































































הצעה לשיתוף פעולה עם בית חולים או קופת חולים בפרוייקט חדשני לאבחון קורונה באמצעות עיבוד מאפייני הדיבור והקול של נבדקים. המחקר צפוי לאפשר הליך בדיקה ראשוני, זמין, נוח ופשוט לאבחון מהיר של הנגיף. בכך, ניתן יהיה להגיע בצורה פשוטה ומהירה לקהל היעד שיש לבדוק, להגדיל את אפקטיביות תהליכי הבדיקה, לאבחן נדבקי קורונה כבר בשלבים הראשונים של המחלה ולעצור את שרשרת ההדבקה
פורסם:23.11.20 צילום: shutterstock
פתח דבר
בשלושה חודשים האחרונים ביצעתי מספר פרויקטים בתחום של עיבוד אותות וזיהוי קולות באמצעות בינה מלאכותית. בהתחלה ביצעתי פרויקט קלסיפיקציה בינארית פשוטה שבו סיווגתי 13,125 דגימות דיבור (הקלטות) ל- 2 קטגוריות מגדריות: "זכר" ו- "נקבה". לאחר מכן, ביצעתי פרויקט קלסיפיקציה מרובת-קטגוריות שבו סיווגתי 5,435 דגימות קול ל- 10 קטגוריות של רעשים עירוניים (כגון: פטיש אויר, מוזיקת רחוב, סירנה, מזגן, מנוע של מכונית, קדיחה, נביחת כלב, ילדים משחקים, צופר של מכונית ויריית אקדח). ולבסוף ביצעתי פרויקט קלסיפיקציה מרובת-קטגוריות נוסף שבו סיווגתי את אותן 13,125 דגימות דיבור, מהפרויקט הראשון, ל- 115 דוברים שונים (נשים וגברים). כאן למעשה נוצרה אצלי ההבנה שאפשר וכדאי לנסות לאבחן קורונה באמצעות זיהוי דיבור, מבלי להלאות בדבר הצורך הלאומי בכלי אבחון מקדימים-מדויקים-מהירים-וזולים לנשאי קורונה א-סימפטומטים.
בתחילת אוקטובר האחרון קראתי מאמר שהתפרסם ב- IEEE Journal of Engineering in Medicine and Biology על ידי החוקרים Laguarta Hueto and Subirana. במאמר זה החוקרים הראו כי ניתן לאבחן חשודים לקורונה (ובייחוד א-סיפטומטיים), ברמת מהימנות (Accuracy) גבוהה, מתוך הקלטות שמע (Audio clips) בסמארטפון של שיעול מאולץ באמצעות פיתוח אלגוריתם של בינה מלאכותית. החוקרים לקחו מדגם של 5,320 נבדקים (2,660 שיצאו חיוביים לקורונה ו- 2,660 שיצאו שליליים לקורונה בבדיקת מטוש) ופיצלו אותו: 80% לקבוצת "אימון" (ביחס 50:50 חיובי לקורונה ושלילי לקורונה) אשר שימשה לבניית המודל ו- 20% לקבוצת "ביקורת" (ביחס 50:50 חיובי לקורונה ושלילי לקורונה) אשר שימשה לתיקוף המודל. על המדגם הכולל (של סימפטומטים וא-סימפטומטים כאחד) החוקרים הגיעו לרמת רגישות (Recall) של 98.5% ולרמת דיוק (Precision) של 94.2% על נתוני קבוצת "הביקורת" (שלא שימשו כאמור לבניית המודל), כאשר יעילות הניבוי (AUC) שעליה דיווחו החוקרים עמדה על 97% בהשוואה ל- 50% בלבד בהטלת מטבע הוגן. על מדגם הא-סימפטומטים, החוקרים הגיעו לרמת רגישות של 100% ולרמת דיוק של 83.2% על קבוצת ה"ביקורת" המתאימה. למעשה החוקרים הוכיחו כי פעם אחת אבחון קורונה באמצעות עיבוד אותות ובינה מלאכותית הוא אולי אחת הדרכים המהירות והמדויקות ביותר לאבחון נשאים א-סימפטומטים ופעם שנייה שלפתרונות שקיימים כיום ניתן להוסיף פתרון נוסף – והוא אבחון באמצעות ניתוח הקול של הנבדקים. כאמור, הממצאים של החוקרים מעידים על פוטנציאל זיהוי פנטסטי.
