטגן חזה המייצגים את 13 הממצאים המרכיבים את קטגוריית ה"לא קורונה".
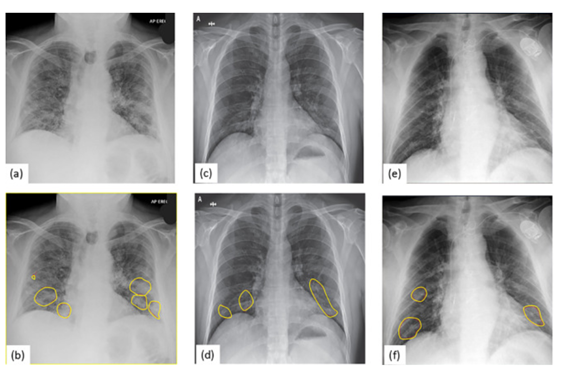
להלן 3 צילומי רנטגן חזה שמייצגים את קטגוריית ה"קורונה" (לפני ואחרי סימון האזור שבו יושב נגיף הקורונה):
- רשת נוירונים קונבולציונית
לצורך פרוייקט הגמר שלי (להלן: "התזה") בתחום ה- Deep Learning במסגרת תוכנית ההכשרה היוקרתית "Data Science, Machine Learning and Deep Learning with Python" של מכללת ג'ון ברייס בניתי את מודל סיווג חד-כיווני לזיהוי קורונה באמצעות רשת נוירונים קונבולוציונית (Convolutional Neural Network, רשת אותה נכנה: "CNN"(.
CNN הינו אלגוריתם של Deep Learning שלוקח תמונות בתור נתוני קלט (Inputs) ומקצה להם חשיבות (קרי, קובע משקולות/מקדמים והטייה/חותך באמצעות למידה) למאפיינים (קרי, למשתנים מסבירים) או אובייקטים שונים בתמונה ולאחר מכן הוא מסוגל להבדיל בין תמונות.
CNN הינה וריאציה מתקדמת יותר של לרשת נוירונים מלאכותית (Artificial Neural Network, רשת אותה נכנה: "ANN"(, שנועדה לטפל בכמות גדולה יותר של מורכבות סביב כל נושא העיבוד-המקדים של הנתונים (Data Preprocessing) כמו גם חישוב הנתונים.
לשם בניית CNN נדרשים 4 שלבים:
השלב הראשון, המכונה Convolution (קרי, מכפלה של פונקציות), פירושו פונקציה חדשה המתקבלת ממכפלת שתי פונקציות נתונות על ידי אינטגרציה שמבטאת את האופן שבו צורתה של פונקציה אחת משתנה או מותאמת על ידי הפונקציה השנייה. בבסיס פעולת הקונבולוציה עומדים 3 יסודות עיקריים:
- תמונת קלט (Input image): התמונה בפועל בפיקסלים (בעצם נתוני הקלט שלנו)
- גלאי מאפיינים (Feature detectors): ניתן לקרוא להם אפילו פילטרים. הגלאים הללו בעצם מגלים או מוצאים לנו מאפיינים (קרי, משתנים מסבירים) בתוך תמונת הקלט. גלאי מאפיינים ממוקמים מעל תמונת הקלט (למרות שהם הרבה יותר קטנים בגודלם) וסופרים את מספר התאים שבהם גלאי המאפיינים תואם לתת-קבוצה מסוימת של תמונת הקלט. לאחר מכן, גלאי המאפיינים מעביר לבד את תמונת הקלט על מנת לכסות את כל אזוריה. את המרחקים שגלאי המאפיינים עובר נהוג לכנות בשם "צעדים" ((strides.
- מפת מאפיינים (Feature map): מכילה את הארגומנטים שהוקלטו על ידי המסנן (Filter) על תמונת הקלט. הערך מתמונת הקלט מוכנס בתחילה לתא השמאלי העליון של מפת המאפיינים, והוא עובר בלוק ימינה, ומקליט את התצפית על כל אחד מהצעדים.

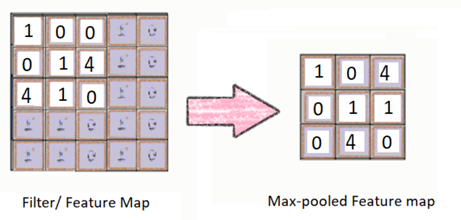
השלב השני מכונה Max Pooling (איחוד מקסימלי). מטרת האיחוד המקסימלי היא לאפשר ל- CNN לזהות תמונה כשהיא מוצגת עם שינוי בסיסי (מוזזת הצידה, לחילופין הפוכה לכדי תמונת ראי או לחילופי חילופין הפוכה מלמעלה למטה). בשלב זה אנו קובעים מפת המאפיינים המאוחדת.
הערה אינפורמטיבית: טכניקת ה- Max Pooling שונה מהתהליך ששימש לקביעת מפות המאפיינים בקונבולוציה.
טכניקת ה- Max Pooling כרוכה בהצבת מטריצה קטנה יותר על גבי מפת המאפיינים והכנסת הערך המקסימלי שבתוך המטריצה למפת המאפיינים המאוחדת שלנו. לאחר מכן אנחנו ממשיכים להתקדם ימינה עד אשר נמלא את כל הערכים, כפי שנעשה בשלב הקונבולוציה.