מכאן החלטתי כי מטרתי לחקור ולהתעמק בנושא זה – וכי לצורך כך אצטרך לשתף פעולה עם גוף בעל גישה לבסיסי נתונים של נבדקים רבים. בסיס הנתונים הנדרש הינו כאמור דגימות קול ודיבור (הקלטות) משני סוגים: של נבדקים שיצאו חיוביים לקורונה ושל נבדקים שיצאו שליליים לקורונה (בבדיקה רשמית כמובן). למיותר לציין כי בתי חולים או קופות החולים אשר מבצעים את בדיקות המטוש הם השותפים הטבעיים למחקר זה, היות ולהם יש את הממצאים הן של מי שנבדק ונמצא חיובי והן של מי שנבדק ונמצא שלילי.
באמצעות שיתוף פעולה עם אותם שותפים טבעיים כאמור, ניתן יהיה לאסוף מדגם של הקלטות ולהגיע לתוצאות של כלי נוסף שיוכל לבצע את הבדיקות. השאיפה היא שמעתה ואילך, בכל בדיקת מטוש, נבדקים יוקלטו מדברים מספר מסוים של שניות.
כאמור, מדובר במחקר שעשוי להניב תוצאות משמעותיות בתוך זמן קצר.
את המאמר הזה כתבתי כהוכחת היתכנות (POC- Proof Of Concept) לרעיון שלי במטרה להוכיח פוטנציאל ממשי ליישומו. מאחר והמטרה היא רק להוכיח שקיימת היתכנות, הרי שההדגמה היא על פי רוב מימוש חלקי או קטן של הפתרון הכולל.
בעולם הסטרטאפים, שאיתו אני מצוי באינטרקציה אינטנסיבית מזה כעשור בכובע של מעריך שווי חברות ונכסי קניין רוחני, הוכחת ההיתכנות היא למעשה ההוכחה כי המיזם הינו בר קיימא מבחינה כלכלית ו/או טכנולוגית ולכן היא נדרשת לעיתים קרובות לצורך גיוס הון ראשוני.
לעצם המאמר, מגפת ה- COVID-19 (להלן: "הקורונה") שינתה את חיינו באופן דרסטי ובגינה ננקטו צעדים חסרי תקדים על מנת למזער את התפשטות נגיף הקורונה החדש. נכון למועד כתיבת מאמר זה, ישנם כבר מעל ל- 58 מיליון מקרי קורונה מאומתים עם יותר מ- 1.39 מיליון מקרי מוות ברחבי העולם מהמגיפה.
מוזרותה של הקורונה מתבטאת בכך שתסמיניה עשויים שלא להופיע אפילו עד 14 יום מרגע ההדבקה, מה שמהווה אתגר עצום לעצירת התפשטות המגיפה, אשר נכון לזמן כתיבת שורות אלה ישנם יותר מ- 660 אלף קורונה מאומתים מדי יום ברחבי העולם.
אבחון מוקדם של תסמינים, בדיקת נבדקים סימפטומטיים ובידוד של נבדקים אשר נמצאו חיוביים לקורונה הינם הכרחיים וחיוניים לעצירת התפשטות המגיפה, בהיעדר טיפול או תרופה לקורונה.
במאמר זה אציג, סקירה כללית אודות האפשרות להשתמש בדיבור לאבחון תסמיני קורונה בשלב מוקדם, הרבה לפני שהתופעות מתחילות להופיע. בנוסף לאבחון מוקדם, לשימוש בדיבור לצורך זיהוי תסמיני קורונה יתרונות נוספים, כגון: עלות נמוכה, זמינות גבוהה, היעדר הצורך במכשירים רפואיים מורכבים ויקרים ו/או אפילו באנשי מקצוע מומחים לרפואה לצורך איתור ראשוני של סימפטומטים. למעשה, אפליקציה במכשיר הנייד יכולה לנתח את הדיבור של נבדקים על מנת לזהות תסמיני קורונה ולהתריע הן בפני המשתמש והן בפני גורמי הבריאות הרלוונטיים.
- מבוא
מחלת וירוס הקורונה הינה מחלה שמתפשטת במהירות ופוגעת במדינות בכל רחבי העולם. על פי ארגון הבריאות העולמי (WHO), המקרה הראשון דווח בעיר ווהאן שבסין ומספר המתים מהמחלה ברחבי העולם גדל משמעותית מאז.
אי הבנה מלאה של הנגיף החדש, התפשטותו המהירה ברחבי העולם והיעדר אסטרטגיות טיפוליות ומונעות כאחד הובילו את ועדת תקנות החירום הבינלאומיות של ה- WHO להכריז על המחלה כעל מצב חירום בינלאומי של בריאות הציבור ב- 30 בינואר 2020.
אבחון ואיתור נשאי קורונה הינם הנהלים החשובים ביותר שאותם מבצעים עובדי מערכת הבריאות במטרה להביס את המגיפה. ברם, הפרודצרות הקיימות צורכות זמן רב, מה שמוביל לסיכון מוגבר להדבקה, לחלות במחלות קשות ואף למוות.
על פי ה- WHO (2020), התסמינים השכיחים ביותר של קורונה הינם: חום, עייפות ושיעול יבש (להלן: "תסמיני הקורונה"). במקרים מסוימים, תסמינים אלו עשויים להיות מלווים גם בקשיי נשימה, כאבים, גודש באף, נזלת, כאבי גרון ושלשולים. מוזרותה של הקורונה מתבטאת בכך שתסמיניה עשויים שלא להופיע אפילו עד 14 יום מרגע ההדבקה (בממוצע לוקח 5-6 ימים עד שהתסמינים מופיעים בצורה בולטת). מוזרות זו מציבה את אחד האתגרים הגדולים ביותר לקטיעת התפשטות הקורונה.
במאמר זה אציג מנגנון לאבחון תסמיני קורונה הרבה לפני שהם מופיעים אצל הנדבק, כך שניתן יהיה לבודד אותו, לאבחן אותו ולספק לו טיפול רפואי בשלב הרבה יותר מוקדם.
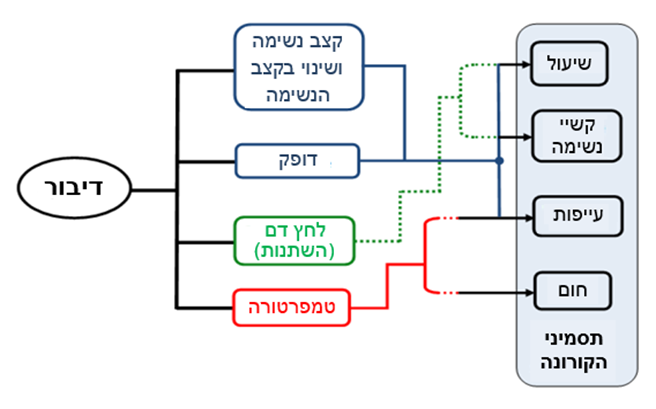
בתחילתם, בעוד שתסמיני הקורונה עשויים עדיין להיות סמויים, הם כבר גורמים לשינויים עדינים במאפייני הדיבור אשר אותם ניתן לזהות באמצעות אלגוריתמים של בינה מלאכותית. לאמור- ניתן לעשות שימוש באותות דיבור של אנשים בכפיפה אחת עם עיבוד אותות ובינה מלאכותית על מנת לאתר ולזהות פרמטרים ביולוגיים חיוניים (כגון: טמפרטורת גוף, דופק, לחץ דם ושינויים בלחץ דם, קצב נשימה ושינויים בקצב הנשימה) הקשורים במישרין או בעקיפין לתסמיני הקורונה.