טכניקת ה- Max Pooling עניינה לימוד ה- CNN שלמרות כל ההבדלים הללו, עדיין מדובר בתמונות שמתארות או מאפיינות אותו דבר. על מנת לעשות זאת, על ה- CNN לרכוש תכונה המכונה "שונות מרחבית" (Spatial Variance), כך שבסופו של דבר הוא יוכל לזהות אובייקט בתמונה גם אם התמונה שונה מבחינה מרחבית מתמונה אחרת של אותו אובייקט. נעיר כי קיימות טכניקות איחוד נוספות, כגון איחוד ממוצע (Mean Pooling, אשר לוקח תאת הערך הממוצע במקום את הערך המקסימלי) ואיחוד הצבר (Sum Pooling, אשר לוקחת את סך הצברם של הערכים חלף הערך המקסימלי).
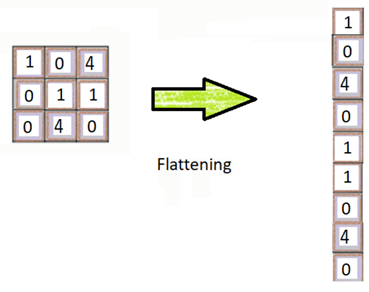
השלב השלישי מכונה Flattening (השטחה או שיטוח). משעה שהגענו לשלב ההשטחה, יש לנו כבר מפת מאפיינים מאוחדת. כפי ששמו של השלב עשוי לרמז, אנו הולכים לשטח את מפת המאפיינים המאוחדת שלנו ולהפוך אותה מצורה של מטריצה ריבועית לצורה של וקטור עמודה.
לאחר ההשטחה אנו מקבלים כאמור וקטור עמודה ארוך מאוד של נתוני קלט שאותו אנו מעבירים ב- CNN על מנת לעבד אותו הלאה. חשוב להבין שאילולא ביצענו את שלב ההשטחה, הרי שה- CNN לא יכול היה לקרוא את נתוני הקלט שלנו.
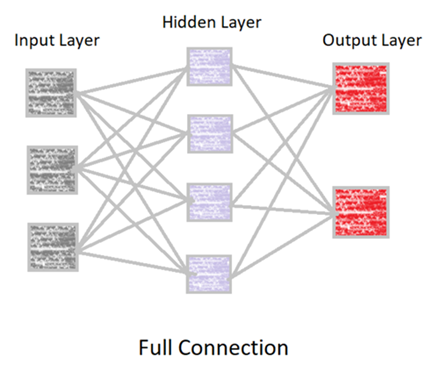
השלב הרביעי מכונה Full Connection (חיבור מלא). השכבה המחוברת במלואה ב- CNN זהה לשכבה הנסתרת ב- ANN. תפקידו של ה- CNN הוא לקחת את הנתונים הללו ולשלב את המאפיינים לכדי מנעד רחב יותר של מאפיינים אשר בתורם הופכים את ה- CNN לכזו המסוגלת לבצע זיהוי תמונות (Image Recognition) וזיהוי אובייקטים בתמונה (Object Recognition).
זהו גם השלב שבו אנו מחשבים את פונקציית השגיאה (Error Function) שאותה ה- CNN שלנו מביא בחשבון לפני ביצוע הסיווגים. ב- ANN ובמודלים של Machine Learning אנו מכנים את פונקציית השגיאה בשם פונקציית ההפסד (Loss Function). כעת, המכונה יכולה להקצות משקולות עבור כל אחת מהשכבות המחוברות במלואה על מנת לקבוע את התוצאה הבינארית של המשתנים הבלתי תלויים שלנו.
- בניית מודל סיווג חד-כיווני לזיהוי קורונה מתוך צילומי רנטגן
ראשית, אספתי 414 צילומי רנטגן חזה מתוך מערך תמונות הזמין לציבור. מתוכם 207 צילומי רנטגן חזה, אשר הוגדרו על ידי רדיולוגים מומחים כמצביעים על הימצאות של קורונה, הוכנסו לתיקיה בשם covid_set ו- 207 צילומי רנטגן חזה, אשר אינם מתארים קורונה (16 צילומי רנטגן של תמט הריאות, 16 צילומי רנטגן של לב מוגדל, 16 צילומי רנטגן של מיצוק, 16 צילומי רנטגן של בצקת ריאות, 16 צילומי רנטגן של בית חזה מוגדל, 16 צילומי רנטגן של שבר, 16 צילומי רנטגן של נגע בריאות, 16 צילומי רנטגן של אטימות ריאות, 16 צילומי רנטגן של תפליט קרום הריאה, 16 צילומי רנטגן של דלקת ריאות, 16 צילומי רנטגן של חזה אויר, 16 צילומים של התקנים תומכים ו- 15 צילומי רנטגן שפענוחם הוא שאין ממצא פתולוגי בחזה), הוכנסו לתיקיה בשם nocovid_set.
שנית, כתבתי פקודה ב- Python שמגרילה באופן אקראי 159 צילומי רנטגן חזה מתוך תיקיית covid_set, כ- 77% מצילומי הרנטגן שבתיקיה זו, ומכניסה אותם לתוך קבוצת "האימון" (Training set) המשמשת לבניית המודל. כתבתי פקודה נוספת שמגרילה באופן אקראי 159 צילומי רנטגן חזה מתוך תיקייתnocovid_set , כ- 77% מצילומי הרנטגן שבתיקיה זו, ומכניסה גם אותם לתוך קבוצת "האימון". לפיכך, קבוצת "האימון" שלי מונה 318 צילומי רנטגן חזה המחולקים ביחס של 50:50 לקטגוריית "קורונה" ו- "לא קורונה", בהתאמה.
שלישית, כתבתי פקודה ב- Python שמגרילה באופן אקראי 32 צילומי רנטגן חזה מתוך תיקיית covid_set, כ- 15% מצילומי הרנטגן שבתיקיה זו, ומכניסה אותם לתוך קבוצת "השיפור" (Validation set), המשמשת הן לשיפור מודל ה- CNN בטרם תיקופו על נתוני אמת, הן להקטנת פונקציית ההפסד (Loss Function) שלו והן להקטנת בעיית ה- Overfitting שלו על נתוני קבוצת "השיפור" ובכך להעלאת רמת המהימנות שלו על נתוני קבוצת "השיפור". כתבתי פקודה נוספת שמגרילה באופן אקראי 32 צילומי רנטגן חזה מתוך תיקייתnocovid_set , כ- 15% מצילומי הרנטגן שבתיקיה זו, ומכניסה גם אותם לתוך קבוצת "השיפור". לפיכך, קבוצת "השיפור" שלי מונה 64 צילומי רנטגן חזה המחולקים ביחס של 50:50 לקטגוריית "קורונה" ו- "לא קורונה", בהתאמה.
רביעית, כתבתי פקודה ב- Python שמגרילה באופן אקראי 16 צילומי רנטגן חזה מתוך תיקיית covid_set, כ- 8% מצילומי הרנטגן שבתיקיה זו, ומכניסה אותם לתוך קבוצת "הביקורת" (Test set), המשמשת להערכת ביצועי המודל. כתבתי פקודה נוספת שמגרילה באופן אקראי 16 צילומי רנטגן חזה מתוך תיקייתnocovid_set , כ- 8% מצילומי הרנטגן שבתיקיה זו, ומכניסה גם אותם לתוך קבוצת "הביקורת". לפיכך, כרגע קבוצת "הביקורת". שלי מונה 32 צילומי רנטגן חזה המחולקים ביחס של 50:50 לקטגוריית "קורונה" ו- "לא קורונה", בהתאמה.
יש לציין שהתייחסותי לקבוצת "הביקורת" הינה כאל נתוני אמת שיתקבלו רק לאחר יישום המודל במערך הייצור (Deployment) ועל כן צילומי הרנטגן חזה מקבוצה זו לא שימשו בשום שלב לאימון המודל אלא רק להערכת ביצועיו.
בראייתי, עולם ה- Deep Learning בדגש על רשתות נוירונים סובב סביב ארכיטקטורות שונות של רשתות נוירונים, להבדיל מעולם ה- Machine Learning שסובב סביב מודלים שונים לינאריים, א-לינאריים, מודלים של עצי החלטה, מודלים של יערות ומודלים של מרחקים אוקלידיים/מהנהטן.
הארכיטקטורה הפשוטה ביותר מורכבת משכבת כניסה אחת, שכבה נסתרת ושכבת יציאה, כאשר בכל שכבה ישנם מספר נוירונים, אשר מספרם נקבע שרירותית על ידי חוקר הבינה המלאכותית. באופן טבעי, מספר הנוירונים בשכבת הכניסה צריך להיות זהה למספר המאפיינים של התמונות. כך למשל, אם אנו הופכים כל תמונה למטריצה מסדר 224 X 224 פיקסלים (כאשר צבע לבן מקבל את הספרה 255, צבע שחור מקבל את הספרה 0 וכל היתר מקבלים את המספרים שבין 0 ל- 255) הרי שאנחנו צריכים 50,176 נוירונים בשכבת הכניסה. בשכבת היציאה, הואיל ומדובר בבעיית קלסיפיקציה בינארית אנחנו צריכים רק 2 נוירנוים, אחד עבור ההסתברות לכך שהתמונה שייכת לקטגוריית ה"קורונה" ואחר, המשלים ל- 1 של הראשון, עבור ההסתברות לכך שהתמונה שייכת לקטגוריית ה"לא קורונה". בשכבה הנסתרת, הלא היא שכבת הביניים אנחנו יכולים לבחור כל מספר נוירונים שעולה לנו לראש.
רק על מנת לסבר את האוזן, מודל הרגרסיה הלוגיסטית, שהוא המודל הפשוט והנפוץ ביותר לפתרון בעיות קלסיפיקציה (בינארית או מרובת-קטגוריות כאחד) שקול אפקטיבית מכל הבחינות האקונומטריות/הסטטיסטיות המהותיות לרשת נוירונים עם שכבה אחת (שהיא גם שכבת כניסה וגם שכבת יציאה) בעלת נוירון אחד ועם פונקציית אקטיבציה מסוג Sigmoid (פונקציית סיגמואיד).
לצורך בניית המודל, החלטתי שעדיף לעשות שימוש בארכיטקטורות מוכנות של ספריית Keras חלף בניית רשת נוירנוים מאפס בעצמי. לשם כך, בחנתי את 26 הארכיטקטורות של רשתות נוירונים הזמינות בחבילת הפיתוח Keras. להלן רשימת הארכיטקטורות:
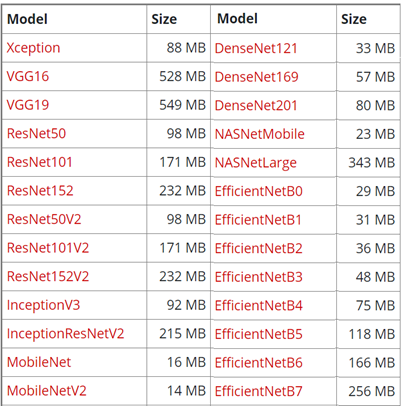
על פי ניסיוני המקצועי כחוקר AI, 5 הארכיטקטורות המובילות בתחום של עיבוד תמונה (Object recognition and object detection) הן: VGG16 (עם 23 שכבות), InceptionV3 (313 עם שכבות), MobileNet (עם 93 שכבות), Xception (עם 134 שכבות) ו- ResNet50 (עם 177 שכבות).