בהתבסס על ספרות מקצועית, קיים מתאם בין מאפייני דיבור לבין מצבים פיזיולוגיים, פסיכולוגיים וגם רגשיים. הווה אומר, שניתן למדוד פרמטרים פיזיולוגיים מסוימים הקשורים לתסמיני הקורונה, ברמת מהימנות גבוהה, מתוך אותות דיבור של נבדקים. אבחון ובידוד מוקדם ימזערו מאוד את התפשטות הקורונה ובכך יפחיתו את התמותה בקרב נדבקים.
על מנת להוציא לפועל רעיון שכזה, יש צורך לאסוף בו-זמנית הן דגימות דיבור (קרי, הקלטות) של אנשים בריאים וסימפטומטים והן דגימות של פרמטרים גופניים (כגון: טמפרטורת גוף, דופק, לחץ דם, קצב נשימה וכיוצא באלה פרמטרים). כמובן שדגימות הדיבור והפרמטרים הגופניים ישמשו לאימון ושיפור של מודלים של בינה מלאכותית לאבחון תסמיני הקורונה, ברמת מהימנות גבוהה.
לאחר מכן ניתן יהיה לשלב את מודל הבינה המלאכותית המאומן באפליקציה בנייד, כך שההמונים יוכלו להורידה למכשיריהם הניידים ובעשותם כך לנטר את עצמם באופן קבוע ולעקוב אחר תסמיני הקורונה. במצב עולם שכזה, האפליקציה תוכל להרים "דגל אדום" ולהתריע הן למשתמש והן לגורמי הבריאות אם וכאשר יתגלה תסמין כלשהו.
- ספרות מקצועית
אחד השלבים החשובים באבחון הרפואי הוא מדידת סימנים חיוניים או פרמטרים גופניים, כגון: דופק, לחץ דם, טמפרטורת גוף וקצב נשימה. על פי רוב, פרמטרים אלה נמדדים באמצעות מכשירים רפואיים שיכולים להיות יקרים, אותם מכשירים רפואיים דורשים הכשרה רפואית מסוימת על מנת להשתמש בהם ובנוסף אותם מכשירים אינם נגישים או זמינים לכל אחד בכל רגע ובכל מקום. בהנחה שניתן לעשות שימוש בדיבור לטובת מדידת פרמטרים גופניים, אשר מהם ניתן לאתר את תסמיני הקורונה, הרי שניתן יהיה להרחיב את הפונקציונליות של הסמארטפונים, שכיום נגישים וזמינים לכל אחד, לזיהוי תסמיני הקורונה.
הספרות הקיימת, העדויות הקיימות כמו גם הניסיון שנצבר מצביעים, כאמור, על קיומו של מתאם בין מאפייני דיבור לבין מצבים פיזיולוגיים, פסיכולוגיים כמו גם רגשיים.
Reynolds and Paivio (1968), Wall and Stone (1974), Ramig (1983) וכן Trouvain and Truong (2015) מתארים כיצד מאפייני הדיבור משתנים כתוצאה ממצבים פיזיולוגיים ורגשיים.
Orlikoff and Baken (1989), Burton, Stokes and Hall (2004), Schuller, Friedmann and Eyben (2014), Sakai (2015), James (2015) וכן Usman (2017) מצאו עדויות למתאם בין דופק לדיבור ומדדו את הדופק מתוך הדיבור באמצעות יישום טכניקות שונות של עיבוד אותות ואלגוריתמים של בינה מלאכותית.