הבעיה של הארכיטקטורות הללו היא שהן נועדו לבעיית קלסיפיקציה מרובת-קטגוריות. כך למשל ארכיטקטורת ה- VGG16 היא המודל שזכה בתחרות ה- ImageNet לשנת 2014. בתחרות ה- ImageNet מספר רב של צוותים המתחרים האחד בשני מי יבנה את המודל שיסווג באופן הטוב ביותר תמונות מתוך ספריית ה- ImageNet, המורכבת מעשרות אלפי תמונות ששייכות ל- 1,000 קטגוריות שונות. דוגמא נוספת היא ארכיטקטורת ה- MobileNet. מדובר בסוג של CNN עמוק יותר מה- VGG16 (93 שכבות לעומת 23 שכבות), קטן יותר (מבחינת מגה-בייט) ומהיר יותר ממרבית הארכיטקטורות הפופולאריות. MobileNet היא למעשה ארכיטקטורה קטנה, שצורכת מעט משאבי מחשב ובעלת זמן שיהוי (Latency) נמוך ולכן היא משמשת לסיווג, זיהוי ואבחון ולבעיות נוספות ש- CNN נועד עבורן. בשל משקלה הקל יחסית של הארכיטקטורה היא פועלת מצויין על מכשירים ניידים ומכאן שמה – MobileNet.
כאמור, בשכבת היציאה של כל אחת מ- 5 הארכיטקטורות המוזכרות לעיל ישנם 1,000 נוירונים – היות וכל אחת מהן מתאימה לקלסיפיקציה ל- 1,000 קטגוריות. הואיל ובמקרה דנן שלפנינו, אנו נדרשים לסיווג ל- 2 קטגוריות בלבד: "קורונה" ו- "לא קורונה" – הרי שעלינו להתאים את שכבת היציאה של כל אחת מ- 5 הארכיטקטורות המוזכרות לעיל מ- 1,000 נוירונים ל- 2 נוירונים בלבד.
בעיה נוספת, נעוצה באופן שבו כל אחת מ- 5 הארכיטקטורות המוזכרות לעיל מתמירה את התמונה למטריצת פיקסלים. כך למשל, בעוד שהארכיטקטורות VGG16, MobileNet ו- ResNet50 הופכות כל תמונה למטריצה של מסדר 224 X 224 פיקסלים (קרי, 50,176 נוירונים בשכבת הכניסה) הרי שהארכיטקטורות Xceptionו- InceptionV3 הופכות כל תמונה למטריצה של מסדר 299 X 299 פיקסלים (קרי, 89,401 נוירונים בשכבת הכניסה).
משעה שכתבתי פקודה שתתמיר את התמונות לפורמט הפיקסלים המתאים עבור כל אחת מ- 5 הארכיטקטורות המוזכרות לעיל, התחלתי לאמן את 5 מודלי ה- CNN שלי על נתוני קבוצת "האימון" באמצעות batch size של 10 (קרי, 10 תמונות שונות מתוך קבוצת "השיפור" שישמשו עבור כל Backpropagation) ו- epochs של 10 (קרי, 10 פעמים שנעבור על כל התמונות שבקבוצת "האימון").
למעשה אימנו את המודל באמצעות 10 איטרציות בלבד, כאשר בכל איטרציה המודל בחר אקראית 10 תמונות מתוך קבוצת "השיפור" ובאמצעותן הוא בדק את מידת המהימנות של המודל באותה האיטרציה. תהליך זה נועד להעלאת רמת המהימנות של המודל על נתוני קבוצת "השיפור" והקטנת בעיית התאמת היתר (Over-fitting). בעיית התאמת היתר הינה בעיה באקונומטריקה שבה המודל מותאם יתר על המידה לנתוני קבוצת "האימון" (אשר שימשו לבניית המודל) ולכן הוא מצליח פחות ביצירת סיווגים נכונים לנתונים אשר לא שימשו לבנייתו. לבסוף, קיבלתי 5 מודלים שונים של CNN.
על מנת להעריך את ביצועי 5 המודלים שבניתי היה עליי לתקפם באמצעות התמונות שבקבוצת "הביקורת". להלן מדדי הביצועים שקיבלתי עבור 5 המודלים שאותם אימנתי על התמונות שבקבוצת "האימון" ותיקפתי באמצעות התמונות שבקבוצת "הביקורת":

מהטבלה לעיל, עולה שמודל ה- VGG16 שבניתי "עולה" על כל יתר המודלים מבחינת כל מדדי הביצועים ועל כן בחרתי בו כמודל הנבחר.
- הערכת ביצועי המודל הנבחר
בעולמות הקלסיפיקציה קיימים 5 מדדים מובילים להערכת ביצועי סיווג.
המדד הראשון, המכונה מדד המהימנות Accuracy), מדד הערכה שרלוונטי למודלי סיווג דו-כיווניים), אומר לנו כמה מצילומי הרנטגן חזה ("קורונה" ו- "לא קורונה" כאחד) סיווגתי נכון מתוך סך צילומי הרנטגן חזה ("קורונה" ו- "לא קורונה" כאחד) הקיימים בקבוצת "הביקורת".
מדד המהימנות של מודל ה- VGG16 שאימנתי עמד על כ- 96.88% הואיל והמודל סיווג נכון 31 צילומי רנטגן חזה (16 צילומי רנטגן חזה "קורונה" ו- 15 צילומי רנטגן חזה "לא קורונה") מתוך 32 צילומי רנטגן חזה שבקבוצת "הביקורת" (16 צילומי רנטגן חזה "קורונה" ו- 16 צילומי רנטגן חזה "לא קורונה").
להלן מטריצת הטעות (Confusion Matrix) של מודל ה- VGG16 שאימנתי על צילומי הרנטגן חזה שבקבוצת "הביקורת":

מהסתכלות על מטריצת הטעות שלנו ניתן ללמוד שמתוך 32 סיווגים שמודל ה- VGG16 שאימנתי ביצע על צילומי הרנטגן חזה שבקבוצת "הביקורת", 31 מהם היו נכונים ורק אחד מהם לא היה נכון ולכן מדד המהימנות שלנו הוא 96.88% (31 מתוך 32).
להלן דו"ח הקלסיפיקציה (Classification Report) של מודל ה- VGG16 שאימנתי על צילומי הרנטגן חזה שבקבוצת "הביקורת":
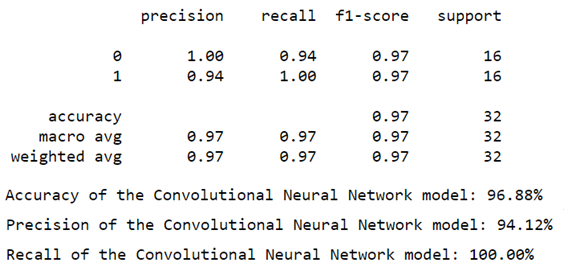
המדד השני, המכונה מדד הרגישות Recall), מדד הערכה שרלוונטי למודלי סיווג חד-כיווניים), אומר לנו כמה צילומי רנטגן חזה סיווגתי נכון כ"קורונה" מתוך סך כל צילומי הרנטגן חזה "קורונה" הקיימים בקבוצת "הביקורת". כמובן שלא נרצה כמובן לפספס צילומי רנטגן חזה מסוג "קורונה". מדד הרגישות של מודל ה- VGG16 שאימנתי עמד על כ- 100% הואיל והמודל סיווג נכון 16 צילומי רנטגן חזה "קורונה" מתוך 16 צילומי הרנטגן חזה "קורונה" שבקבוצת "הביקורת".
כלומר- לא היה מצב שהמודל של ראה צילום רנטגן חזה של קורונה ולא זיהה אותו כ"קורונה". במילים אחרות- לא הכנסתי אף חולה קורונה שהגיע לחדר המיון של בית החולים "דן החולה" עם התסמינים למחלקה פנימית בבית החולים. כמובן שנרצה מדד הרגישות כמה שיותר גבוה, כי אם לא ניתן טיפול רפואי מתאים לחולה קורונה – אז פעם אחת הוא ימות ופעם שניה עד שהוא ימות הוא ידביק לנו את יתר החולים ואנשי הצוות במחלקה הפנימית. כאמור מדד הרגישות מודד את רגישותו של המודל לתוצאות מצב הטבע השלילי בלבד.
המדד השלישי, המכונה מדד הדיוק (Precision, עוד מדד הערכה שרלוונטי למודלי סיווג חד-כיווניים), מדד הדיוק אומר לנו כמה מתוך כלל צילומי הרנטגן חזה שסיווגתי כ"קורונה" (בין אם הסיווג היה נכון ובין אם הוא היה שגוי), באמת היו צילומי הרנטגן חזה "קורונה". מדד הדיוק של מודל ה- VGG16 שאימנתי עמד על כ- 94.12% הואיל ומתוך מתוך 17 צילומי הרנטגן חזה שהמודל סיווג כ"קורונה" רק 16 מהם באמת היו צילומי רנטגן חזה "קורונה". במילים אחרות- הכנסתי חולה עם תמט ריאות, או דלקת ריאות או בצקת בריאות לתוך מחלקת קורונה– מדובר בבעיה קלה יחסית היות ולמרות שלאותו מטופל יינתן טיפול רפואי נגד קורונה כאשר הוא עדיין איננו חולה קורונה, הרי שמהר מאוד הוא ידבק בקורונה על ידי יתר החולים במחלקת הקורונה – כך שהטיפול בסופו של דבר יעזור לו. בנוסף, הוא לא ידביק בקורונה את הצוות הרפואי שיטפל בו – היות והצוות הרפואי במחלקת הקורונה ממוגן מכף רגל ועד ראש.
המדד הרביעי, מכונה מדד ה- F1-Score (מדד הערכה נוסף שרלוונטי למודלי סיווג חד-כיווניים). כאשר אנו מסתכלים על מדד המהימנות, הרי שאנו יכולים לתת לו משמעות אמיתית, כלומר לדבר על צילומי רנטגן חזה "קורונה" וצילומי רנטגן חזה "לא-קורונה" וכדומה. במדד הדיוק אני יכול לדבר ב"חיבור לשטח", על משהו שבאמת קרה, אבל למדד ה- F1-Score אין שום משמעות פיזיקלית, היות ומדובר במניפולציה מתמטית על מספרים (אין שום משמעות אחרת להכפלת מדד הדיוק במדד הרגישות וב- 2 וחלוקת התוצאה בסכום של מדד הדיוק ומדד הרגישות).
כלומר- אני לא יכול לקחת F1-Score של מודל ה- VGG16 שאימנתי שעמד על כ- 96.97% ולספר סיפור. במילים אחרות- אם אני הולך לכיוון של לספר סיפור, אז כשיש לי מדד מהימנות של 96.88% אז אני יכול לספר את הסיפור שמתאים לזה או סיפור שמסביר מה המשמעות של זה. כשיש לי מדד רגישות של 100% אני יכול לספר את הסיפור כמו שסיפרתי אותו מקודם. כשיש לי מדד דיוק של 94.12% אני יכול לספר סיפור ש"מתחבר לשטח", דהיינו, כזה שמתחבר לצילומי רנטגן חזה "קורונה", לצילומי רנטגן חזה "לא-קורונה" וכו'. מאידך, מדד ה- F1-Score הוא בסך הכל מניפולציה מתמטית על מדד הדיוק ומדד הרגישות והמספר שיצא לנו בסוף, אותו 96.97%, אני לא יודע לספר עליו סיפור מעבר להגיד שזה 2 כפול מדד הדיוק כפול מדד הרגישות חלקי הסכום שלהם.