Usman, Zubair, Ahmed et.al (2019) בנו פעם אחת מודל רגרסיה לחיזוי דופק ופעם שניה מודל סיווג לאבחון דופק לאחת מ- 2 קטגוריות: "רגיל" ו- "לא תקין". על ידי בחירת אלגוריתם הבינה המלאכותית המתאים (Model selection) ושיפור הניבוי באמצעות כוונון היפר הפרמטרים (Hyperparameter optimization) החוקרים הגיעו לרמת מהימנות (Accuracy) של 94% במודל הרגרסיה ולרמת מהימנות של 100% במודל הסיווג.
Skopin and Baglikov (2009) וכן Mesleh, Skopin, Baglikov and Quteishat (2012) מצאו מתאם בין דיבור לבדיקת אק"ג.
Sakai (2015) מצא מתאם גבוה בין לחץ דם לדיבור.
אחת העדויות הנפוצות היא שניתן לזהות עייפות בדיבור של הפרט הבודד. לפיכך, ישנן עדויות חזקות בספרות המקצועית המצביעות על קיומו של מתאם בין דיבור למספר פרמטרים ביולוגיים. חשוב לציין כי פרמטרים ביולוגיים אלה קשורים לתסמיני הקורונה ועל כן ניתן לעשות בהם שימוש לאבחון תסמיני הקורונה.
Meckel, Rotstein, and Inbar (2002) מתארים את תהליך הפקת הדיבור, ככזה הכולל תנועת אוויר מהריאות דרך מסלול הקול בו זמנית עם עיצוב של מסלול הקול לצורך הפקת צלילי דיבור שונים.
Von Euler (1981) וכן Kevin and Christopher (2003) מתארים את הקשר שבין דפוס הנשימה לדיבור.
Yasuma and Hayano (2004) דנים בהשפעה שיש להשתנות דפוס הנשימה על הדופק, מה שמכונה בספרות "סינוס הפרעת קצב-לב נשימתית" (RSA – Respiratory Sinus Arrhythmia).
- עיבוד אותות ובינה מלאכותית
ברגיל, אות דיבור מוקלט, שמצוי בפורמט דיגיטלי, עובר עיבוד מקדים לצורך הסרת רכיבים לא רצויים, כגון: סינון רעשי רקע והשמטת מרווחי שתיקה/פאוזות באמצעות טכניקות לעיבוד אותות כגון סינון וזיהוי פעילות קולית (VAD- Voice Activity Detection).
Wolf (1980) מסביר שלאחר שאות הדיבור עבר את העיבוד המקדים, שתואר לעיל, עליו לעבור עיבוד נוסף באמצעות אלגוריתמים שמטרתם לחלץ מתוכו מאפיינים (קרי, משתנים מסבירים) המגדירים אותו. מאפיינים אלו, מסביר החוקר, משמשים כמשתני כניסה באלגוריתמים של בינה מלאכותית, אשר בתורם מזהים "תבנית" או פרמטר פנימי (Intrinsic) כלשהו השייך לתבנית.
כך למשל, הפרמטר הפנימי יכול להיות למשל פרמטר גופני המשמש כסמן לאחד או יותר מתסמיני הקורונה.
- יתרונות פוטנציאליים
השימוש בדיבור לאבחון תסמיני קורונה הינו אטרקטיבי במיוחד נוכח המצב הנוכחי הואיל ומדינות רבות מתמודדות עם מחסור בערכות בדיקת מטוש. על כן, קיימת החובה להשתמש בערכות בדיקת המטוש הזמינות בשום שכל. מכיוון שקיימת אפשרות לזהות תסמינים בשלב מוקדם באמצעות זיהוי קולי, הרי שאנשים יכולים להכניס את עצמם לבידוד באופן מיידי כאמצעי זהירות ובכך למזער את האפשרות שלהם להדביק אחרים בטרם נבדקו בבדיקת מטוש – כאן כבר מדובר בתמיכה רפואית נוספת.