נזכיר כמובן שמדד ה- F1-Score משמש להשוואה בין מודלי סיווג חד-כיווניים. לדוגמא, בתחרות הדאטה סיינטיסטים של מכללת ג'ון ברייס, ה- Maximum F1-Score Challenge, שבה התחרתי ביולי השנה מול מדעני נתונים נוספים במטרה לבנותMachine Learning Classification Project (בעולם של Extreme Imbalanced Data) שייתן את מדד ה- F1-Score המקסימלי ושבה זכיתי במקום הראשון (First Place Award) עם האלגוריתם שזכה לכינוי " A Support Vector Classifier for a Credit Decision System using Synthetic Minority Oversampling Technique and Hyperparameter Optimization ", אימנתי מודלים רבים של למידת מכונה והשוותי ביניהם באמצעות פרטמטר אחד, מדד ה- F1-Score (ככל שהוא גבוה יותר, כך המודל מביא לאופטימיזציה טובה יותר של מדד הדיוק ומדד הרגישות).
המדד החמישי, המכונה מדד איכות הניבוי ROC AUC), מדד הערכה אחר שרלוונטי למודלי סיווג חד-כיווניים), אומר לנו הן מבחינה מספרית והן מבחינה גרפית מהו איכות הניבוי של המודל שלנו ביחס לאיכות הניבוי של הטלת מטבע הוגן. ניקח מלבן ונחצה אותו לשני משולשים ישרי זווית חופפים באמצעות מתיחת אלכסון אדום מקווקו מהקצה השמאלי התחתון של המלבן ועד לקצהו הימני העליון. כידוע השטח של המלבן, ממש כמו השטח שכלוא מתחת לכל פונקציית התפלגות, הינו 100%. האלכסון האדום המקווקו שמתחנו יצר לנו 2 משולשים ישרי זווית שכל אחד מהם תופס 50% משטח המלבן. אם נגדיר את המשולש הימני כמצב בו אנו מזהים קורונה בצילומי רנטגן חזה באמצעות הטלת מטבע הוגן הרי שאיכות הניבוי במצב שכזה הינה 50%. יש לתת את הדעת לכך שגם אם אנו מסתכלים על צילום רנגטן חזה ואנחנו לא יודעים להבדיל בין קורונה ל"לא קורונה" עדיין יש לנו סיכוי של 50% לנחש נכון האם מדובר בקורונה או לא.
הערה אינפורמטיבית: בהרצאה הראשונה בלימודי אקטואריה אני מלמד את הסטודנטים שכאשר מישהו אומר שאין לו יכולת להסביר סיכוי מסוים או הסתברות מסוימת ועל כן הוא בחר ב- 50%, הרי שהוא למעשה אומר שהוא לוקח בחשבון את כל המצבים השונים אפשריים בהתפלגות שווה מ- 0% ועד 100%, ואז התוחלת היא 50%. זה נקרא בעגה האקטוארית מרחב הסתברות אחיד.
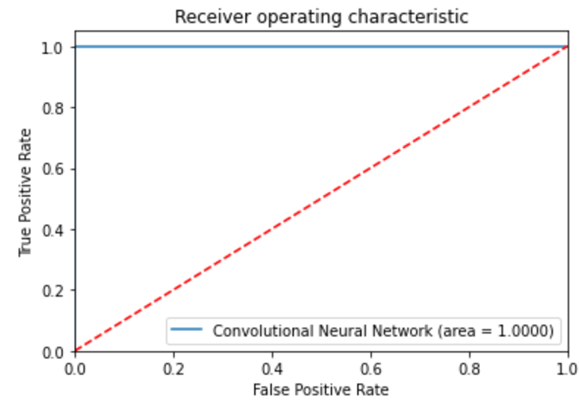
משעה שהגדרנו את המשולש הימני כמודל שמנחש אקראית או מבצע הטלת מטבע בכל פעם שהוא נדרש להחליט האם צילום רנטגן חזה מסוים הוא "קורונה" או "לא קורונה" ובהנחה שמראים לו אלפי תמונות – הרי שאיכות הניבוי שלו היא 50%. ה- Python מגדיר לנו את מודל ה- CNN לזיהוי קורונה באמצעות הקו הכחול והוא קבע שאיכות הניבוי שלו היא 100%.
נזכיר כמובן שמדד ה- F1-Score משמש להשוואה בין מודלי סיווג חד-כיווניים. לדוגמא, בתחרות הדאטה סיינטיסטים של מפא"ת (מינהל למחקר, פיתוח אמצעי לחימה ותשתית טכנולוגית), ה- MAFAT Radar Challenge, שבה התחרתי השנה במדעני נתונים נוספים על מנת לבנות Machine Learning Classification Project לבעיית Semi-Supervised Learning שייתן את מדד ה- ROC AUC המקסימלי, אימנתי מודלים רבים של למידת מכונה והשוותי ביניהם באמצעות פרטמטר אחד, מדד ה- ROC AUC.
- סיכום ומסקנות
המניע המרכזי לכתיבת עבודה זו הוא הצורך באבחון מוקדם של נגיף הקורונה, בהיעדר זמינות של תרופה או חיסון למחלה, על מנת לאפשר בידוד מיידי של האדם החשוד כנשא קורונה ובכך להפחית את הסיכוי לזיהום בקרב אוכלוסייה בריאה.
כדי לבצע משימה זו, בניתי מודל מתקדם של Deep Learning לזיהוי קורונה מתוך צילומי רנטגן חזה, על ידי ביצוע קליברציה ל- 5 ארכיטקטורות של רשתות נוירונים קונבולוציוניות (VGG16, InceptionV3, MobileNet, Xception ו- ResNet50) שאומנו על קבוצת "האימון" ושופרו באמצעות קבוצת "השיפור".
לשם העבודה, אספתי מערך נתונים של כ- 414 צילומי רנטגן חזה מתוך מערך תמונות הזמין לציבור. מתוכם 207 צילומי רנטגן חזה אשר הוגדרו כ"קורונה" ו- 207 צילומי רנטגן חזה אשר הוגדרו כ"לא קורונה" (16 צילומי רנטגן של תמט הריאות, 16 צילומי רנטגן של לב מוגדל, 16 צילומי רנטגן של מיצוק, 16 צילומי רנטגן של בצקת ריאות, 16 צילומי רנטגן של בית חזה מוגדל, 16 צילומי רנטגן של שבר, 16 צילומי רנטגן של נגע בריאות, 16 צילומי רנטגן של אטימות ריאות, 16 צילומי רנטגן של תפליט קרום הריאה, 16 צילומי רנטגן של דלקת ריאות, 16 צילומי רנטגן של חזה אויר, 16 צילומים של התקנים תומכים ו- 15 צילומי רנטגן שפענוחם הוא שאין ממצא פתולוגי בחזה).
חילקתי את מערך התמונות שלי ל- 318 צילומי רנטגן חזה המכונים קבוצת "האימון" ביחס של 50:50 ל"קורונה" ו"לא קורונה", ל- 64 צילומי רנטגן חזה המכונים קבוצת "השיפור" ביחס של 50:50 ל"קורונה" ו"לא קורונה" ול- 32 צילומי רנטגן חזה המכונים קבוצת "הביקורת" ביחס של 50:50 ל"קורונה" ו"לא קורונה".
את 5 המודלים שאימתי, התאמתי תחילה לכך שהבעיה שניצבת בפניי הינה בעיית קלסיפיקציה בינארית ולא קלסיפיקציה רבת-קטגוריות, שהיא הבעיה שלשמה נועדו אותם מודלים מלכתחילה.
בגמר אימון 5 המודלים על קבוצת "האימון" עברתי לתיקוף והערכת המודלים על התמונות שבקבוצת "הביקורת". המודל הטוב ביותר מבין כל 5 המודלים, על פי כל 5 מדדי הערכה שבדקתי, הינו מודל ה- VGG16 אשר זכה בתחרות ה- ImageNet לשנת 2014 כמודל הטוב ביותר לסיווג עשרות אלפי תמונות ל- 1,000 קטגוריות שונות.
מטריצת הטעות, שנבנתה על סמך סיווגי מודל ה- VGG16 שאימנתי את צילומי רנטגן החזה הקיימים בקבוצת "הביקורת", מספרת לנו שמתוך 32 סיווגים שמודל ה- VGG16 ביצע, 31 מהםהיו סיווגים נכונים ורק אחד מהם לא היה נכון ולכן מדד המהימנות (Accuracy) של המודל הוא 96.88%.
מדו"ח הקלסיפיקציה, שנבנה על סמך מטריצת הטעות האמורה, עולה כי מדד הרגישות (Recall) של מודל ה- VGG16 שלנו עמד על כ- 100% הואיל ומודל ה- VGG16 שאימנתי סיווג נכון כ"קורונה" 16 צילומי רנטגן חזה מתוך 16 צילומי רנטגן חזה "קורונה" שהיו בקבוצת "הביקורת".
עוד עולה מדו"ח הקלסיפיקציה כי מדד הדיוק (Precision) של מודל ה- VGG16 שאימנתי עמד על כ- 94.12% הואיל ומתוך 17 צילומי רנטגן חזה בקבוצת "הביקורת" שמודל ה- VGG16 שאימנתי סיווג כ"קורונה", רק 16 מהם באמת היו צילומי רנטגן חזה "קורונה". כלומר- צילום רנטגן אחד שהיה בפועל "לא קורונה" המודל סיווג בטעות כ"קורונה".
בנוסף, מדד ה- F1-Score של מודל ה- VGG16 שאימנתי עמד על 96.97% ומדד ה- ROC AUC שלו עמד על 100% (פי 2 טוב יותר מניחוש מקרי על ידי הטלת מטבע הוגן).
בהתחשב בשיעור העצום של חשודים כנשאי קורונה ובמספר המוגבל של רדיולוגים מומחים המסוגלים לפענח אנומליות כה עדינות בצילומי רנטגן חזה כקורונה, הרי שרק מודלים של Deep Learning, כמו אלו שבניתי, יכולים לסייע בהליך האבחון ולהעלות הן את קצב האבחון המוקדם והן את רמת הדיוק שלו.
התוצאות שקיבלתי אכן מעודדות, מכיוון שהן מסמנות את השימוש בצילומי רנטגן חזה לזיהוי קורונה כמבטיח.
עבודה זו שבוצעה על מערך תמונות הזמינות לציבור הינה, למיטב ידיעתי, המחקר האמפירי הראשון בישראל שעושה שימוש בצילומי רנטגן חזה לזיהוי קורונה.
עם זאת, בשל המספר המוגבל של צילומי רנטגן חזה שפוענחו כקורונה, הזמינים לציבור, הרי שיש צורך בעריכת ניסויים נוספים על מערך גדול יותר של צילומי רנטגן חזה של קורונה לצורך קבלת הערכה מהימנה יותר הן של מדד הדיוק והן של מדד הרגישות, הן על 5 המודלים שבחנתי והן על מודלים נוספים שטרם נבדקו על ידי.