לאחר פיתוח אלגוריתם לזיהוי קולי של נשאי קורונה, לא יהיה עוד צורך במכשירים רפואיים מיוחדים. ניתן יהיה פשוט לאסוף את המידע (הקלטות דיבור במקרה דנן שלפנינו) באמצעות מיקרופון שזמין כיום בכל מכשיר נייד ולנתחו באמצעות 'אפליקציה'. במידה ויתגלו תסמינים כלשהם, ניתן להגדיר שהאפליקציה תתריע על כך הן בפני המשתמש והן בפני רשויות הבריאות הרלוונטיות.
את האבחון הראשוני לתסמינים החשודים כקורונה ניתן יהיה לבצע מרחוק, הואיל וניתן לאסוף אותות דיבור באמצעות הטלפון. למעשה, ניתן יהיה לאתר ולזהות אנומליות בפרמטרים הביולוגיים הרבה לפני שתסמיני הקורונה ניכרים. אבחון בקנה מידה גדול יתאפשר בעלות נמוכה וללא מכשירים רפואיים מורכבים או יקרים. ריבוי הסמארטפונים וזמינותם לכל אחד בכל מקום ובכל רגע מאפשרים להוציא לפועל את אפליקציית האבחון תוך זמן קצר, ברגע שמודלי הבינה המלאכותית יאומנו, יתוקפו וישולבו באפליקציה – מה שהופך את האפשרות לאבחון עצמי בזמן אמת לכל מי שיש לו סמארטפון לולידית ואפליקבילית.
- אתגרים
אמנם הרעיון של אבחון תסמיני קורונה מתוך דיבור הינו מבטיח וכולל בחובו מספר יתרונות, אך עם זאת הוא טומן בחובו גם אתגרים – אך לא כאלו שלא ניתן להתגבר עליהם. האתגר העיקרי הוא להשיג דגימות דיבור ופרמטרים פיזיולוגיים של אנשים בריאים כמו גם של חולי קורונה ונשאי קורונה. לשם כך, יש ליצור מערכי נתונים של דיבור המתאימים לפרמטרים אחרים הקשורים לתסמיני הקורונה.
כמו כן, חובה שהפרמטרים הפיזיולוגיים ילקחו במקביל לזמן הקלטת הדיבור. נתונים אלה נחוצים לאימון אלגוריתמים של בינה מלאכותית. חשוב לציין כי ככל שמספר הדגימות שניתן לאסוף יהיה גדול יותר, כך מודל הבינה המלאכותית שנאמן יהיה טוב יותר לצורך אבחון קורונה. אתגר נוסף הוא להקטין את הסיכוי ל"אזעקות שווא" מכיוון שהן עלולות לגרום לבהלה וללחץ בקרב אנשים שנמצאים גם ככה במצב רגשי רעוע בעקבות המגפה.
Schuller, Schuller, Qian, et.al (2020) טוענים כי הואיל ואלגוריתמים של בינה מלאכותית אינם מדויקים ב- 100% הרי שחשוב לתווך למשתמשי הקצה את את מדדי השגיאה של אותם אלגוריתמים (כמו למשל אחוז הטעות הצפוי או רמת המובהקות).
- סיכום
אותות הדיבור כוללים בחובם מידע מהותי בנוגע למצבים פיזיולוגיים, פסיכולוגיים וגם רגשיים של הדובר. על כן יתכן שניתן למדוד מאפיינים ביולוגיים שכאלה מתוך דיבור.
מדידה מדויקת של פרמטרים פיזיולוגיים שכאלה באמצעות אותות דיבור עשויה להקל על איבחון מרחוק ובזמן אמת של נשאי וחולי קורונה כמו גם גילוי מוקדם של תסמיני הקורונה וכפועל יוצא מכך לקטוע את התפשטות המגיפה. איבחון קורונה באמצעות זיהוי קולי יקנה לחברות, למדינות ולאנושות כולה זמן יקר עד לגמר חיסון אוכלוסיית העולם כולה נגד קורונה ובאותו זמן יקטין את שיעור התמותה מהמחלה.