ביבליוגרפיה
פולניצר, רועי (2020), "למידה עמוקה (Deep Learning) על קצה המזלג", סטטוס – כתב עת לחשיבה ניהולית ואסטרטגית, אוקטובר.
Ai, Yang, Hou, Zhan, Chen, Lv, Tao, Sun, Xia (2020). "Correlation of Chest CT and RT-PCR Testing for Coronavirus Disease 2019 (COVID-19) in China: A Report of 1014 Cases", Radiology.
Cohen, Morrison, Dao, (2020). "COVID-19 Image Data Collection".
Hansell, Bankier, MacMahon, McLoud, Muller, Remy (2008). "Fleischner Society: Glossary of Terms for Thoracic Imaging", Radiology, 246 (3), pp. 697-722.
Kanne, Little, Chung, Brett, Ketai (2020). "Essentials for Radiologists on COVID-19: An Update—Radiology Scientific Expert Panel", Radiology.
Kong, Agarwal (2020). " Chest Imaging Appearance of COVID-19 Infection", Radiology.
Rodrigues, et al (2020). "An Update on COVID-19 for the Radiologist – a British Society of Thoracic Imaging Statement", Clinical Radiology.
Wang, Xu, Gao, Lu, Han, Wu, Tan (2020). "Detection of SARS-CoV-2 in Different Types of Clinical Specimens", JAMA.
Yang, Yang, Shen, Wang, Yuan, Li, Zhang, et al (2020). "Evaluating the Accuracy of different Respiratory Specimens in the Laboratory Diagnosis and Monitoring the Viral Shedding of 2019-nCoV Infections", MedRxiv.
מידע על מחבר התזה

חוקר בינה מלאכותית (AI) המבצע מחקר ומפתח אלגוריתמים על כמויות גדולות של מידע. בעל תואר ראשון בכלכלה ותואר שני במנהל עסקים ואקטואריה שניהם עם התמחות במדע נתונים (כלכלה אמפירית) ולמידת מכונה (אקונומטריקה), בהצטיינות ומאוניברסיטת בן גוריון-בנגב.
בעל ידע תיאורטי מבוסס וניסיון פרקטי מוצק בתחומי מדע הנתונים ולמידת המכונה המגובה הן בהסמכה בינלאומית "מנהל סיכונים פיננסיים" (FRM- Financial Risk Manager) מטעם האיגוד העולמי למומחי סיכונים (GARP- Global Association of Risk Professionals) והן בהסמכה ישראלית "מנהל סיכונים מוסמך" (CRM- Certified Risk Manager) מטעם האיגוד הישראלי למנהלי סיכונים (IARM- Israeli Association of Risk Managers).
בעל ידע תיאורטי מבוסס בסטטיסטיקה תיאורית, הסתברות, הסקה סטטיסטית, סטטיסטיקה א-פרמטרית ולמידה סטטיסטית וניסיון פרקטי במידול תנועות סטוכסטיות, ניתוח סדרות עתיות, שימוש בשיטות מונטה קרלו, קירוב סדרות נתונים להתפלגויות אנליטיות, בניית מודלים ליניאריים ויישום שיטות סטטיסטיות/אקונומטריות המגובה בהסמכת "אקטואר מלא" (Fellow) מטעם לשכת מעריכי השווי והאקטוארים הפיננסיים בישראל (IAVFA- Israel Association of Valuators and Financial Actuaries) ובלימודים לא לתואר בתוכנית ללימודי אקטואריה באוניברסיטת חיפה.
בעל ידע תיאורטי בבינה מלאכותית המגובה הן בדיפלומה ב-Data Science, Machine Learning and Deep Learning with Python ממכללת ג'ון ברייס (לאחר סיום בהצלחה של תוכנית הכשרה יוקרתית בת 500 שעות שכולה על טהרת ה- Python) והן בהסמכות ישראליות, כגון:
"מפתח פייתון מוסמך" (CPD- Certified Python Developer), "מנתח נתונים בפייתון" (PDA- Python Data Analyst), "מומחה ללמידת מכונה" (MLS- Machine Learning Specialist), "מוסמך בלמידה עמוקה" (Accredited in Deep Learning) ו- "מדען נתונים מקצועי" (PDS- Professional Data Scientist) כולן מטעם האיגוד הישראלי למדעני נתונים מקצועיים (PDSIA- Professional Data Scientists' Israel Association).

בעל ניסיון פרקטי בבינה מלאכותית כמפתח בשפות Python (עם שליטה בספריות Numpy, Pandas, Scikit-learn, Tensorflow, ו- (Keras ו- Pyspark (עם שליטה בספריית הפיתוח MLlib) מרצה לשפות Python ו- R (שפת תכנות מדעית סטטיסטית) ובעל ניסיון מוכח (באמצעות פרוייקטים ב- Github), הן בתחום ה- Applied Machine Learning הכולל בניית מודלים לבעיות רגרסיה (Regression), מודלים לבעיות סיווג (Classification), מודלים לבעיות ניתוח אשכולות (Clustering), מנועי המלצה (Recommendation system) באמצעות למידה ללא השגחה (unsupervised) ומודלים לבעיות אנומליות (Anomaly detection) והן בתחום ה-Applied Deep Learning הכולל עיבוד שפה טבעית וניתוח טקסט (Natural Language Processing and Text Mining) ומודלים לבעיות זיהוי תמונות (Image Recognition) וזיהוי אובייקטים בתמונה (Object Recognition) באמצעות רשתות נוירונים (כגון: Multi-layer perceptron, Recurrent neural networks, LSTM ו- Convolution and pooling).
מגזין "סטטוס" מופק ע"י:
Tags: מדע נתונים קורונה