מכיוון שטכניקות של בינה מלאכותית מצליחות להניב רמת מהימנות גבוהה יחסית – הרי שכניסתם של אלגוריתמים של למידה עמוקה, הופך את השימוש בדיבור למדידת פרמטרים פיזיולוגיים ליותר ויותר אפשרי יותר – ואיזה זמן טוב יותר לעשות שימוש ברעיון מבטיח שכזה מאשר בזמן של מגפת עולמית.
לסיכום, מטרתי הסופית היא להגיע למצב שניתן יהיה לאבחן נשאי קורונה א-סימפטומטים באמצעות ניתוח הקול והדיבור שלהם בלבד באמצעות שימוש באפליקציה ייעודית על הסמארטפון (קרי, כלי זמין, נוח ופשוט לאבחון מהיר ולא פולשני של הנגיף – מה שבתורו יביא לתעדוף הבדיקות ולקטיעת שרשרת ההדבקה).
אני כיום מצוי בתהליך של מחקר פורץ דרך לאבחון נשאי קורונה א-סימטפומטים באמצעות עיבוד מאפייני הדיבור והקול של נבדקים בבדיקת מטוש ולשם כך אני מעוניין בשיתוף פעולה עם בית חולים או קופת החולים שמסוגלים לאסוף דגימות קול ודיבור (הקלטות) מנבדקים בזמן בדיקות המטוש, במטרה לייצר בסיס נתונים שישמש את המחקר.
בשעה שיהיה בידי בסיס נתונים רחב יותר, הרי שאוכל לעבד את המידע במגוון כלים, טכניקות מתקדמות לעיבוד דיבור כמו Deep Learning כחלק מאלגוריתמים של בינה מלאכותית, כאשר המטרה שלי היא לבנות מודל סטטיסטי שיודע לסווג דיבור וקול של נבדק בבדיקת מטוש לאחת מ- 2 קטגוריות: "חיובי לקורונה" ו- "לא חיובי לקורונה".

"רועי פולניצר – פרדיקציות יועצים" הינו משרד ייעוץ סטטיסטי המספק פתרונות מדעיים לאתגרים הכרוכים בעבודה עם כמויות גדולות ומגוונות של נתונים, ביצוע מחקרים לשם הפקת תובנות עסקיות מנתונים (BI- Business Intelligence), ניקוי, טיוב וסידור מידע המשמש למחקרים, הפעלת אלגוריתמים ומודלים שונים של Machine Learning ,Data Mining ו- Deep Learning על מידע המשמש למחקרים וסיוע בבניית תהליכי הכנת המידע והאופטימיזציה של המודלים והאלגוריתמים השונים.
המשרד מתמחה בתרגום דרישות עסקיות לפתרונות טכניים ואנליטיים מעשיים באמצעות פיתוח מודלים סטטיסטיים ואלגוריתמים מתמטיים שמטרתם לספק מענה לבעיות עסקיות מורכבות בתחומי השיווק, המכירות, ה- Cyber, התפעול, הרגולציה ועוד – החל משלב בחירת הגישה האנליטית ופיתוח הפתרון האלגוריתמי ועד לשלב בחינת איכות תוצרי המודלים אל מול ה- KPI שהוגדרו ע"י הלקוח.

הבעלים ומדען הנתונים האחראי מטעם המשרד, האקטואר רועי פולניצר מוסמך כמדען נתונים מקצועי (PDS) מטעם האיגוד הישראלי למדעני נתונים מקצועיים (PDSIA) ומשמש כמנכ"ל האיגוד. מוסמך כאקטואר מלא (Fellow) מטעם לשכת מעריכי השווי והאקטוארים הפיננסיים בישראל (IAVFA) ומשמש כיו"ר הלשכה. מוסמך כמנהל סיכונים פיננסיים (FRM) מטעם האיגוד העולמי למומחי סיכונים ומנהל סיכונים מוסמך (CRM) על-ידי האיגוד הישראלי למנהלי סיכונים (IARM) בוגר תוכנית הכשרה של דאטה סיינטיסט (Data Science, Machine Learning, and Deep Learning with Python) בת 500 שעות של מכללת ג'ון ברייס וזכה במקום הראשון (First Place Award) בתחרות הדאטה סיינטיסטים (Maximum F1-Score Challenge) של מכללת ג'ון ברייס. בוגר תוכנית הכשרה בניהול סיכונים, מדע נתונים ולמידת מכונה בת 250 שעות של אוניברסיטת אריאל בשומרון ולמד בתוכנית ללימודי תעודה באקטואריה באוניברסיטת חיפה. בעל תואר ראשון ותואר שני שניהם מאוניברסיטת בן גוריון, שניהם בהצטיינות ושניהם במסלול DATA (עם התמחות במדע נתונים ולמידת מכונה). בעברו שימש רועי כעוזר מחקר של ד"ר שילה ליפשיץ ז"ל בתחומים של אנליזות מתקדמות ופיתוחי מודלים.
רועי פולניצר הינו אקטואר העוסק מזה כ-15 שנים בתחומי הנתונים, האלגוריתמיקה, והבינה המלאכותית – הן ברמה האקדמית והן ברמה הפרקטית (בתעשייה). בעשור וחצי האחרון, מר פולניצר ביצע פרוייקטים רבים הכוללים תכנות ב- R, Python, PySpark, VBA ובניית מערכות סימולציה מורכבות סימולציה מורכבות בסביבת מונטה קרלו לחיזוי ובניית מערך תרחישים, עבודה עם בסיס נתונים וניתוח מידע בשפת SQL, מדע נתונים, ביצוע מחקרי מדעי/יישון שיטות מחקר, סטטיסטיקה תיאורית, הסתברות, הסקה סטטיסטית, סטטיסטיקה א-פרמטרית, למידה סטטיסטית, מודלים של למידה בהשגחה (Supervised Learning), מודלים למידה ללא השגחה (Unsupervised Learning), צמצום מימדים (Dimensionality reduction), תיקוף מודלים (תנועה בראונית, ניתוח סדרות עתיות, שימוש בשיטות מונטה קרלו, קירוב סדרות נתונים להתפלגויות אנליטיות, רגרסיה לוגיסטית ומודלים ליניאריים), הכנת נתונים, בניית מודלי ניבוי, Applied Machine Learning (בניית מערכות המלצה, זיהוי אנומליות ועיבוד שפה טבעית וניתוח טקסט NLP), בניית רשתות נוירונים ו- Applications של למידת עמוקה (עיבוד תמונה, זיהוי תמונות, זיהוי פנים, עיבוד קול, זיהוי קולות, זיהוי דיבור, בדיקת דמיון בין טקסטים וכו'), עבודה עם מאגרי מידע גדולים בסביבת Big Data, עבודה עם כלים ותשתיות Data בענן, הטמעת יישומים במערכת הייצור (Deployment, כולל QA של היישומים) וכתיבת פרוטוקול מחקר.
בנוסף, מר פולניצר פרסם מאמרים מקצועיים בתחומים של מדע נתונים, למידת המכונה ולמידה עמוקה ומחקרים אמפיריים כאמרים אקדמיים בכתבי עת שפיטים, שימש בעבר וגם משמש בהווה עד מומחה מטעם בתי משפט ובתי דין בנושא של פיתוח, יישום ותיקוף מודלים סטטיסטיים/אקונומטריים ומימוניים/אקטואריים והתמודד על תפקיד האקטואר הראשי במשרד האוצר, תוך מעבר בהצלחה של כל שלבי המכרז עד לשלב האחרון בהליך (הוא שלב ועדת הבוחנים).
מגזין "סטטוס" מופק ע"י:
Tags: אקטואריה בינה מלאכותית הערכת שווי קורונה


